Abstract
We present Schrödinger Bridge Mamba (SBM), a novel model for efficient speech enhancement by integrating the Schrödinger Bridge (SB) training paradigm and the Mamba architecture. Experiments of joint denoising and dereverberation tasks demonstrate SBM outperforms strong generative and discriminative methods on multiple metrics with only one step of inference while achieving a competitive real-time factor for streaming feasibility. Ablation studies reveal that the SB paradigm consistently yields improved performance across diverse architectures over conventional mapping. Furthermore, Mamba exhibits a stronger performance under the SB paradigm compared to Multi-Head Self-Attention (MHSA) and Long Short-Term Memory (LSTM) backbones. These findings highlight the synergy between the Mamba architecture and the SB trajectory-based training, providing a high-quality solution for real-world speech enhancement.
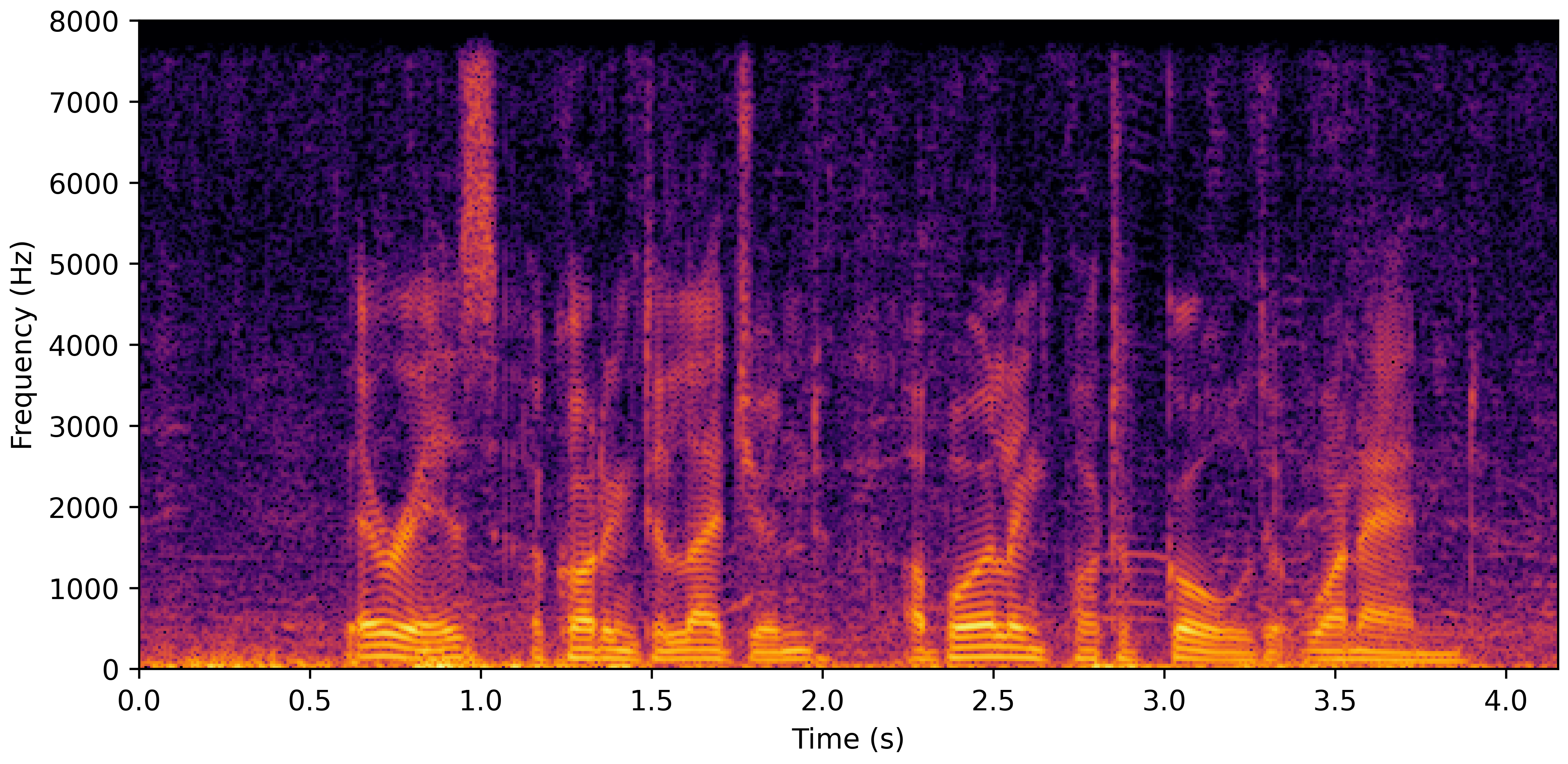
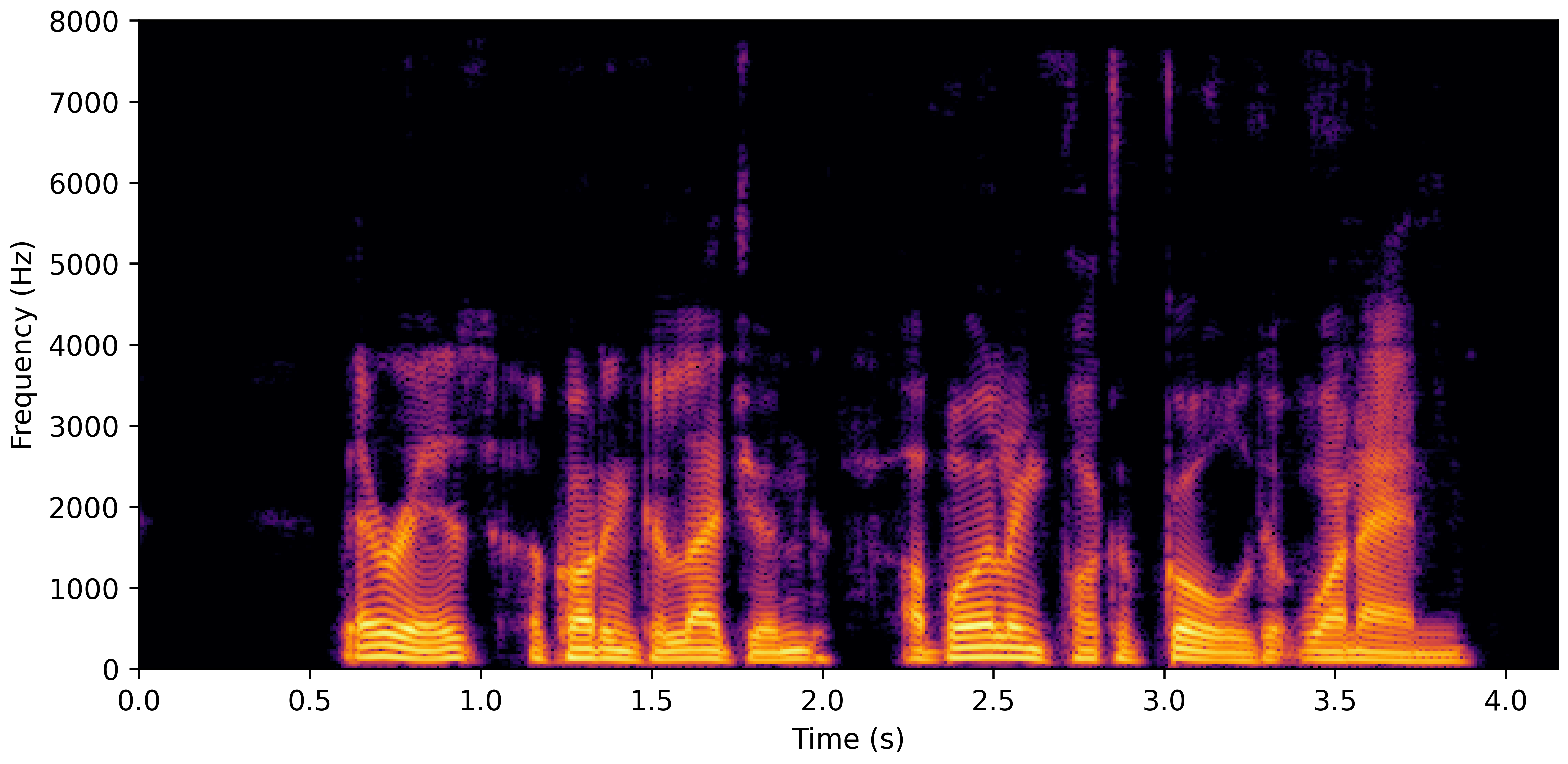
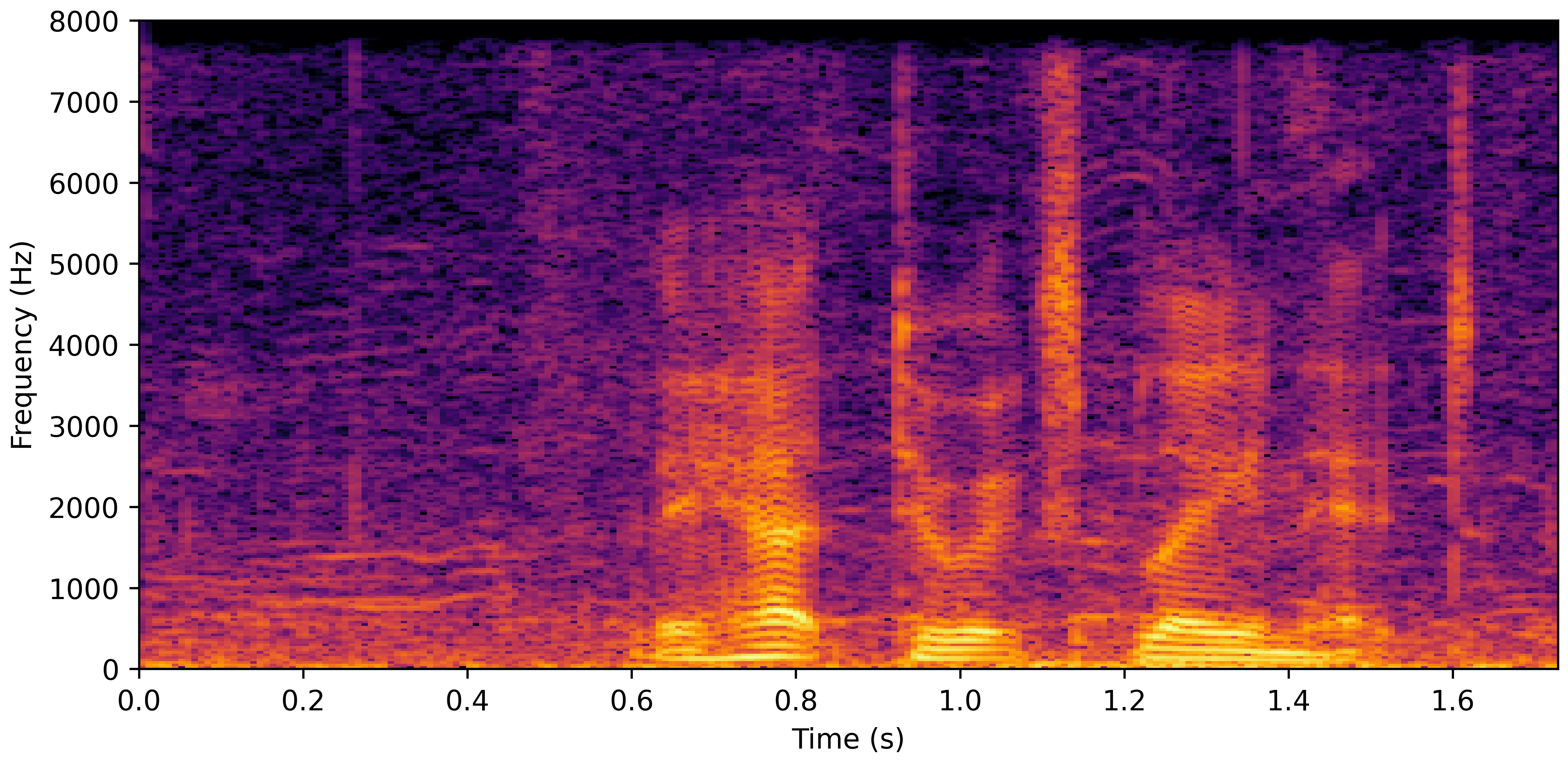
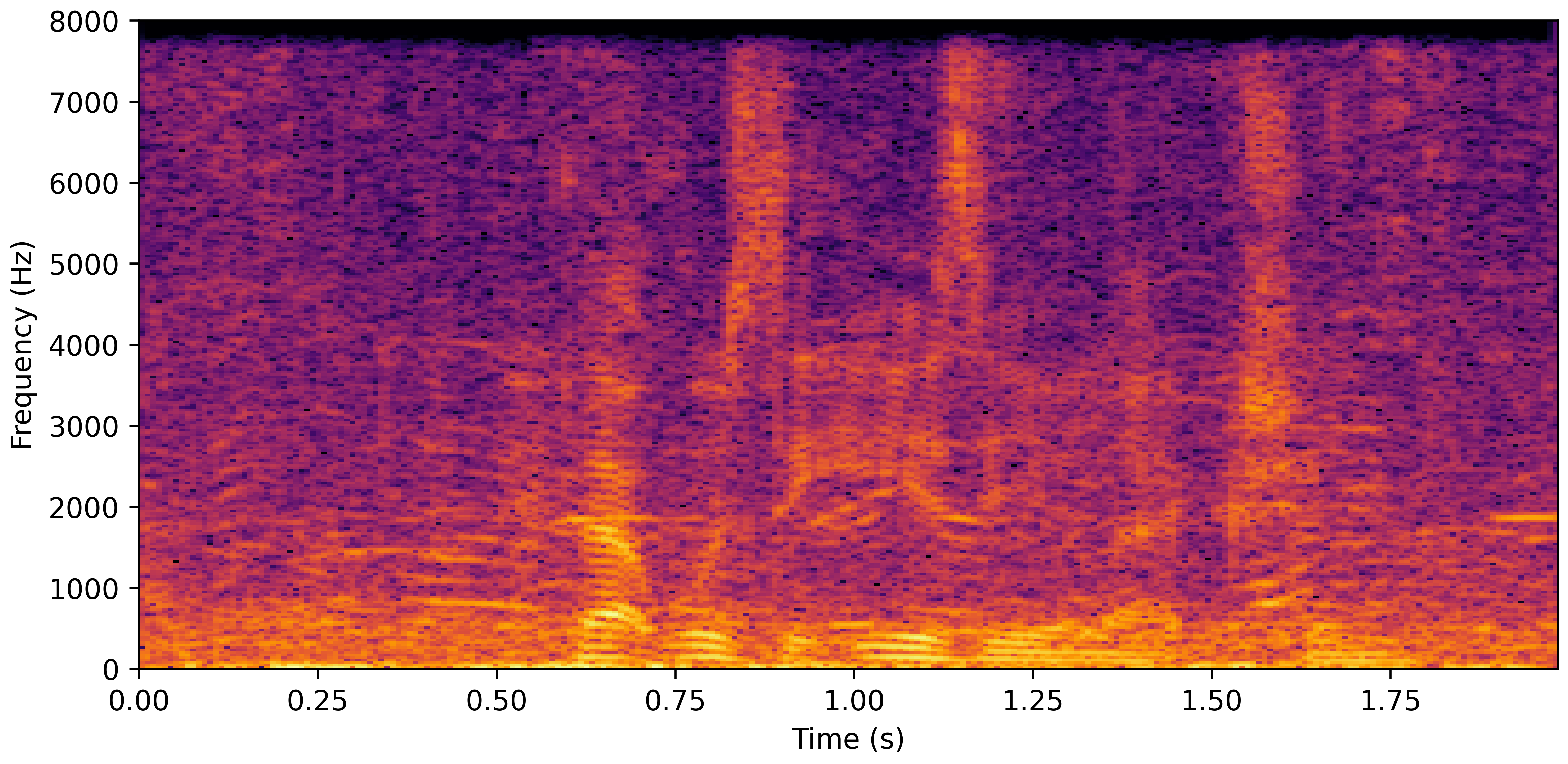
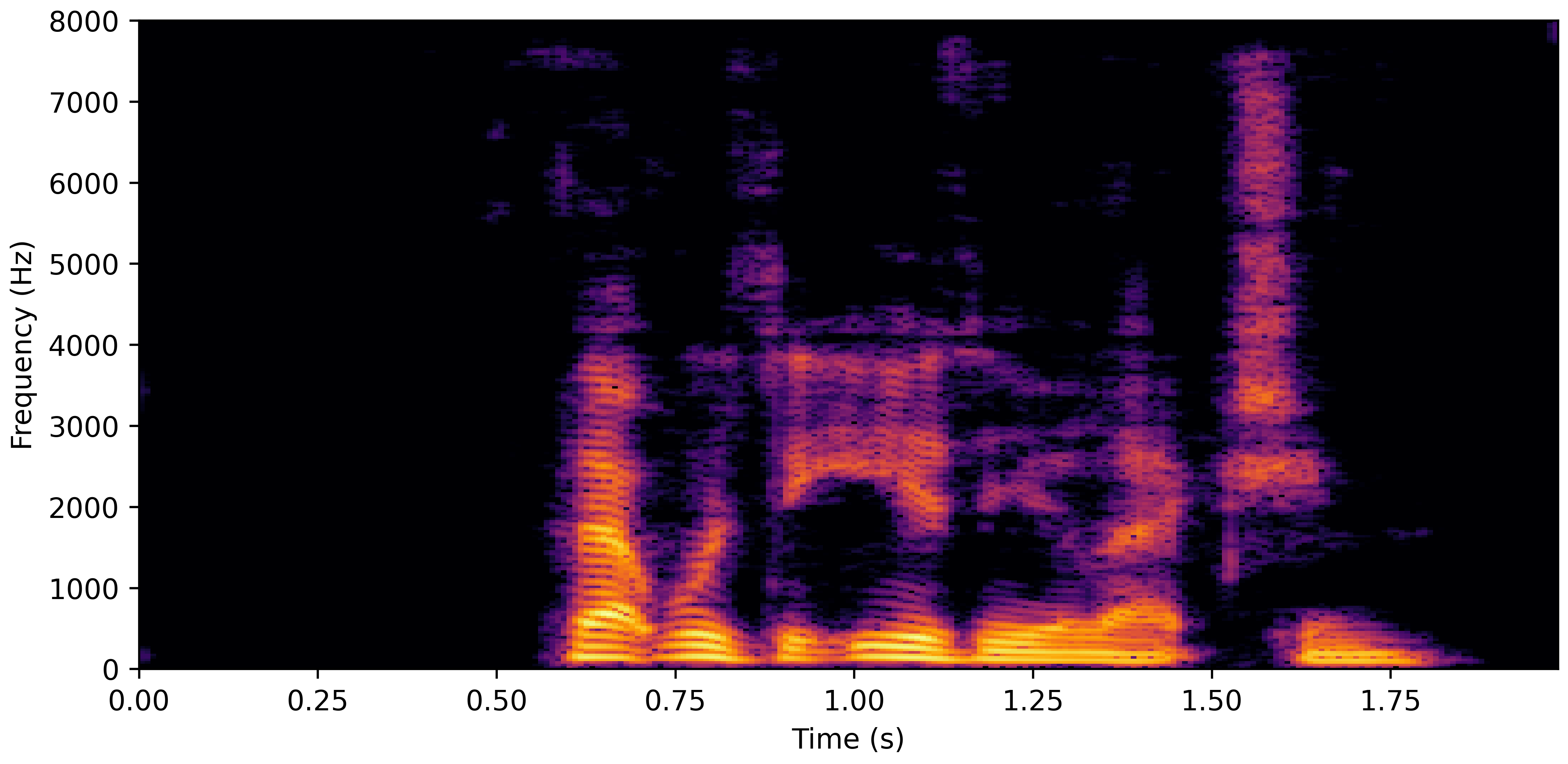
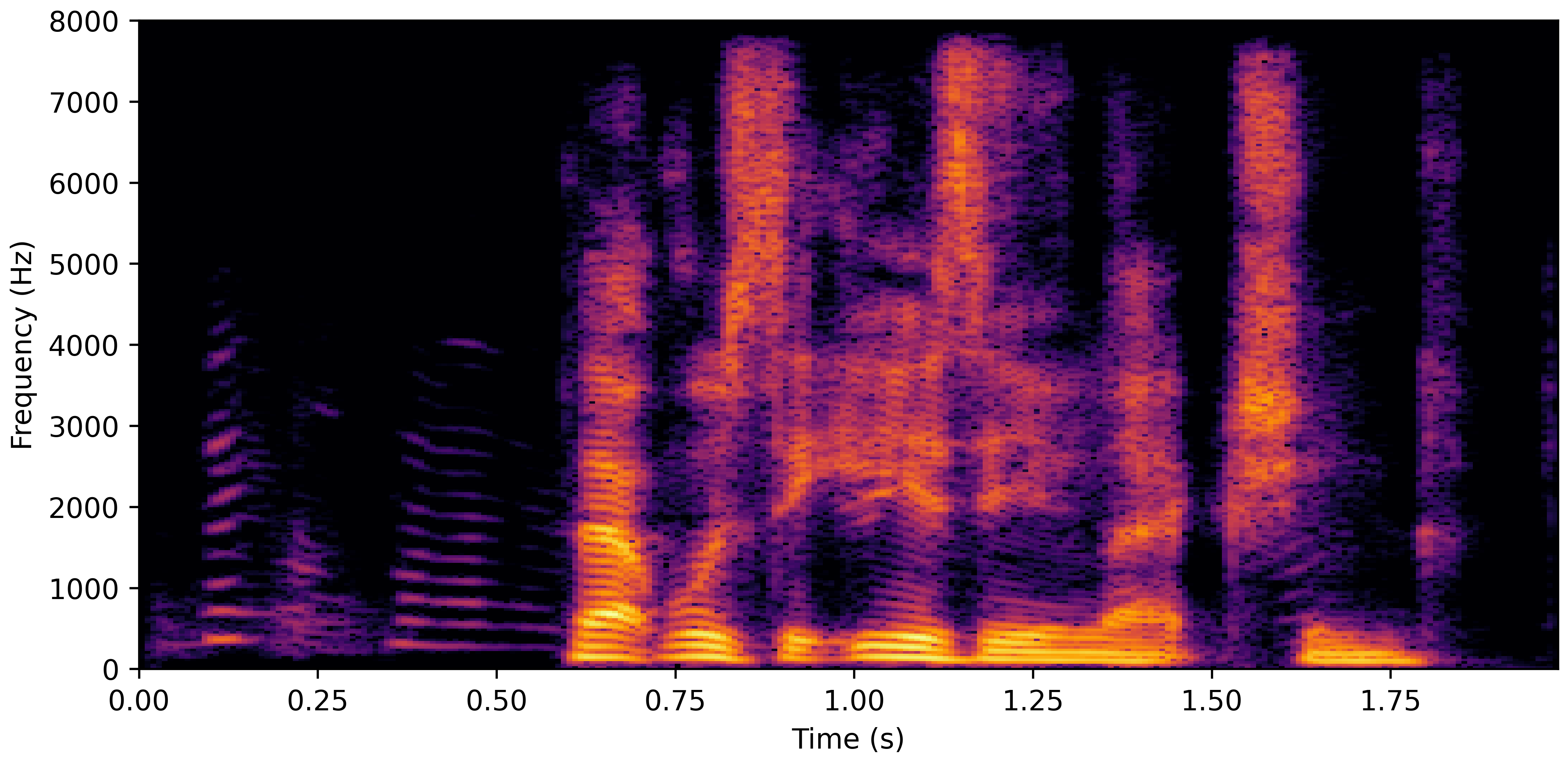
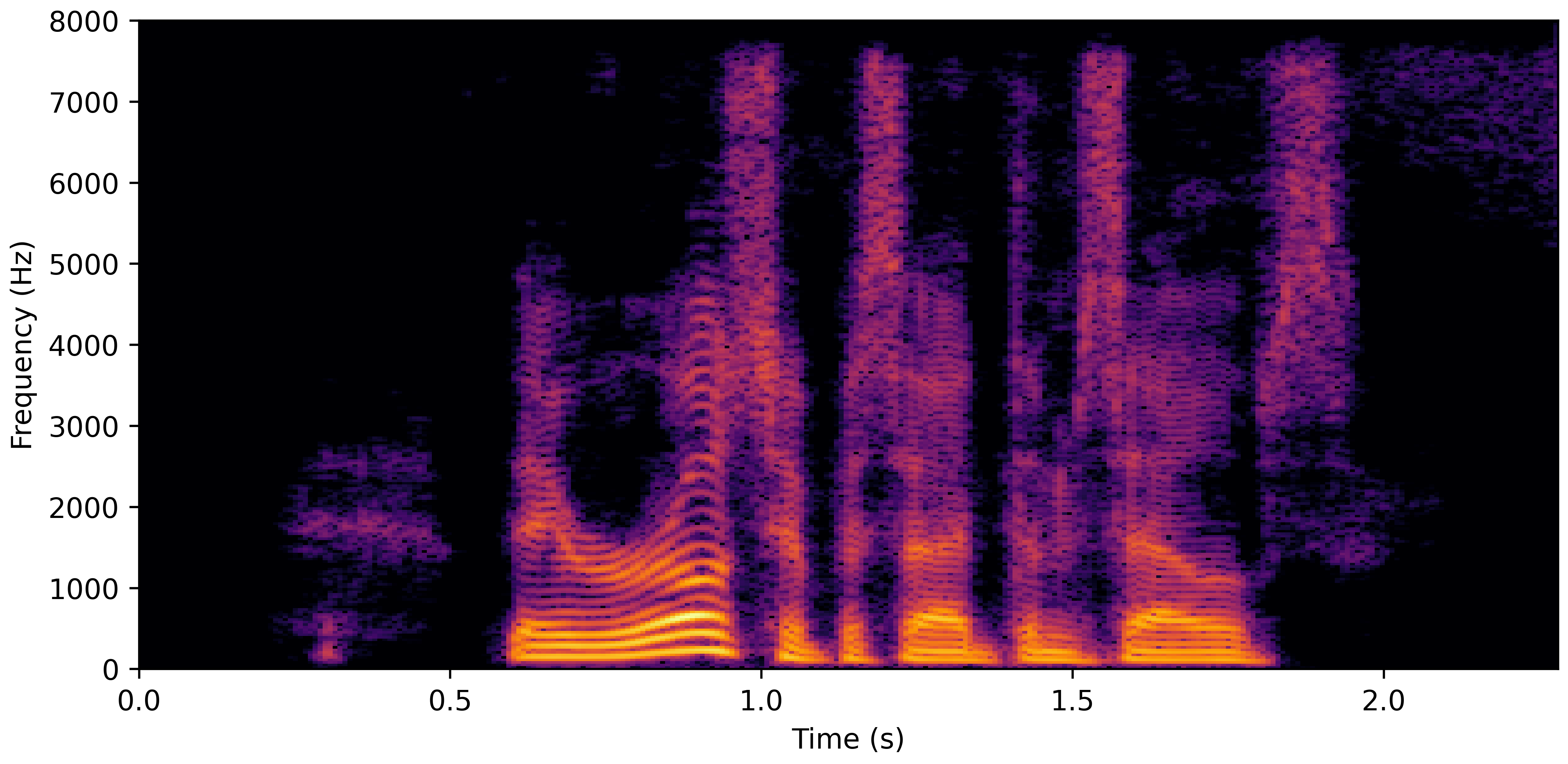
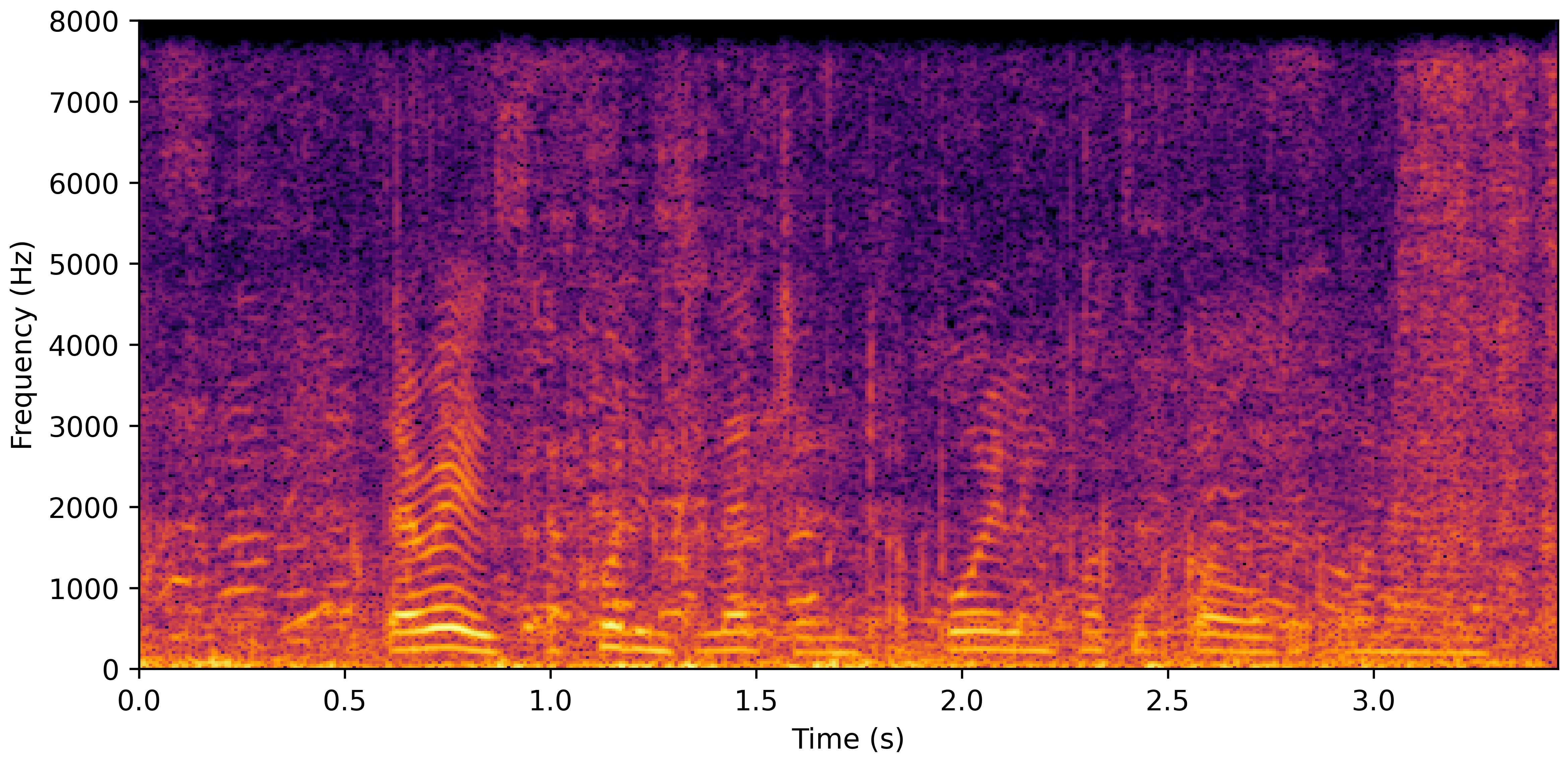
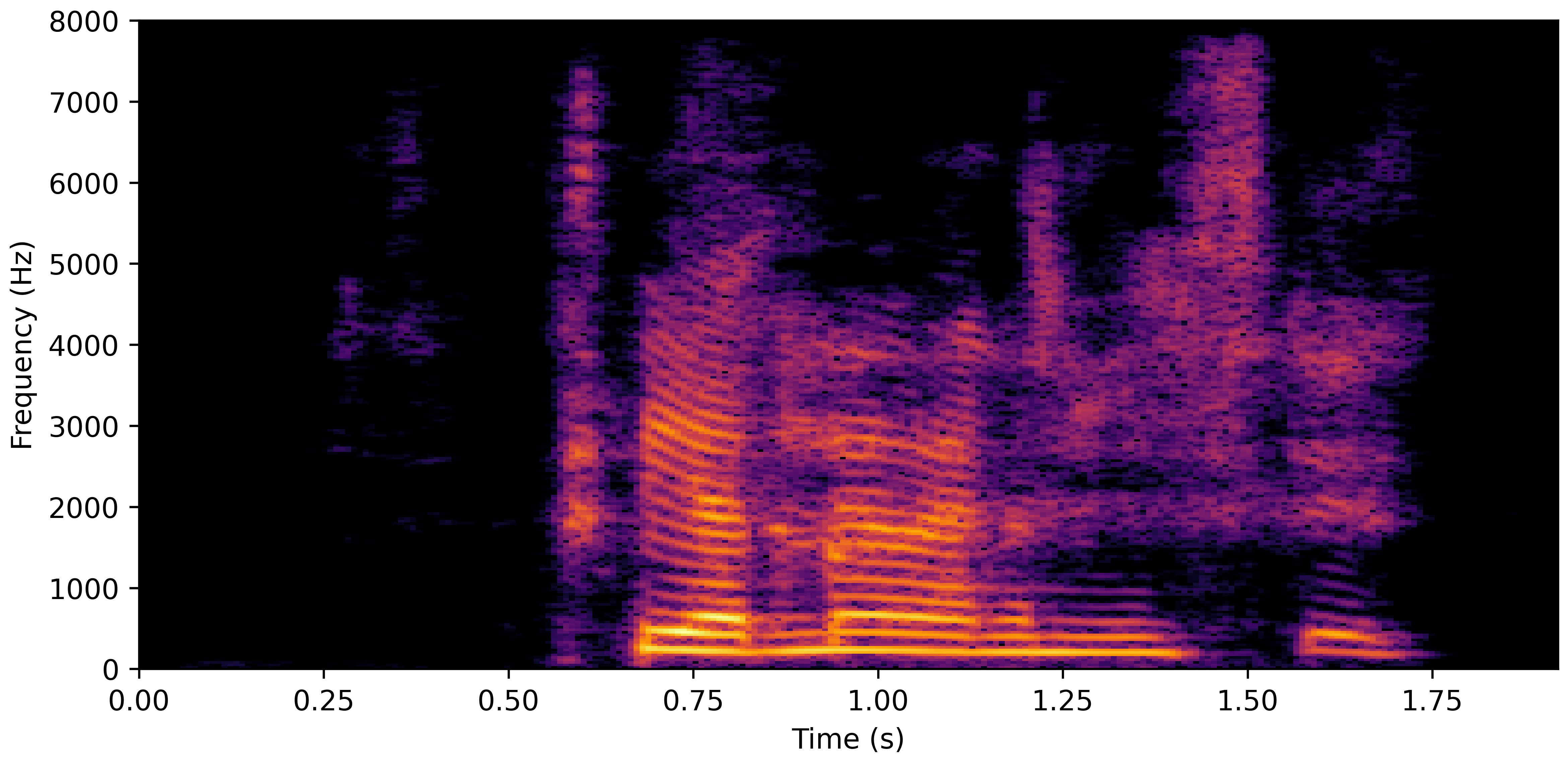
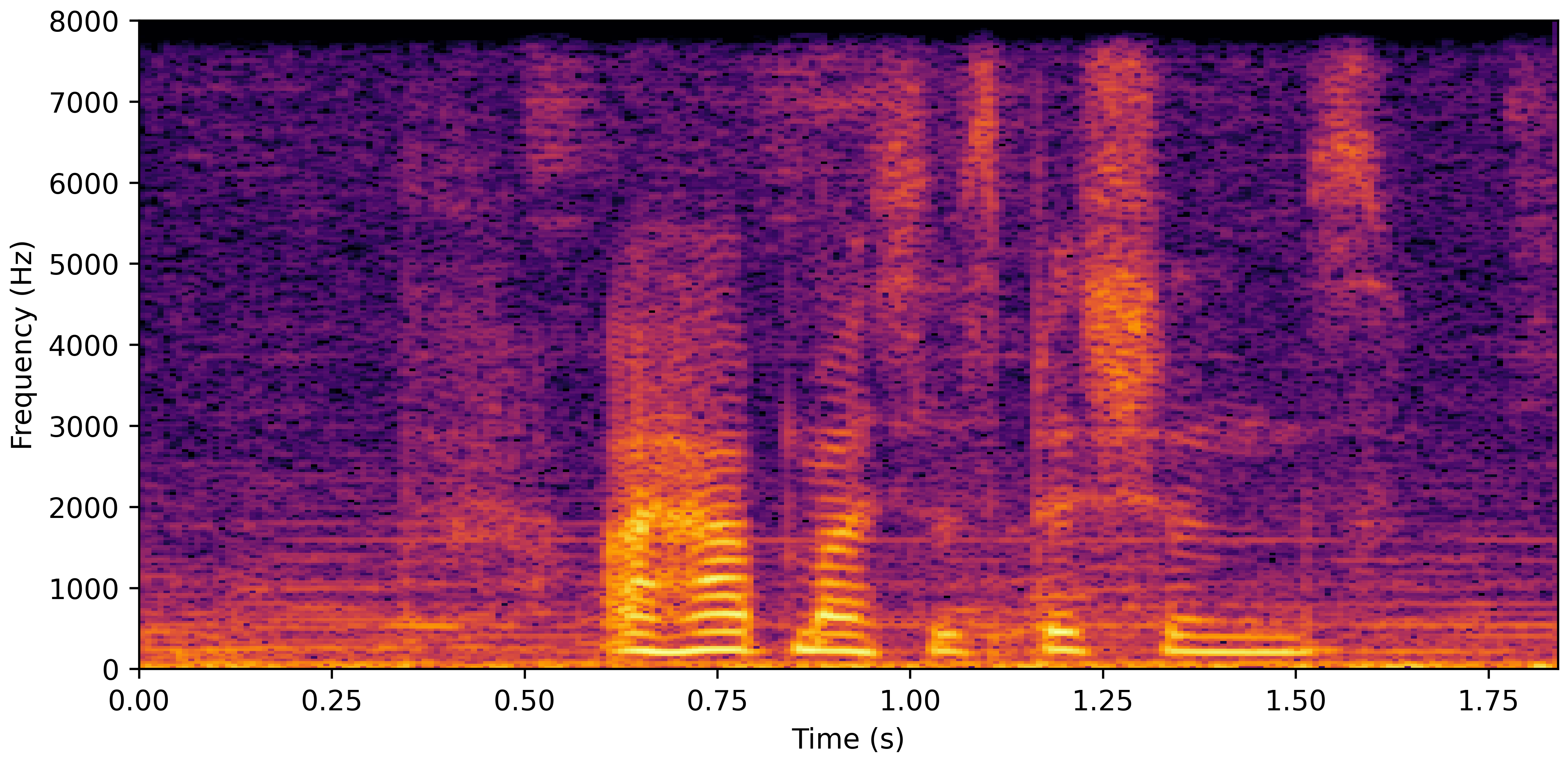
DNS Real Recordings
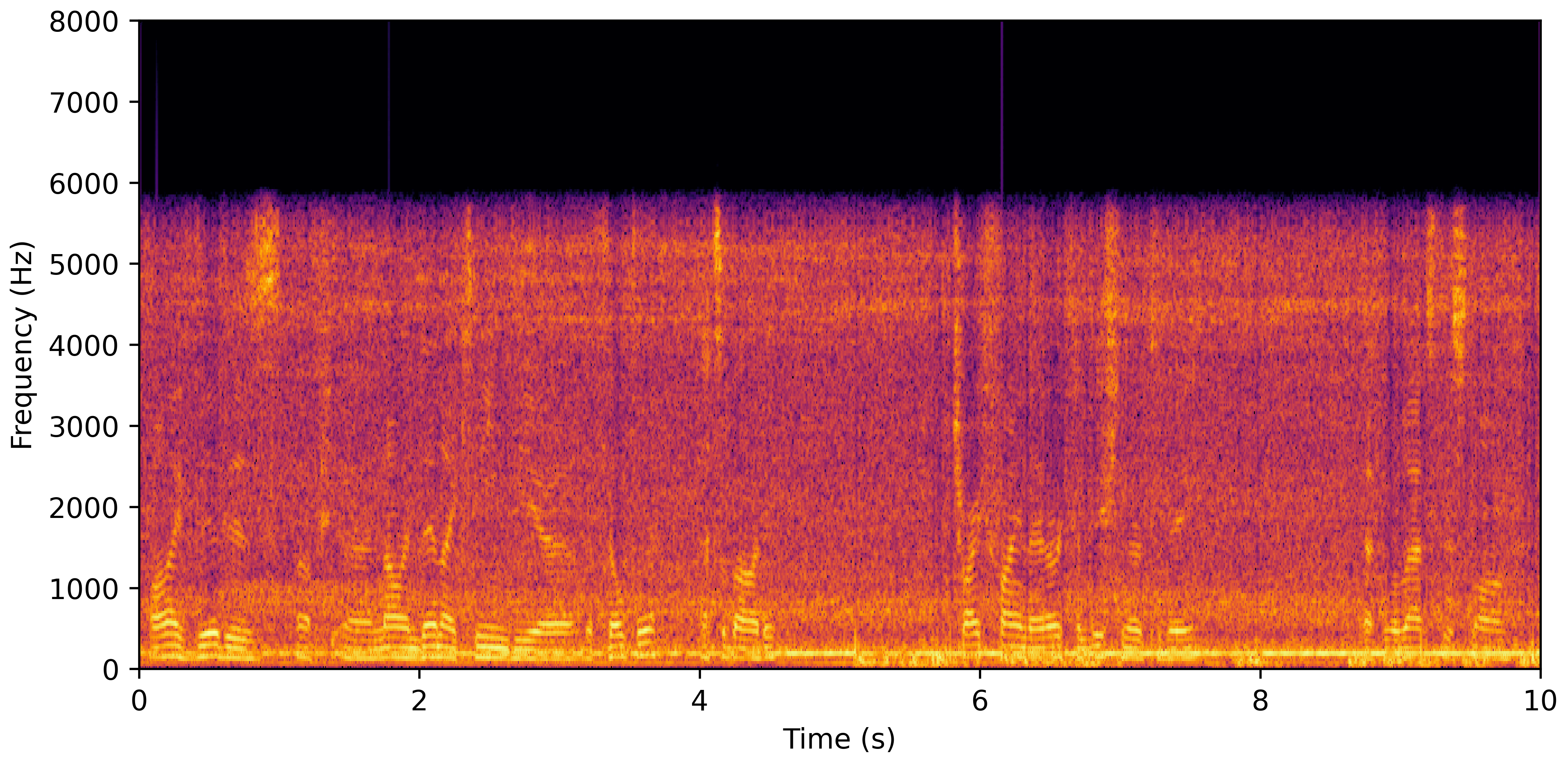
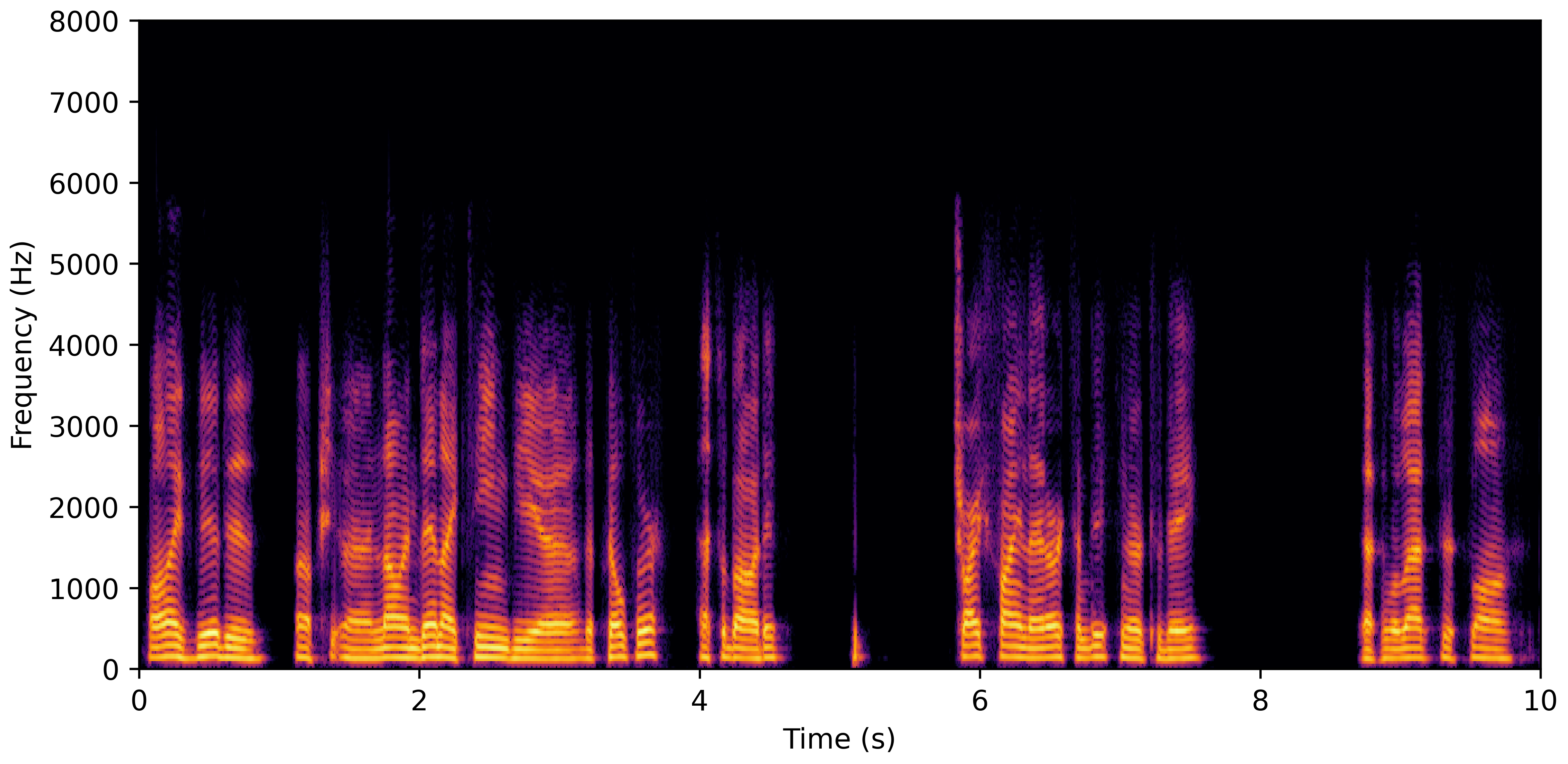
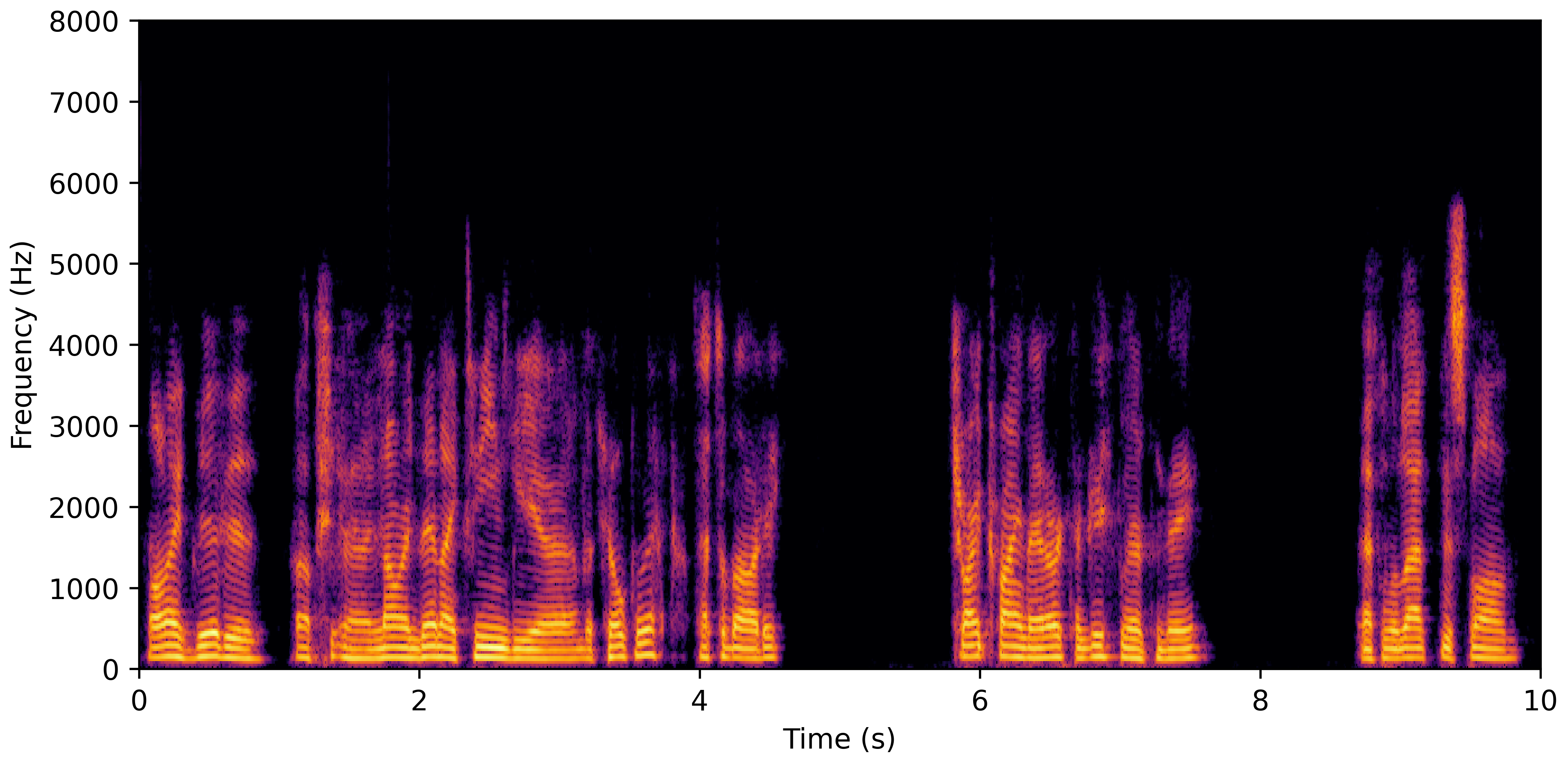
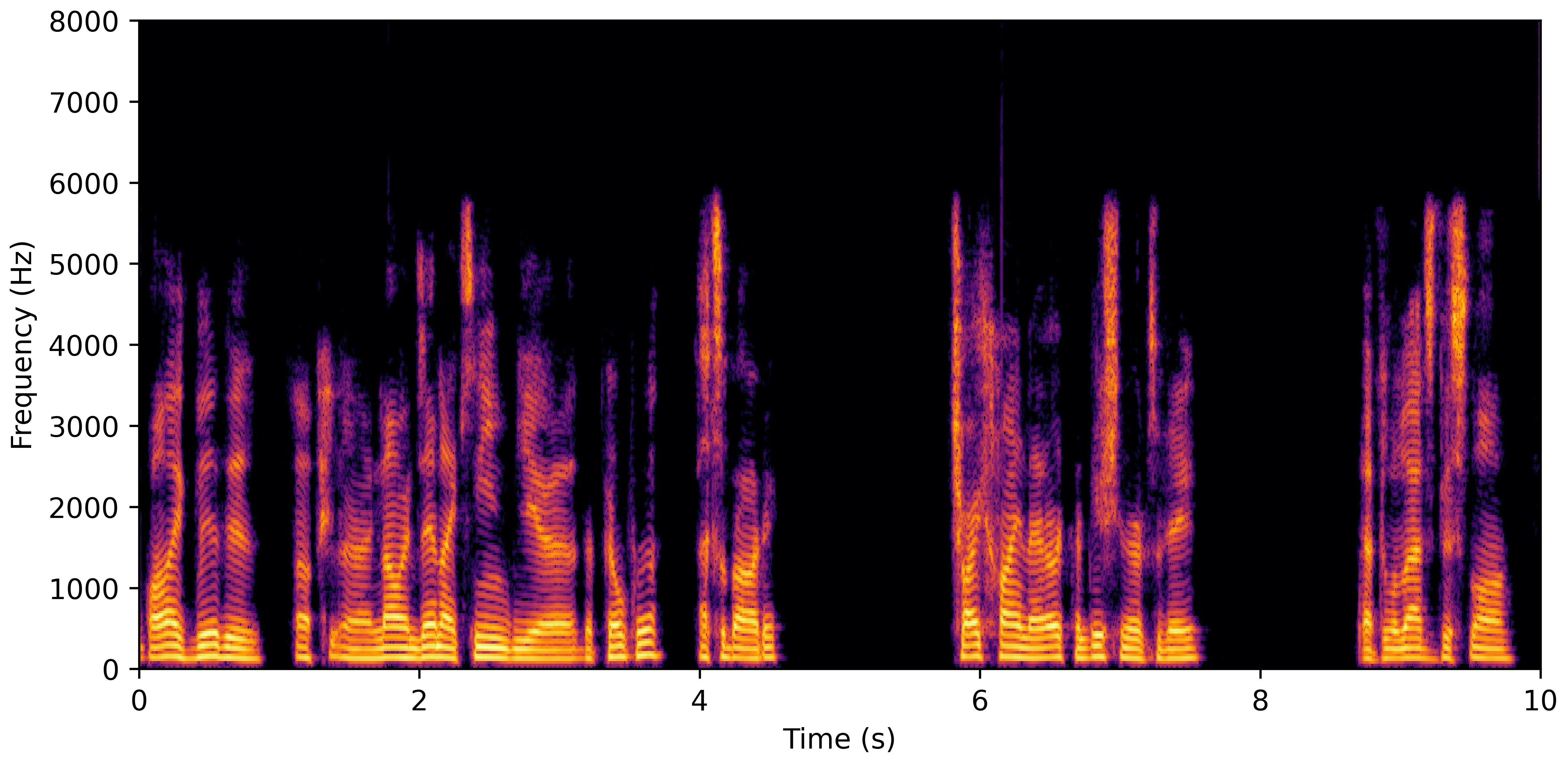
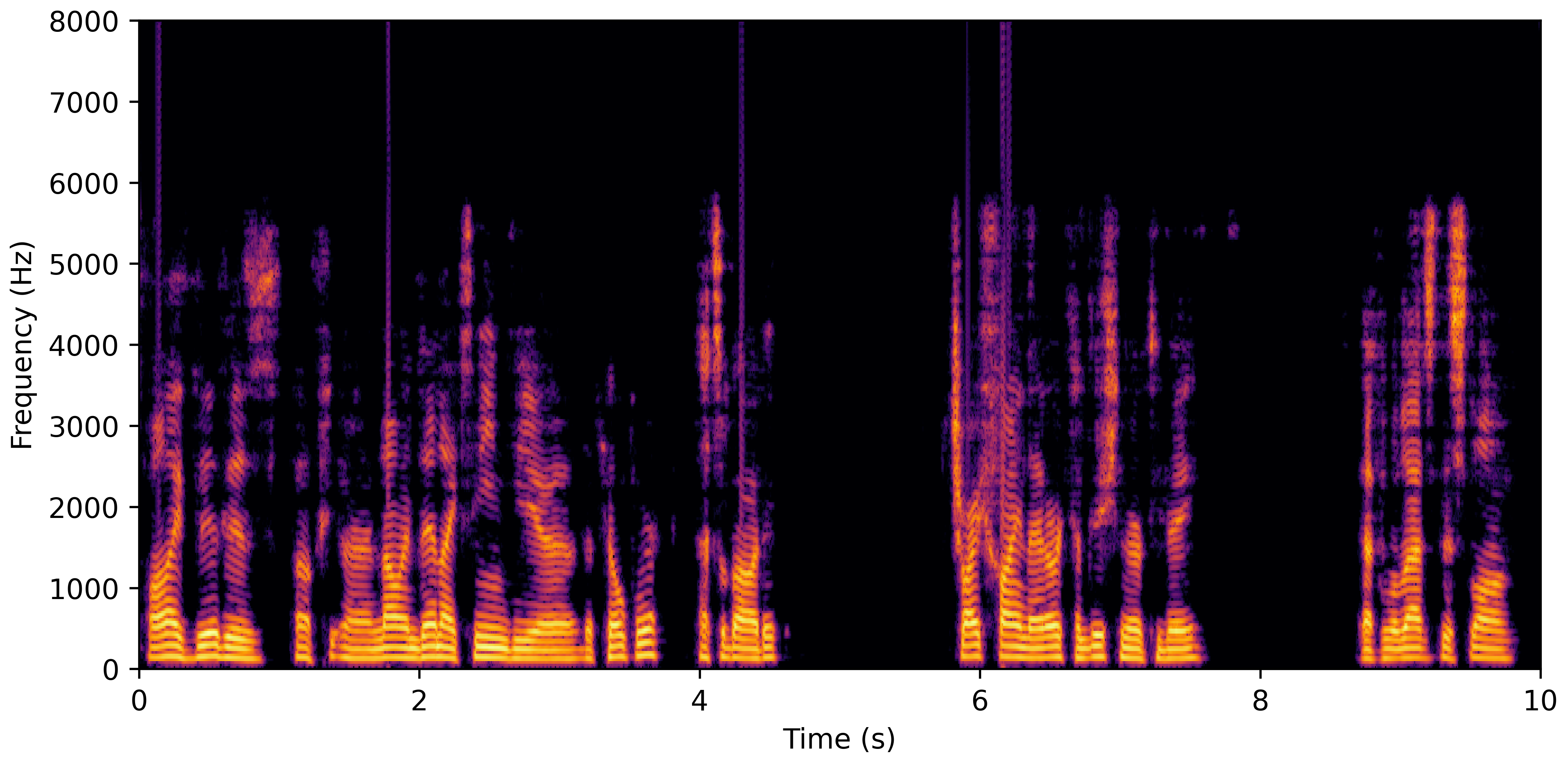
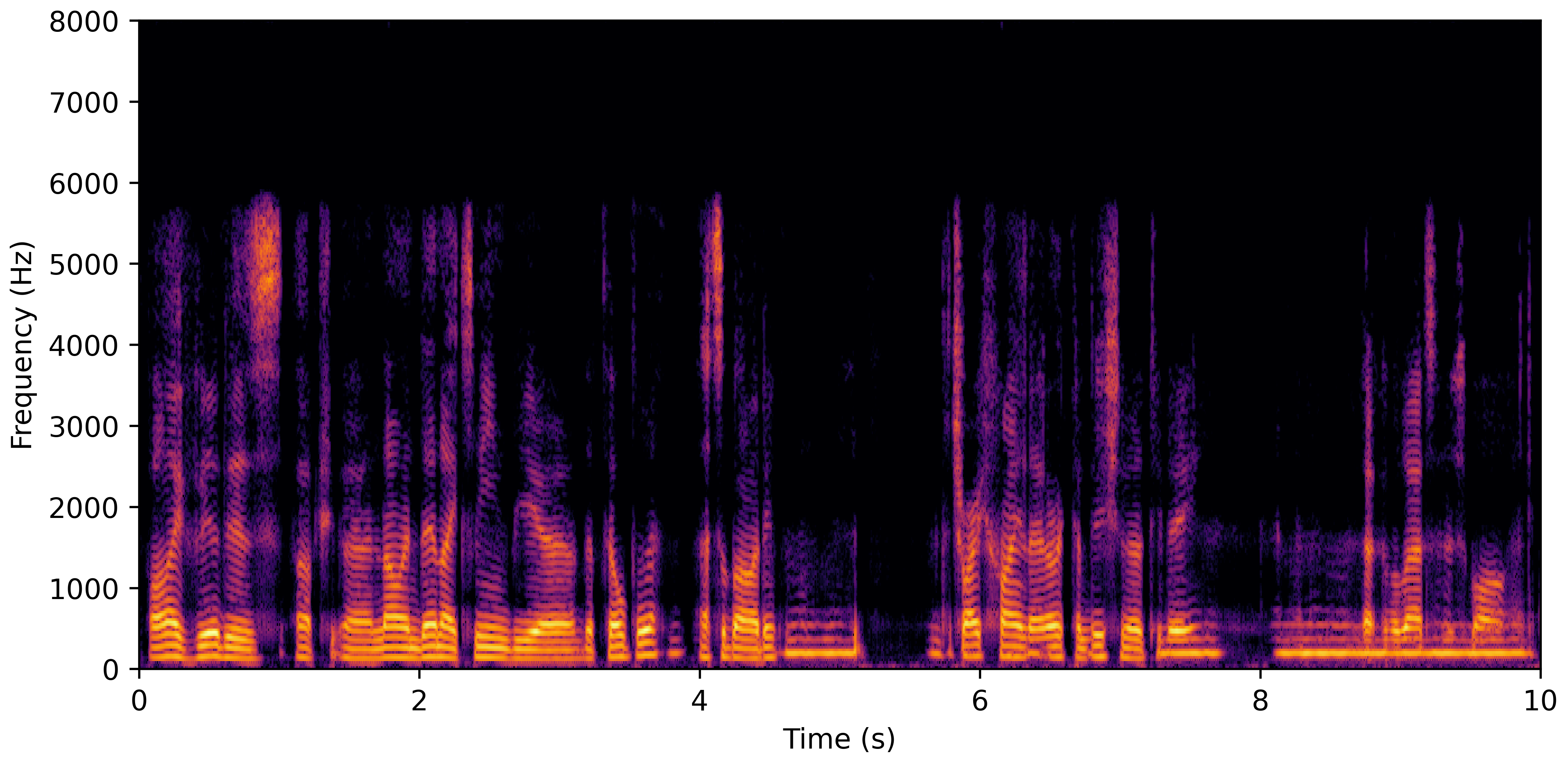
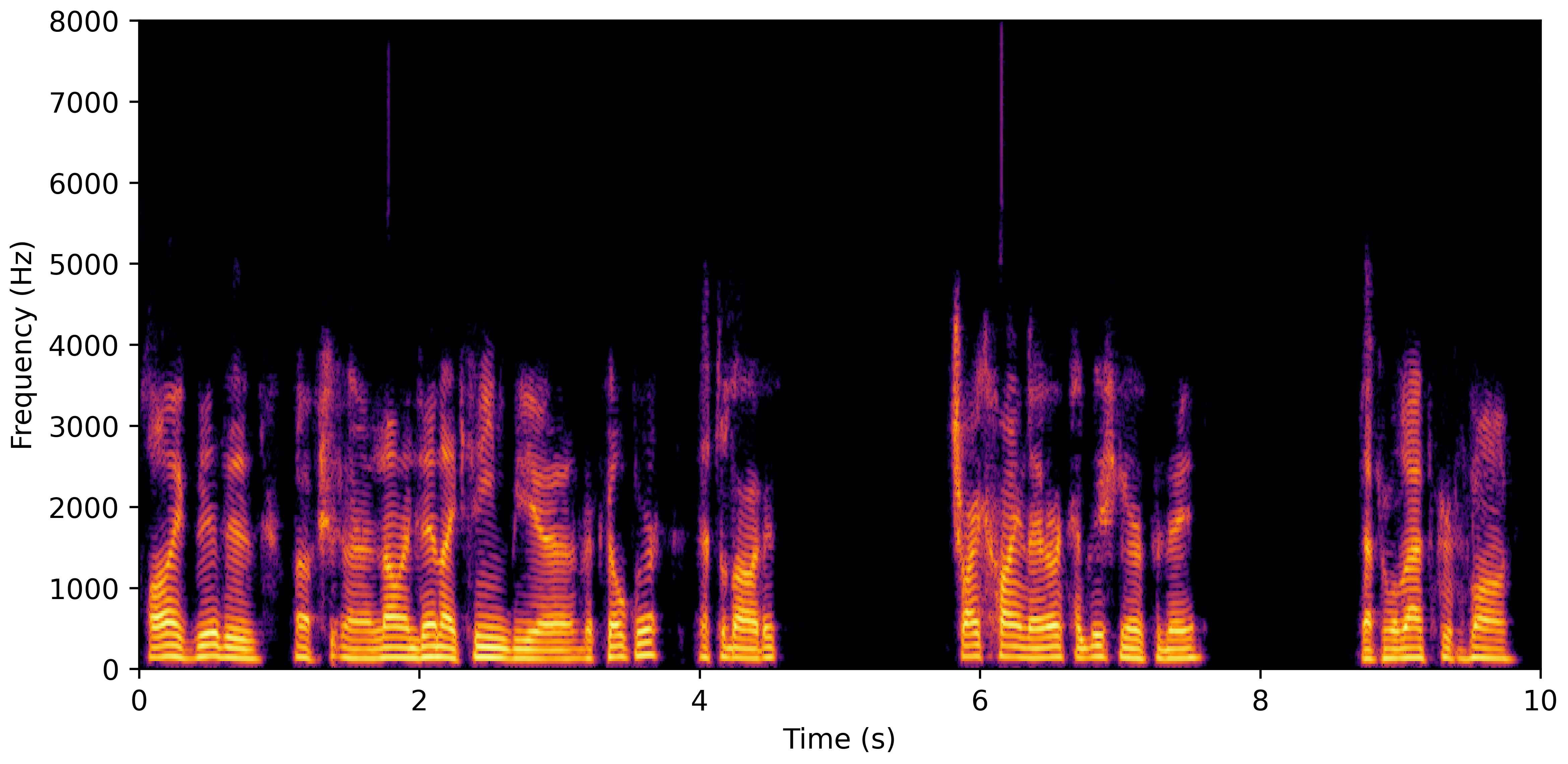
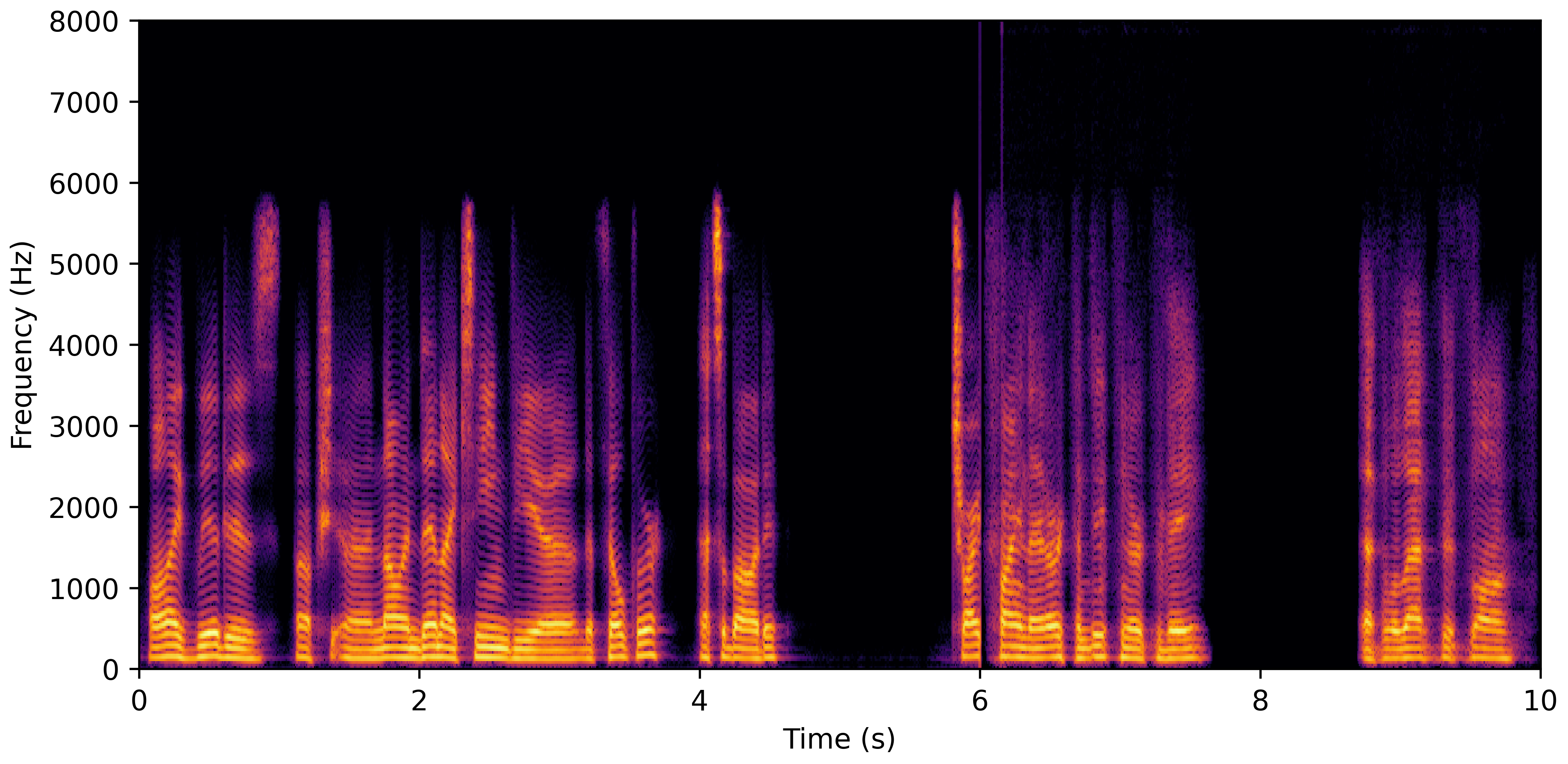
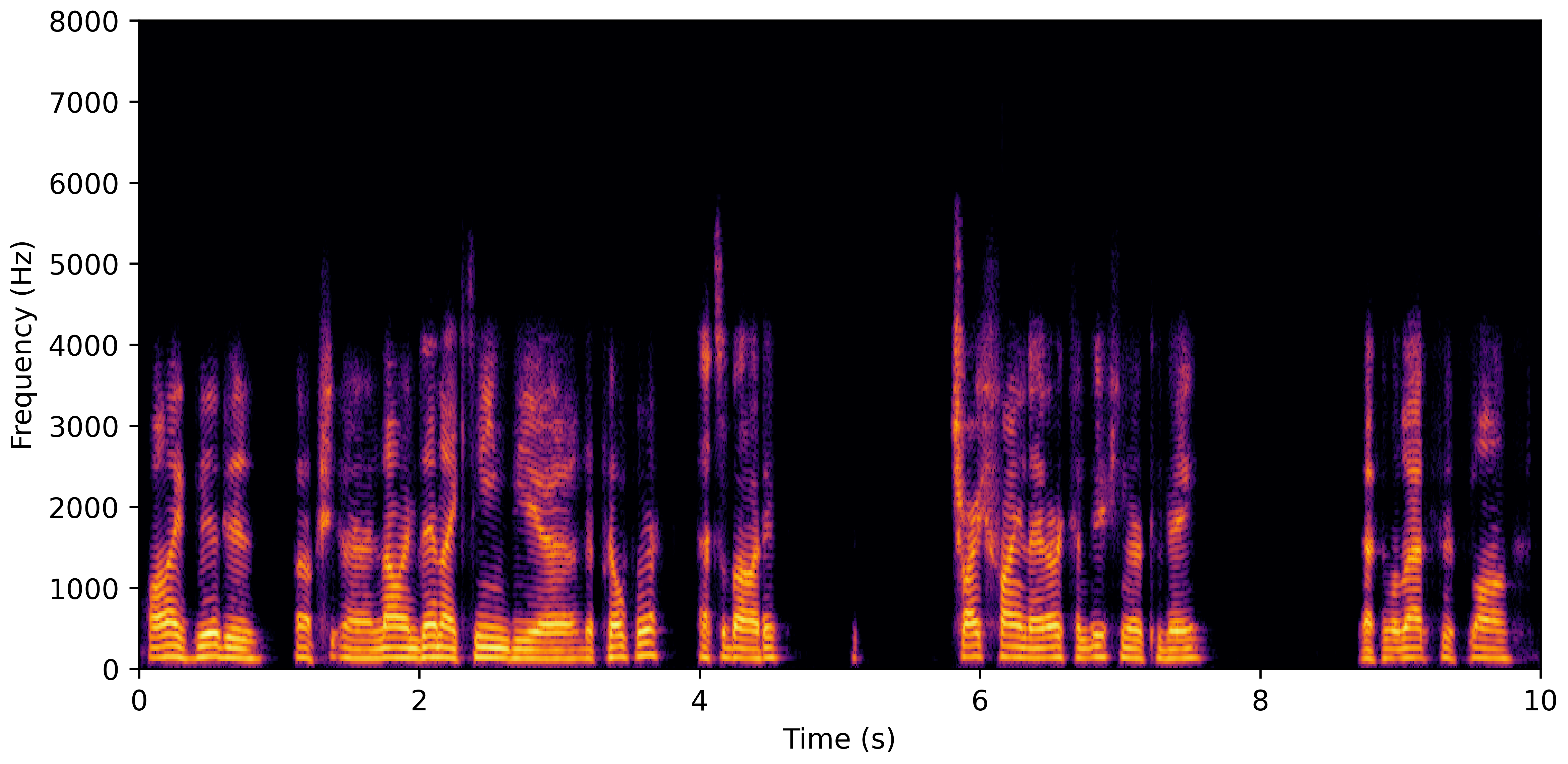
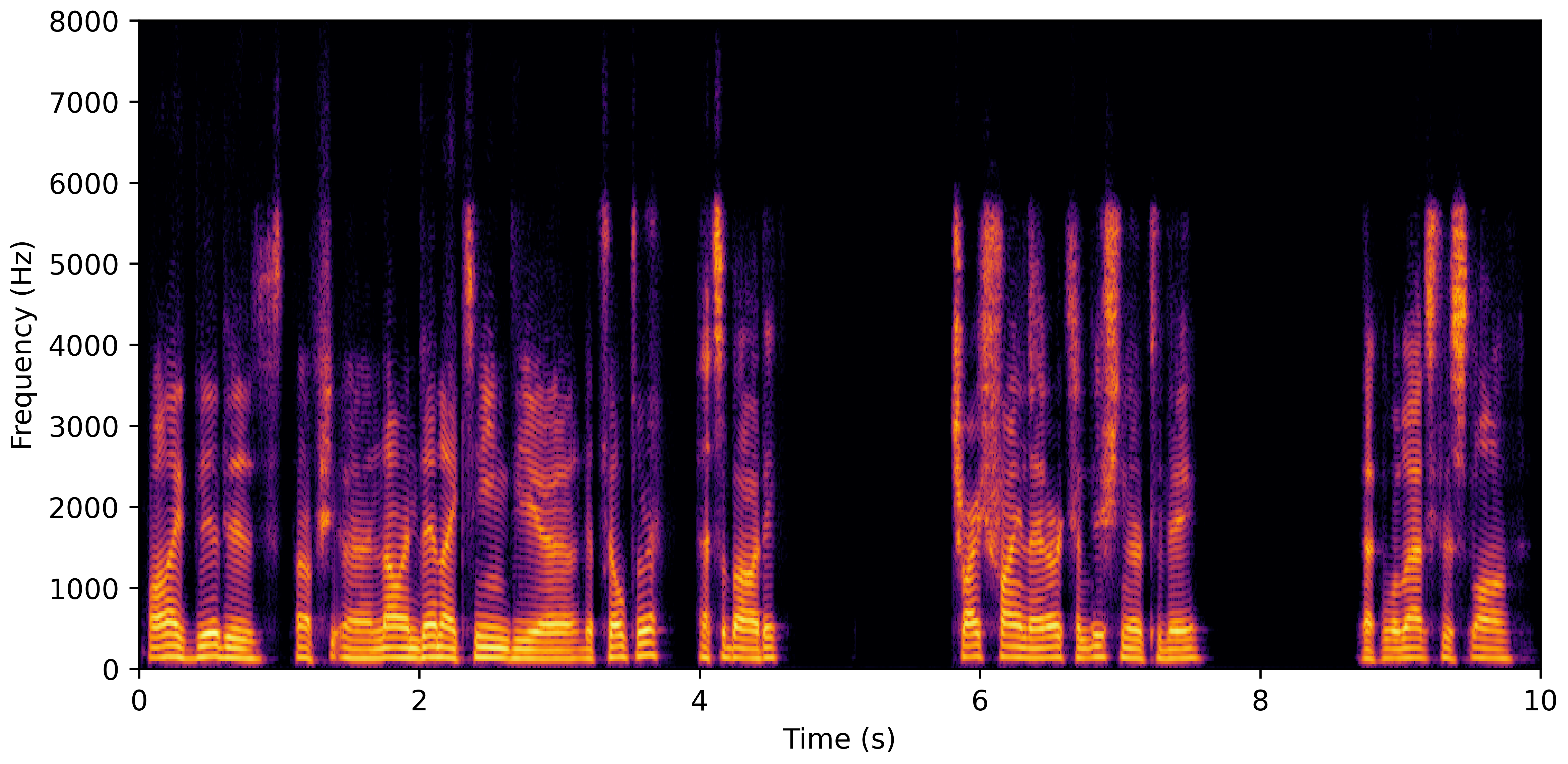
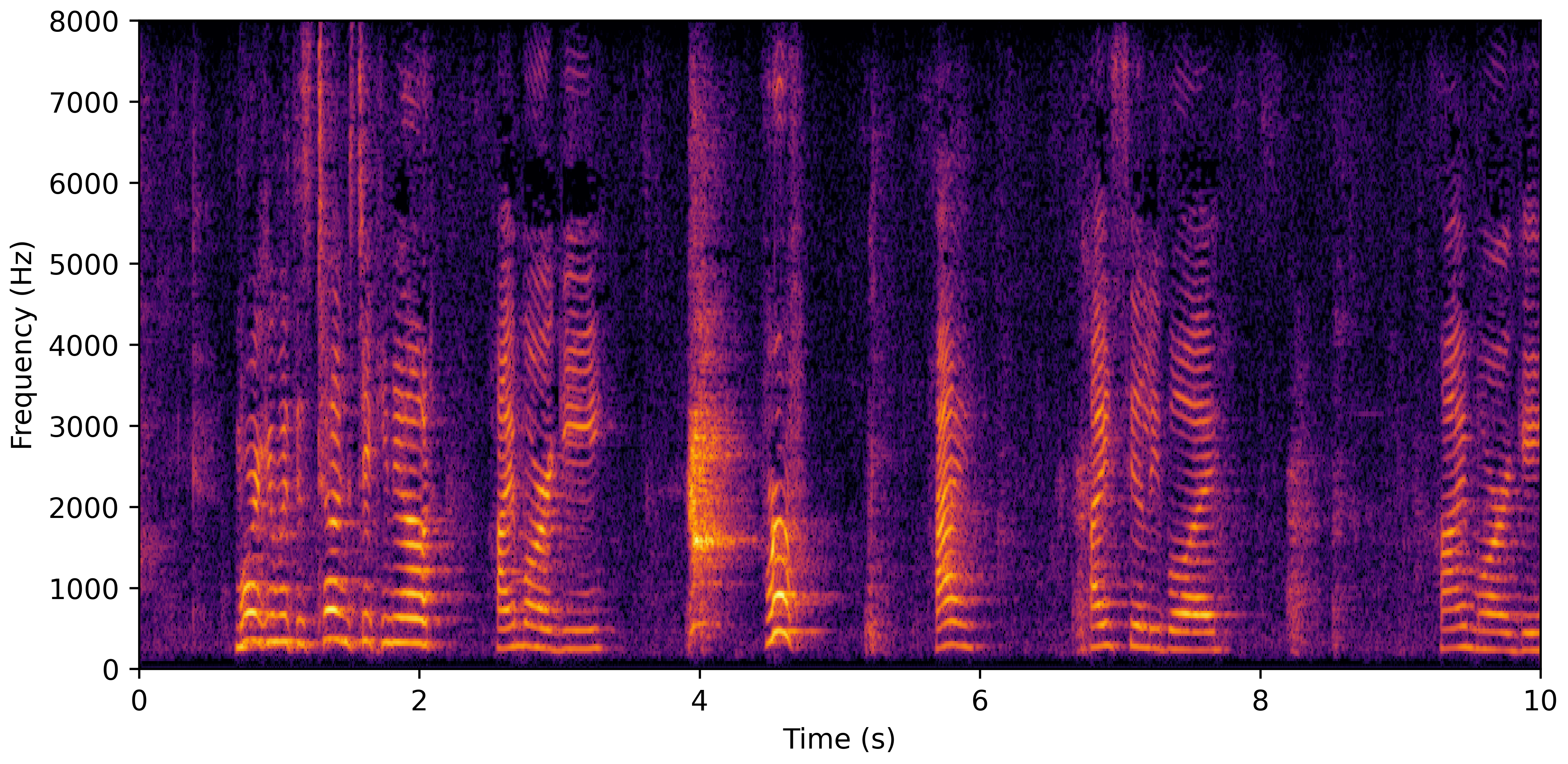
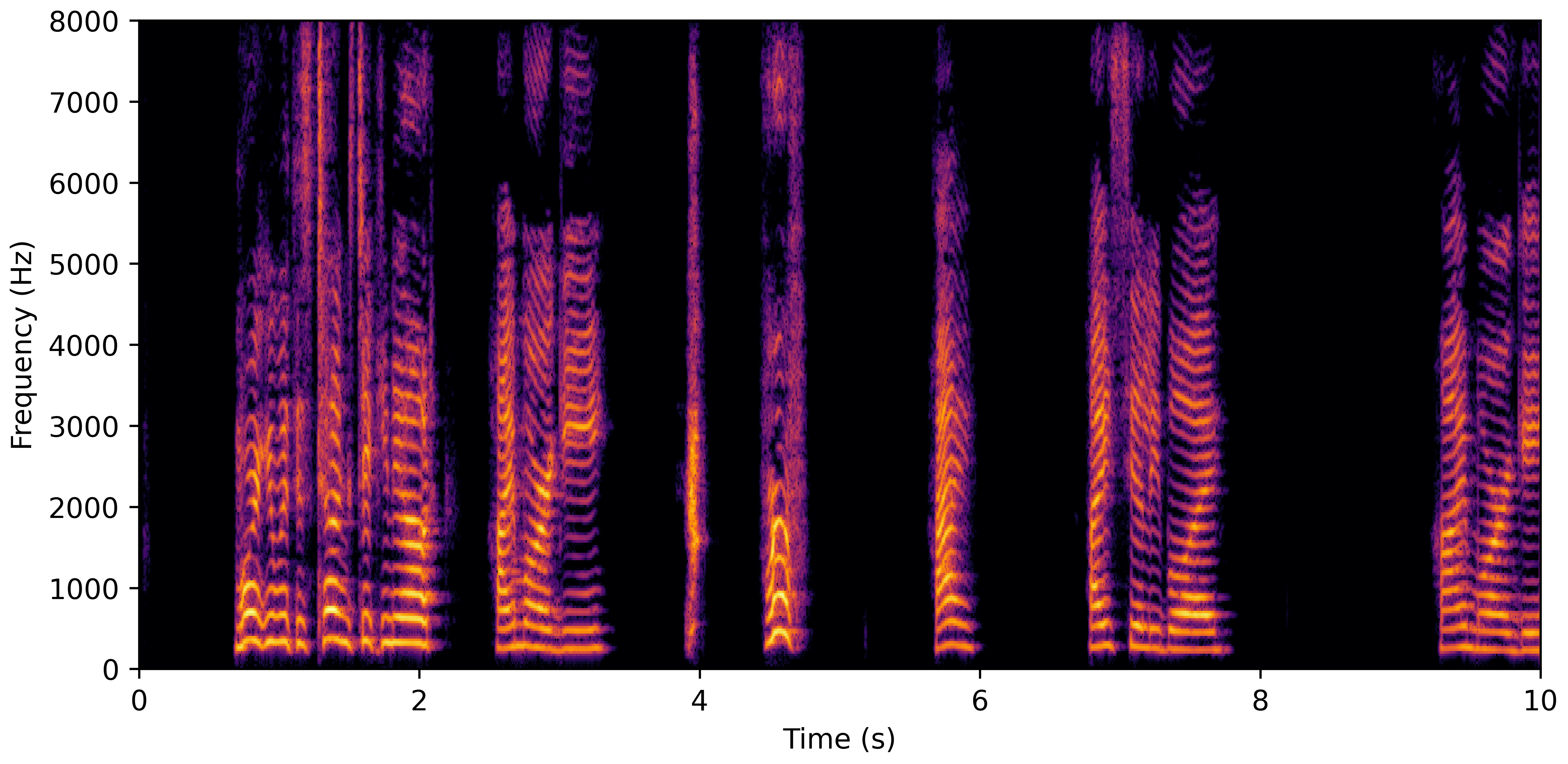
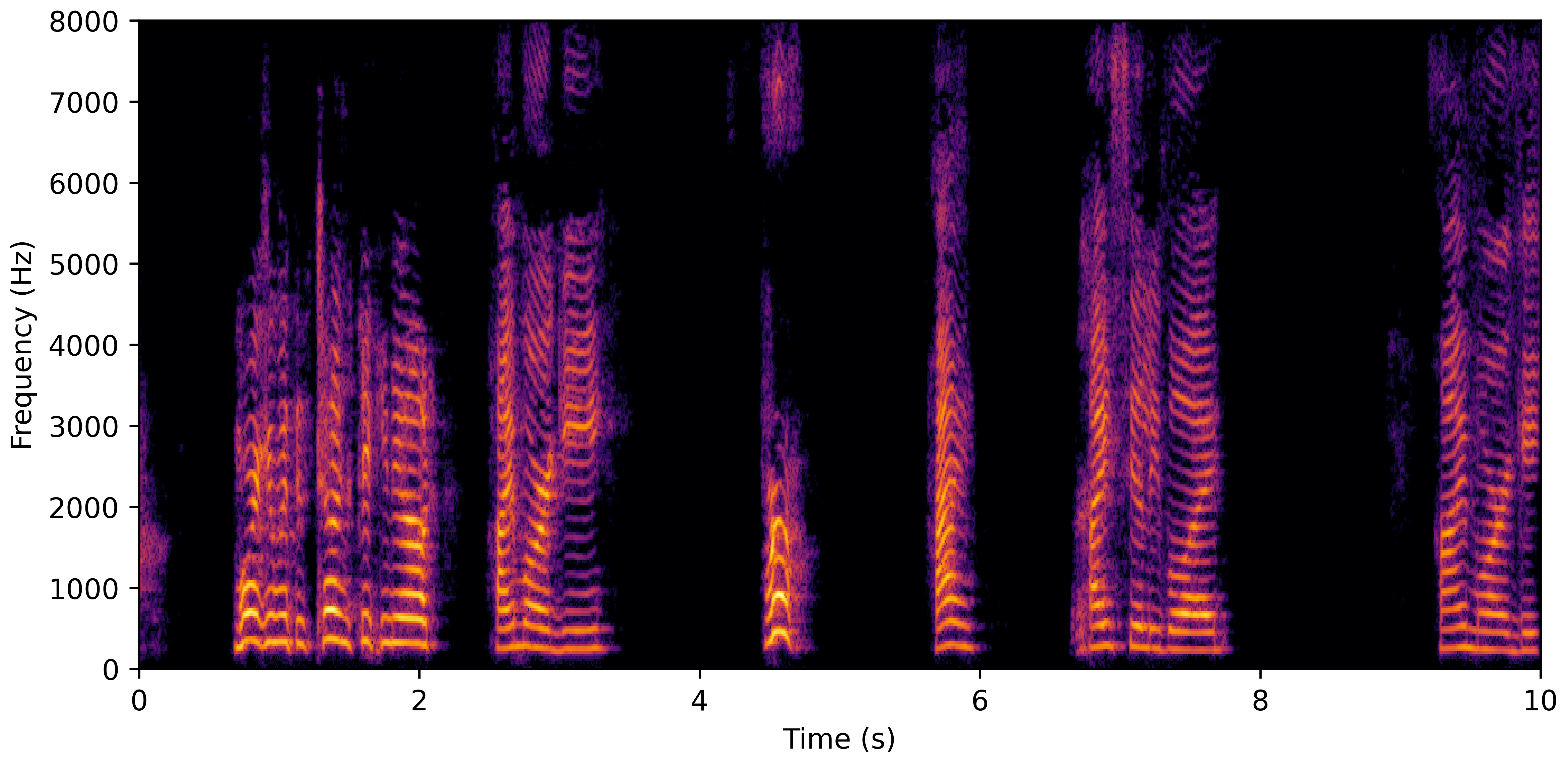
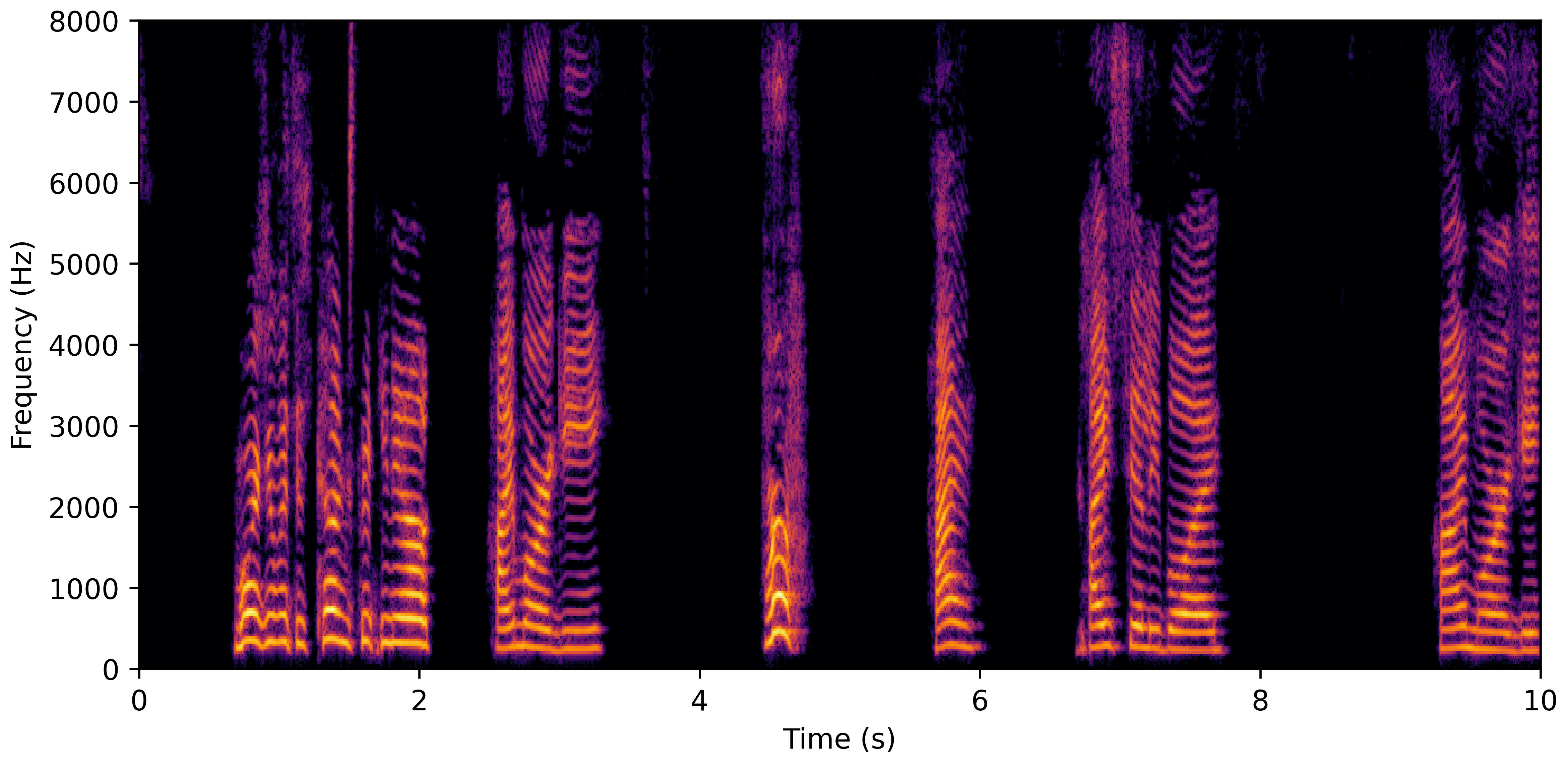
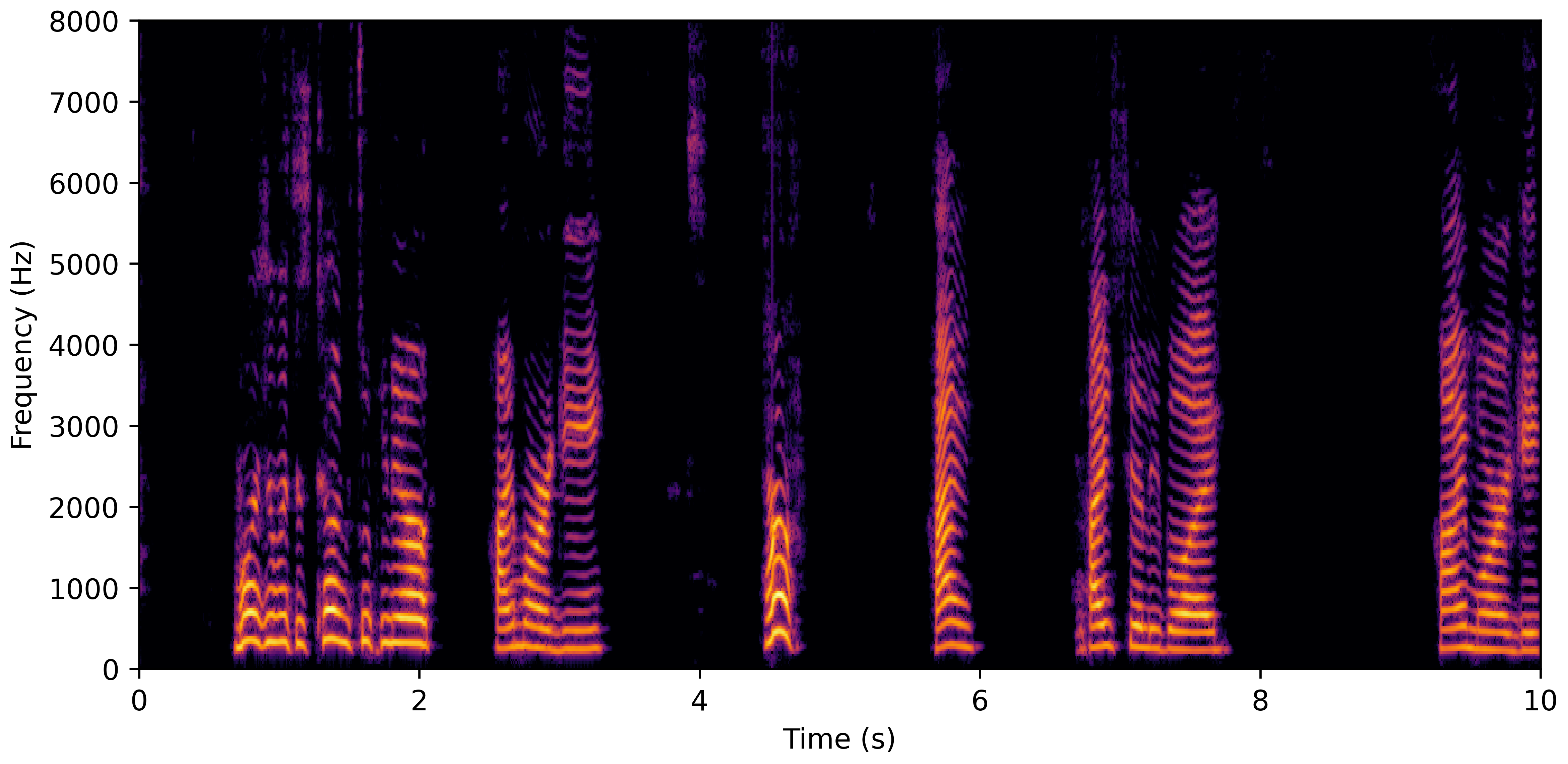
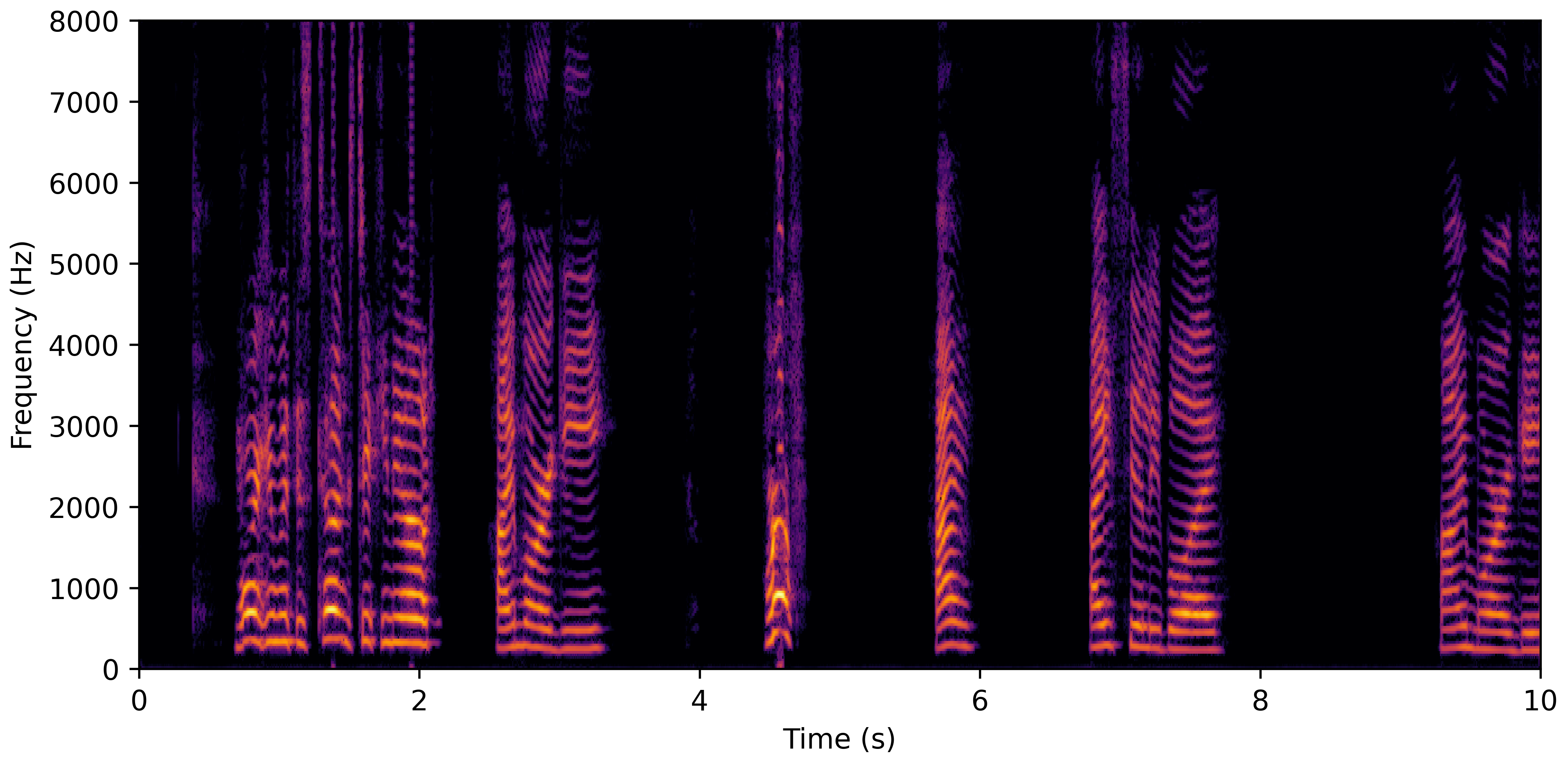
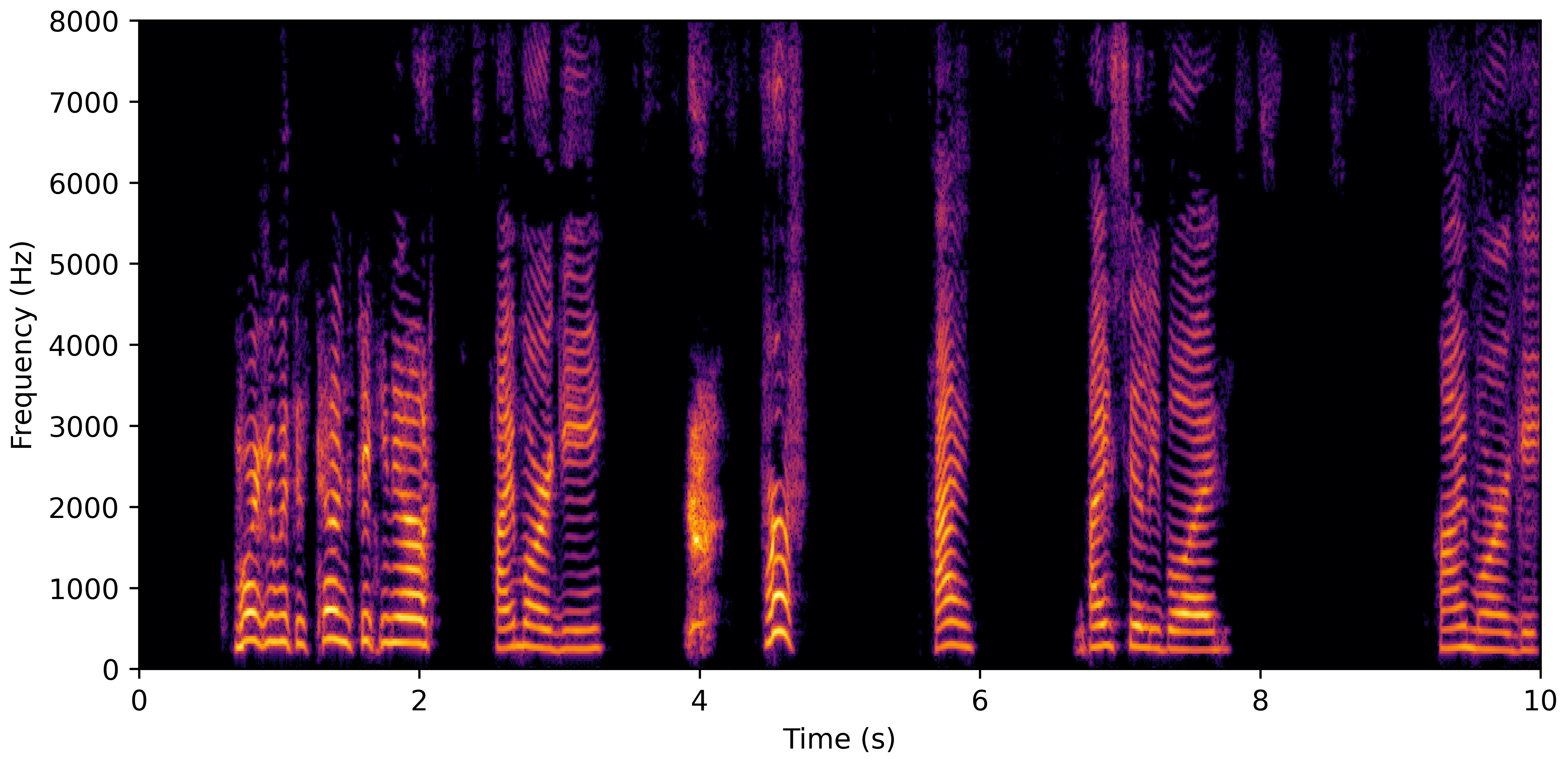
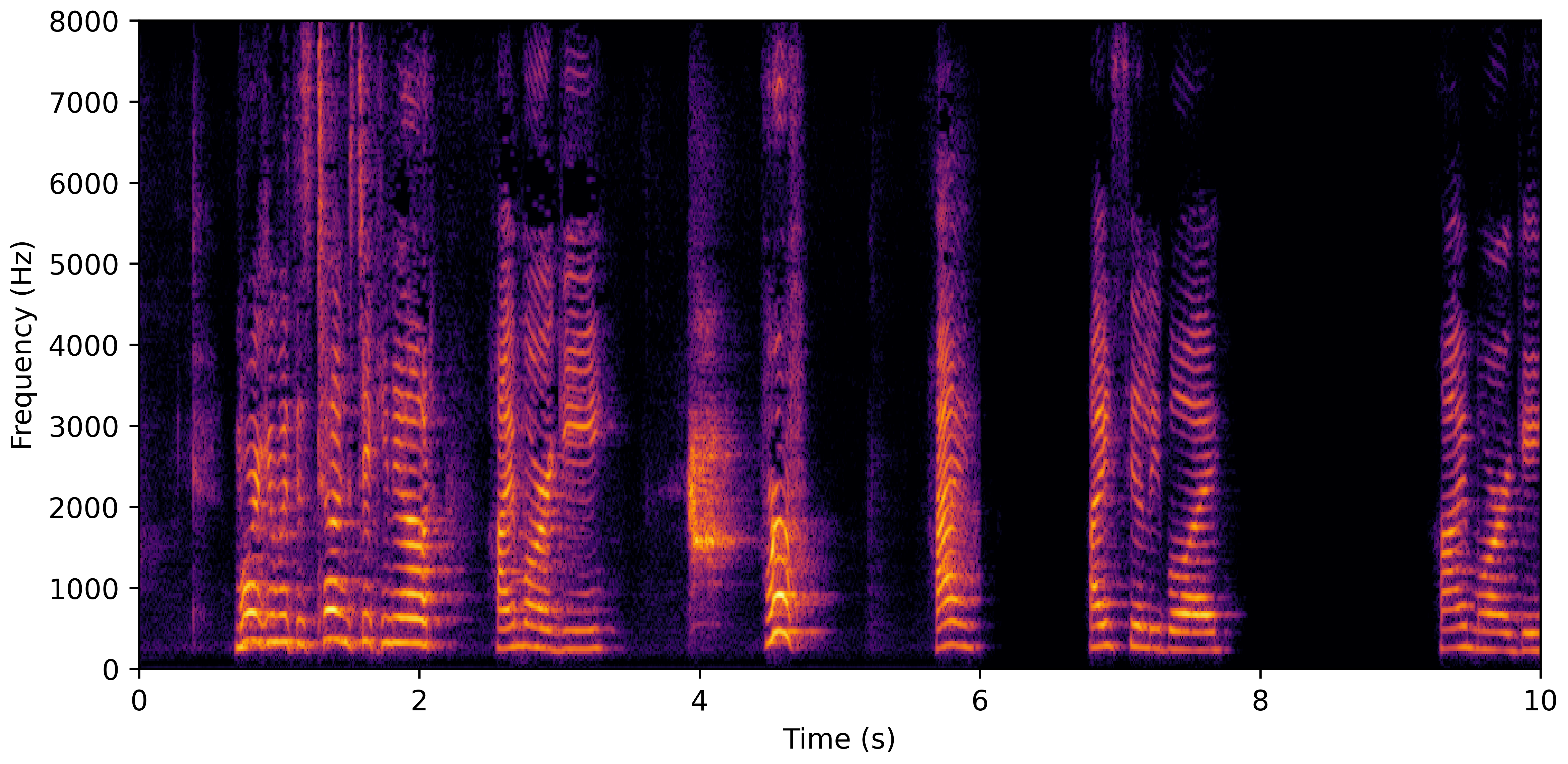
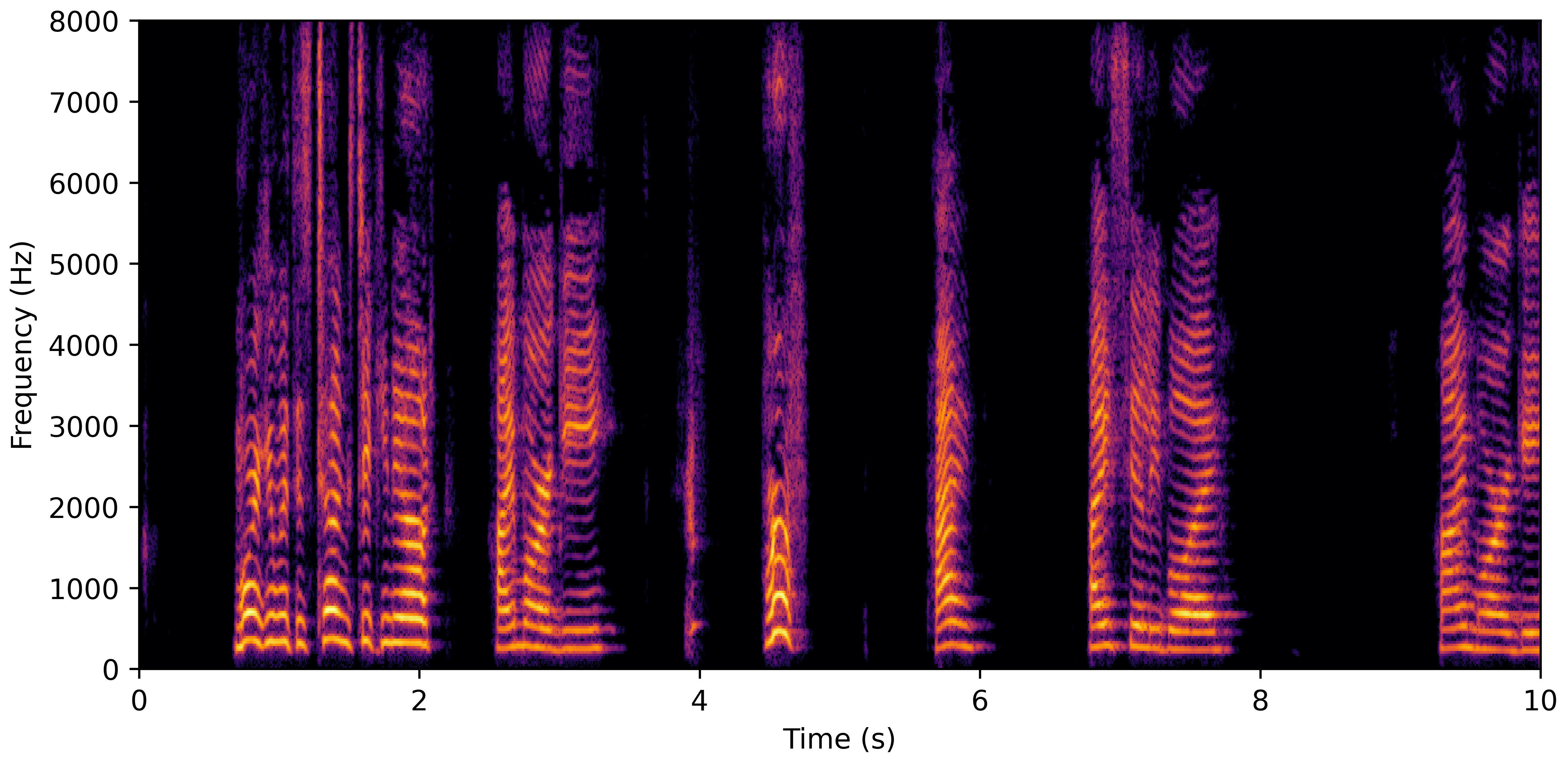
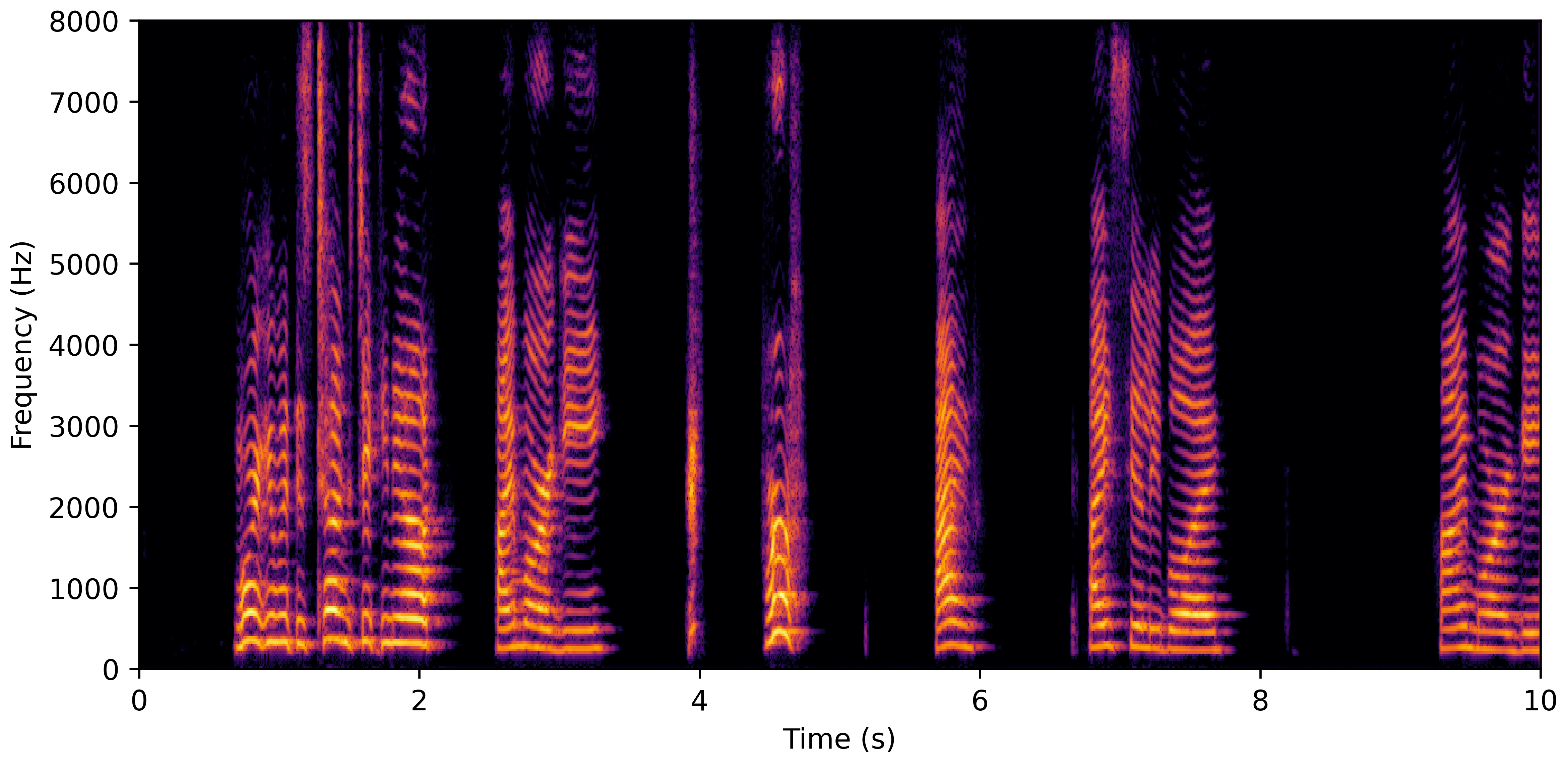
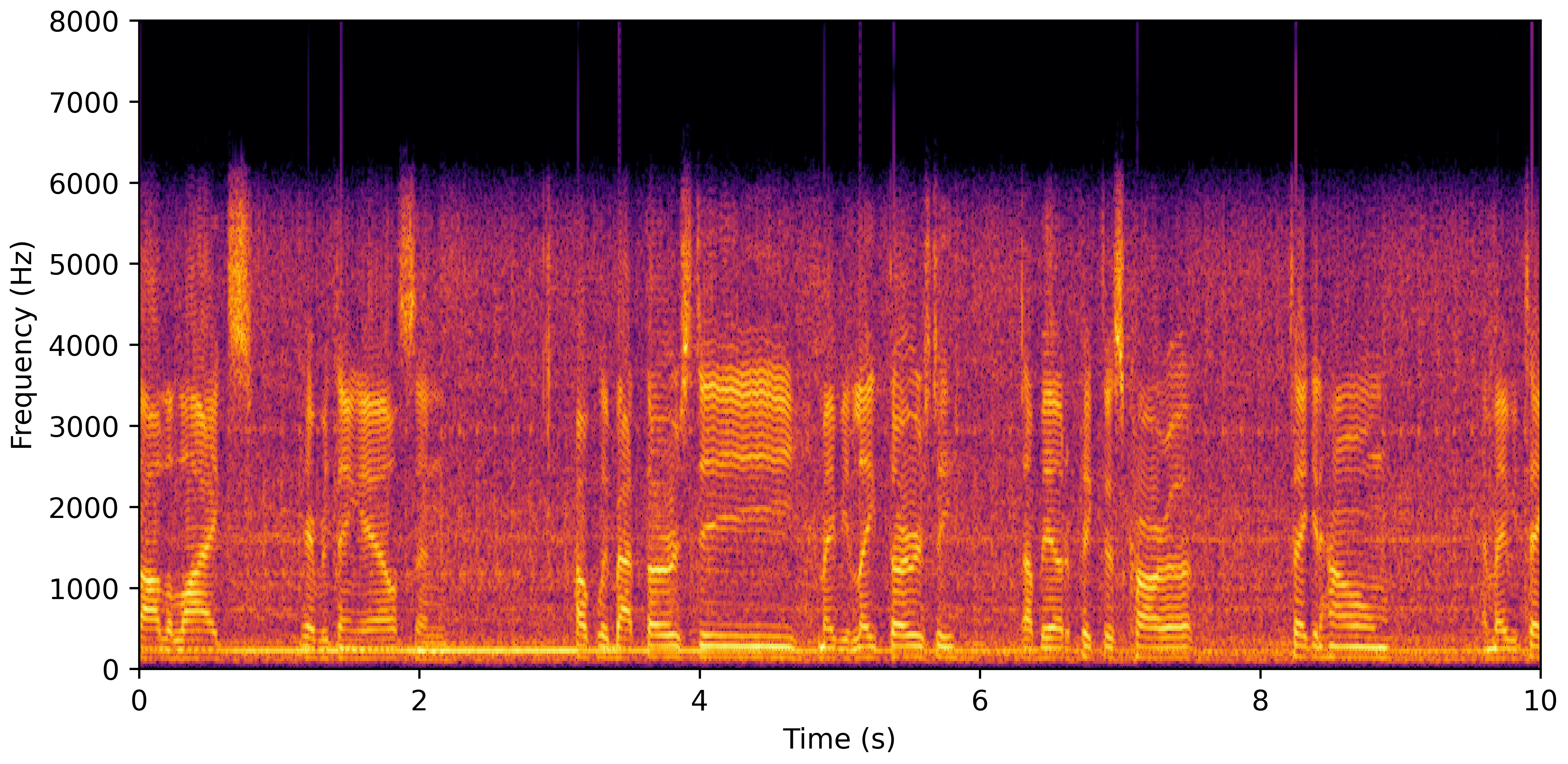
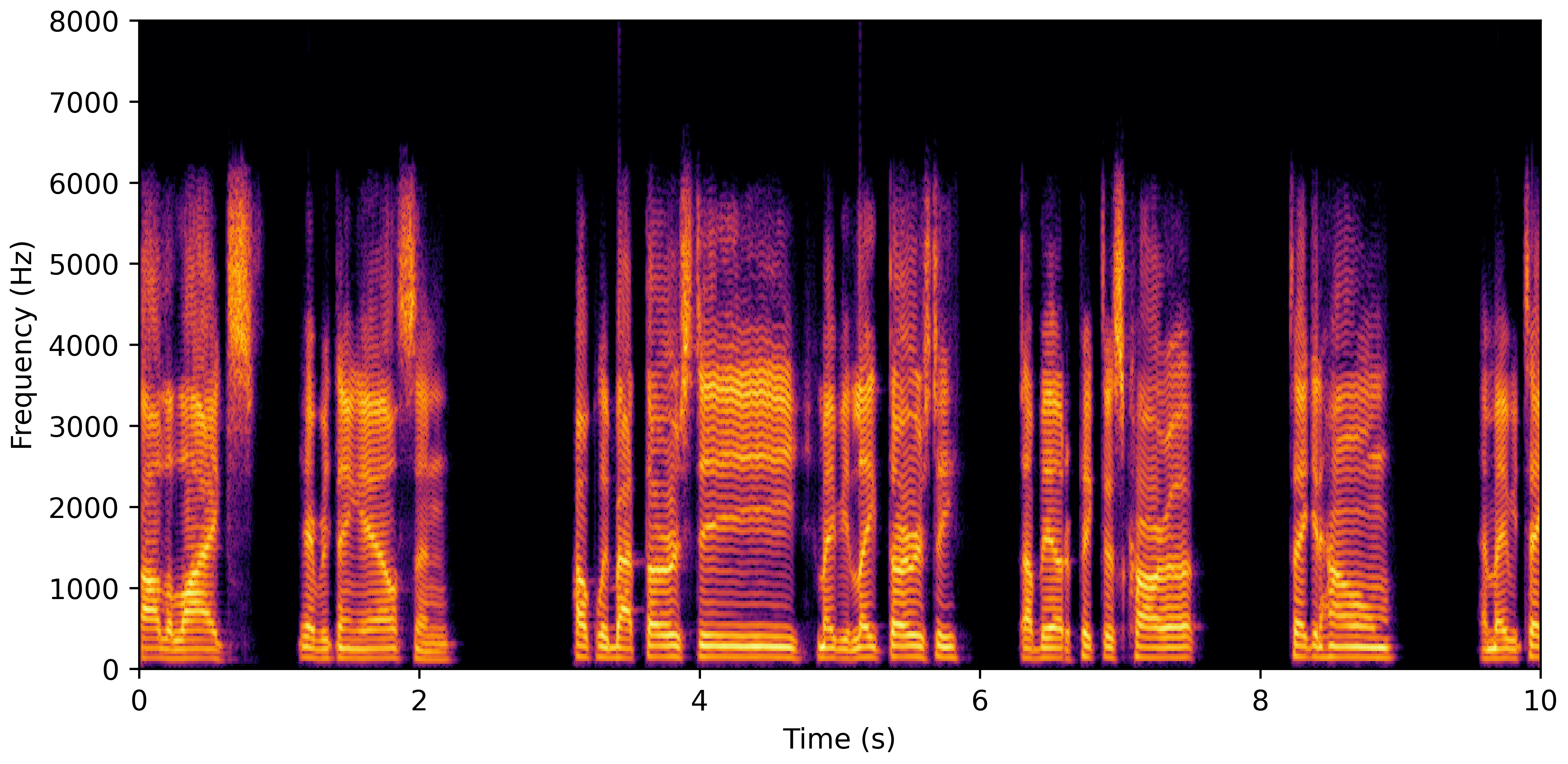
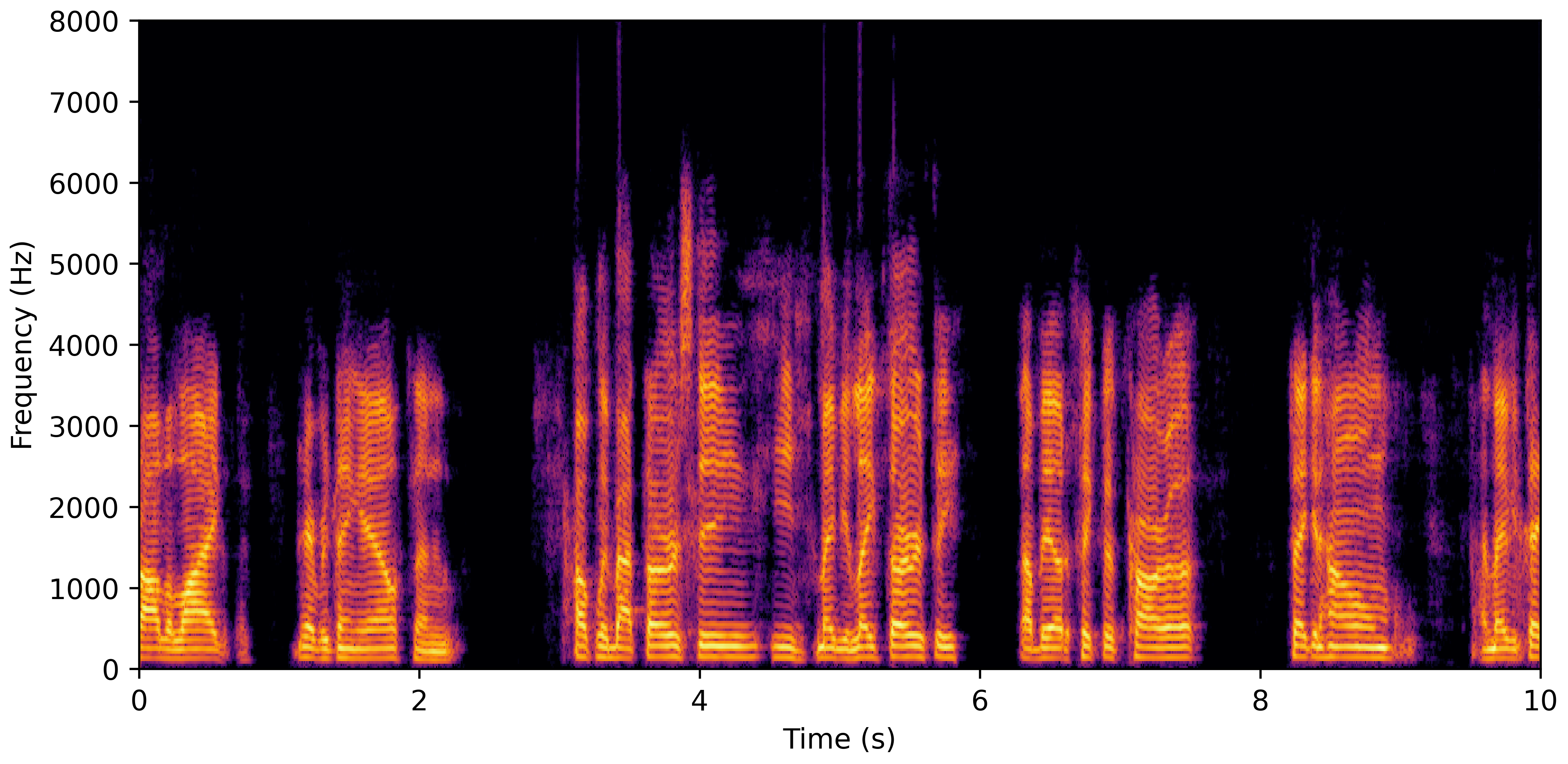
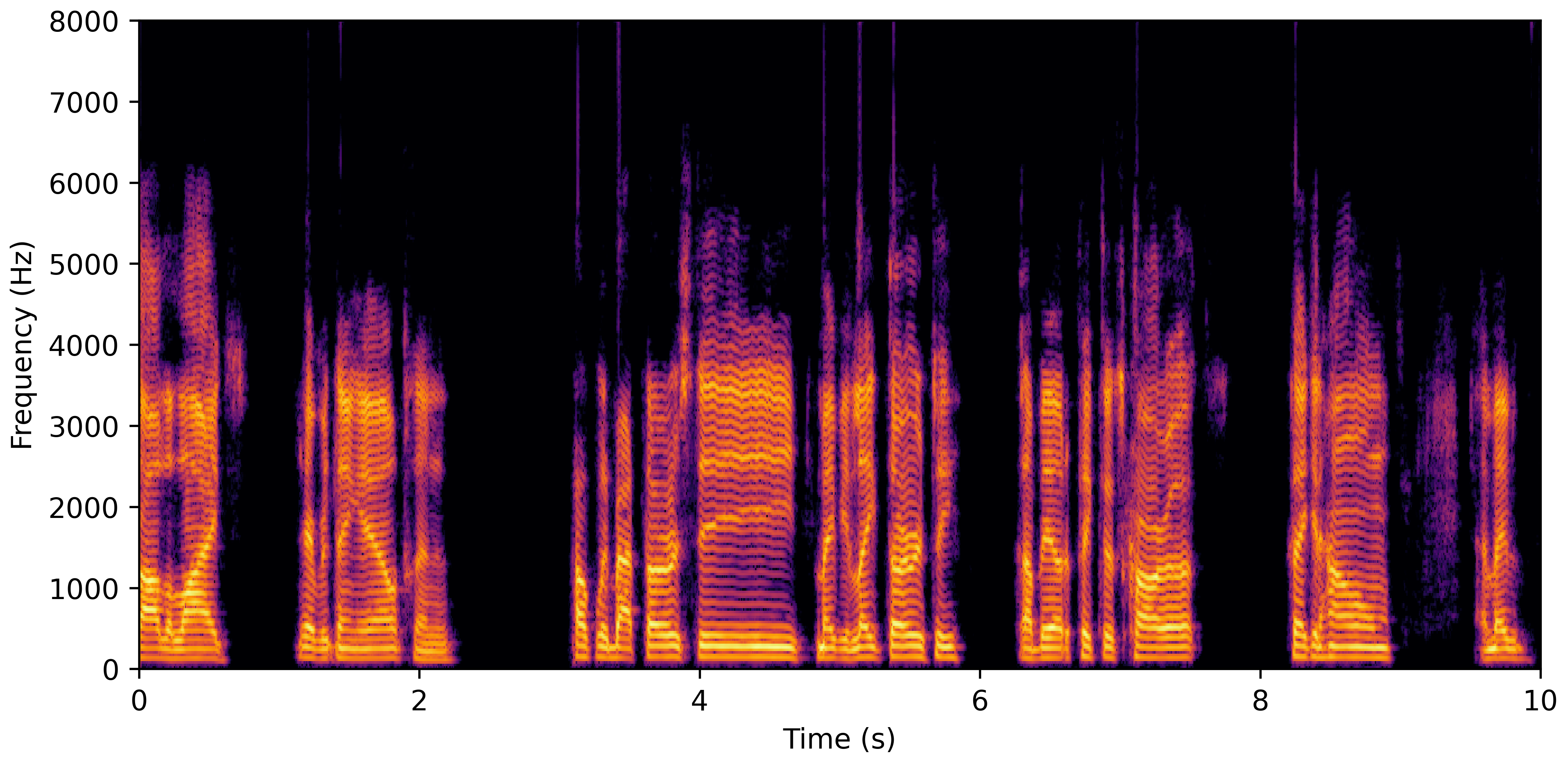
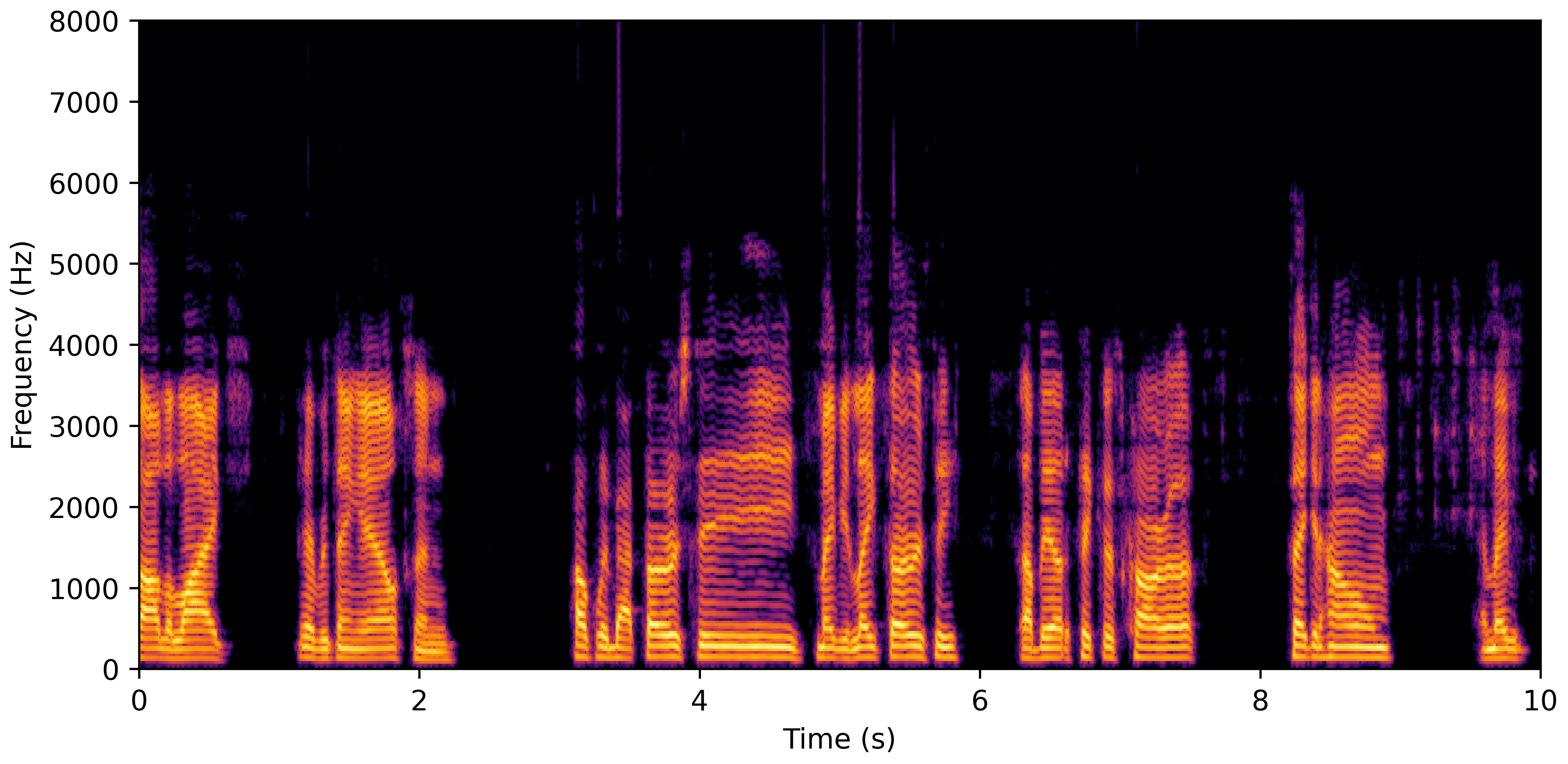
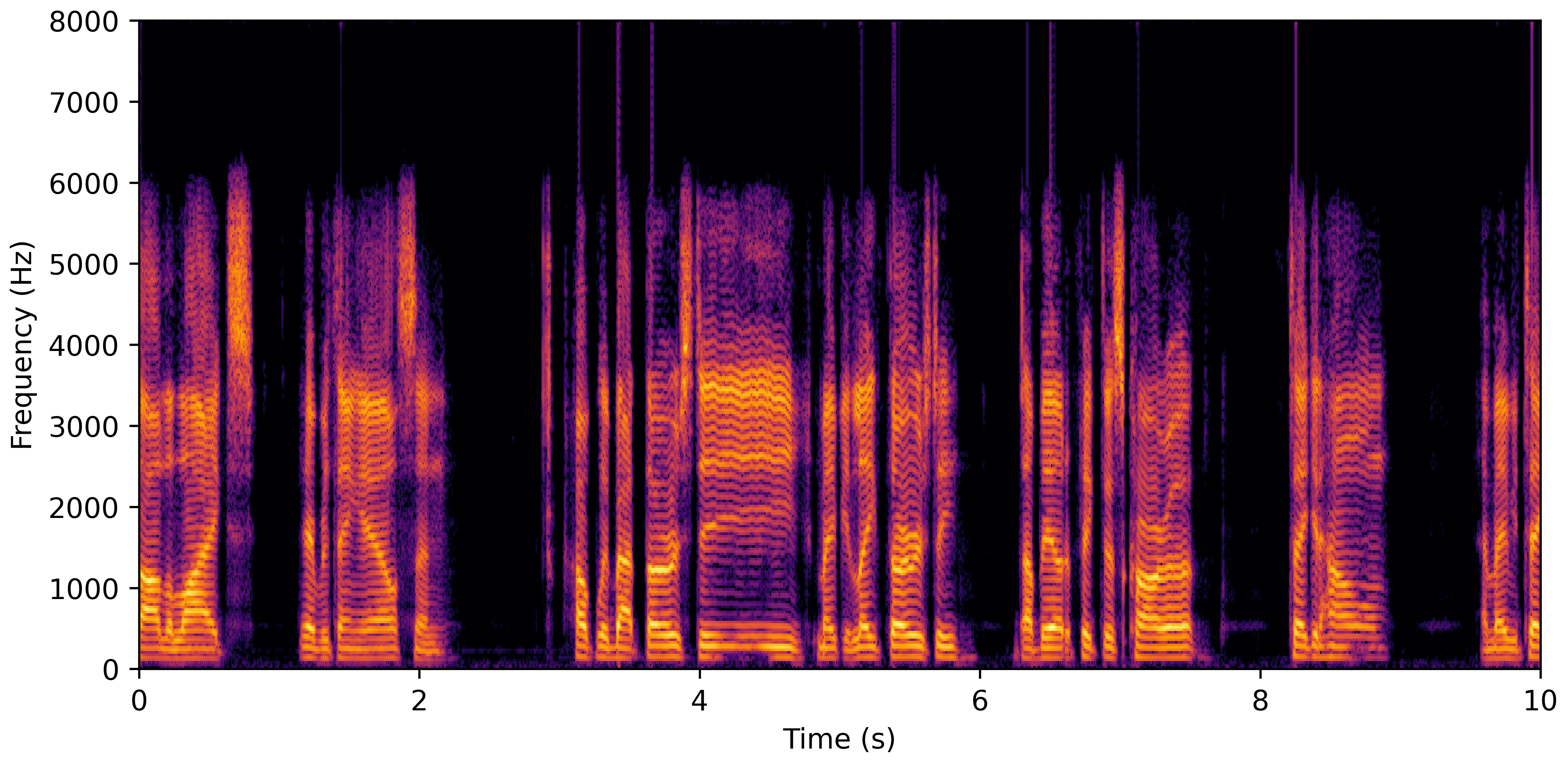
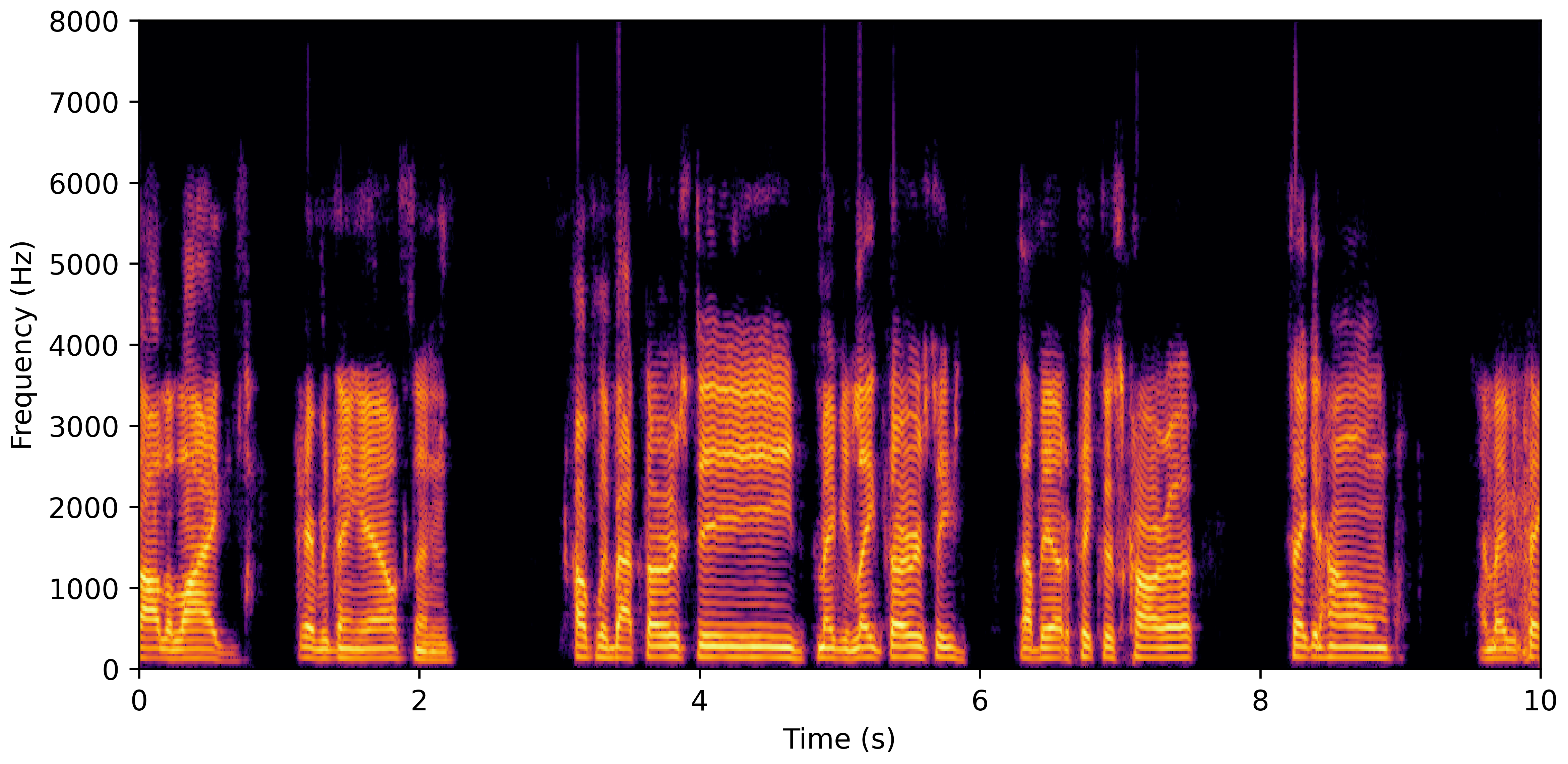
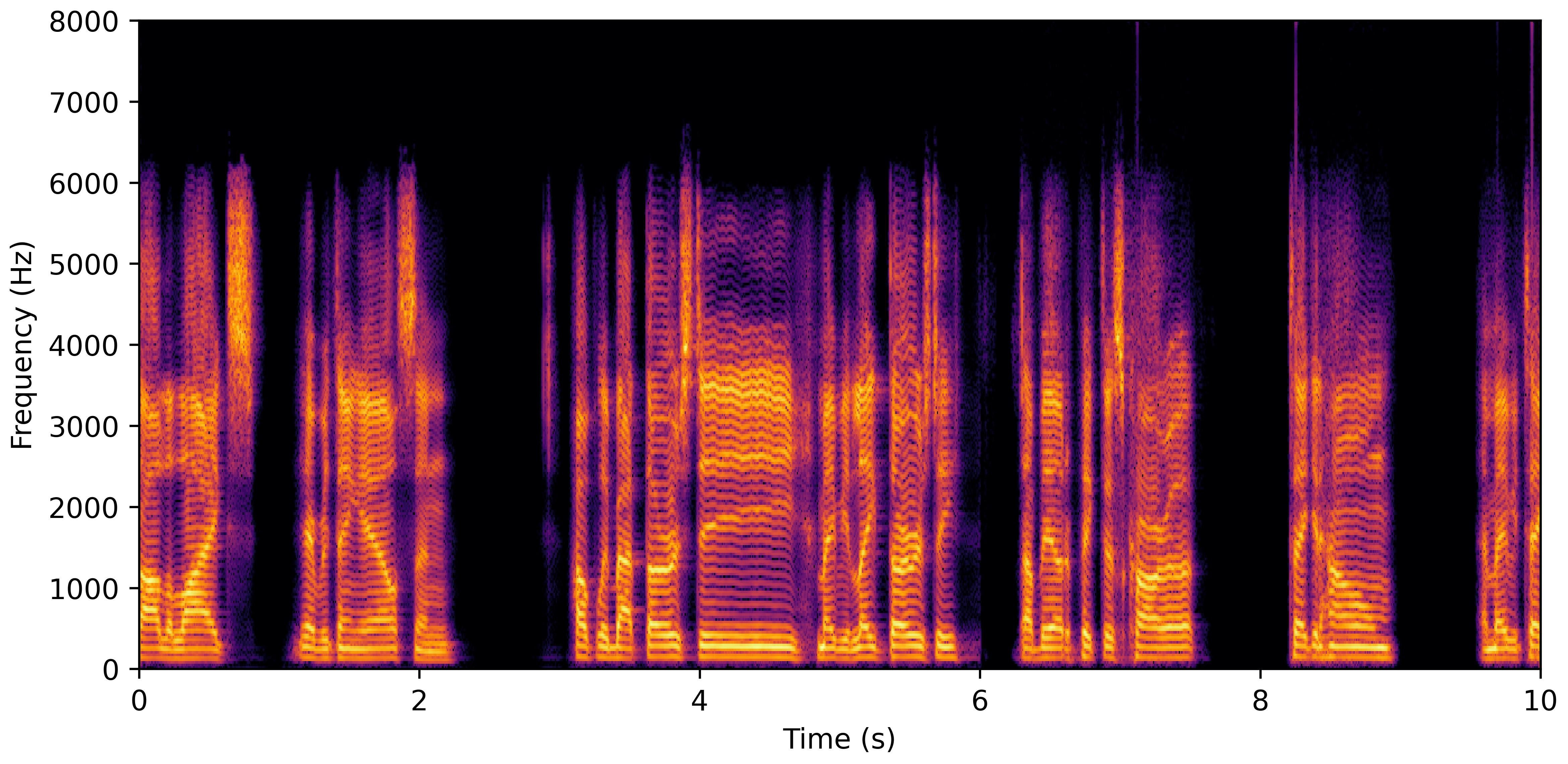
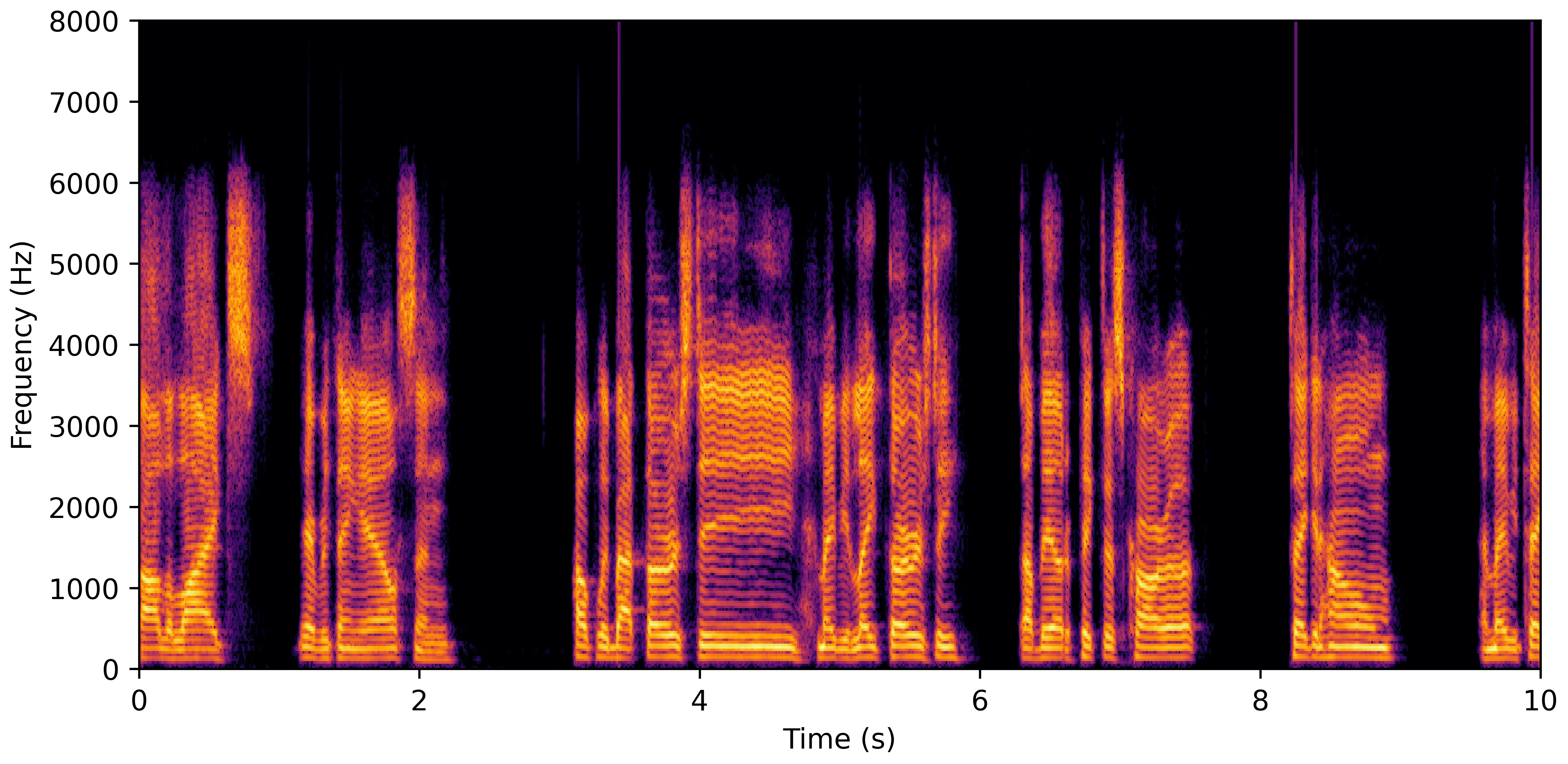

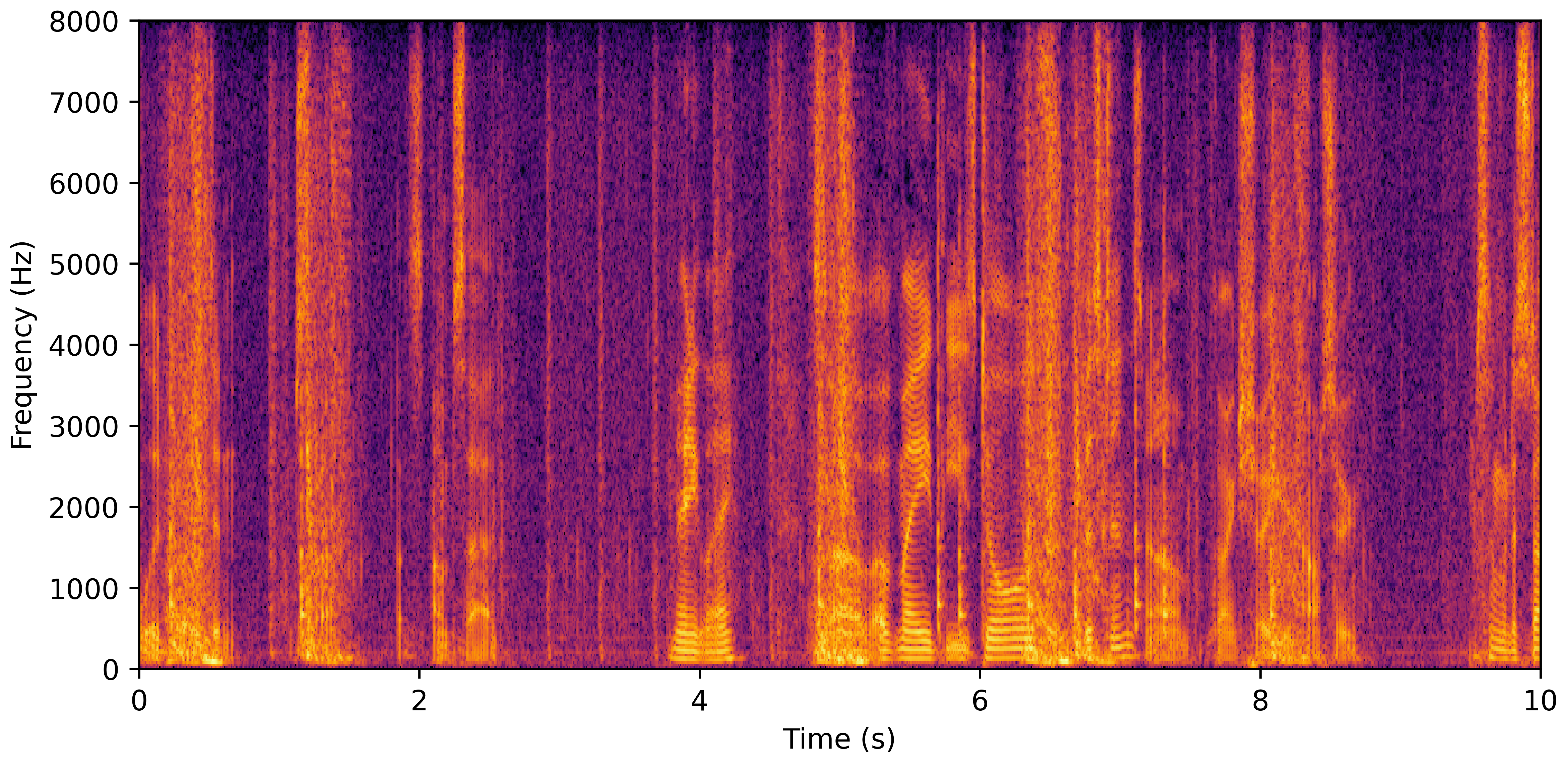
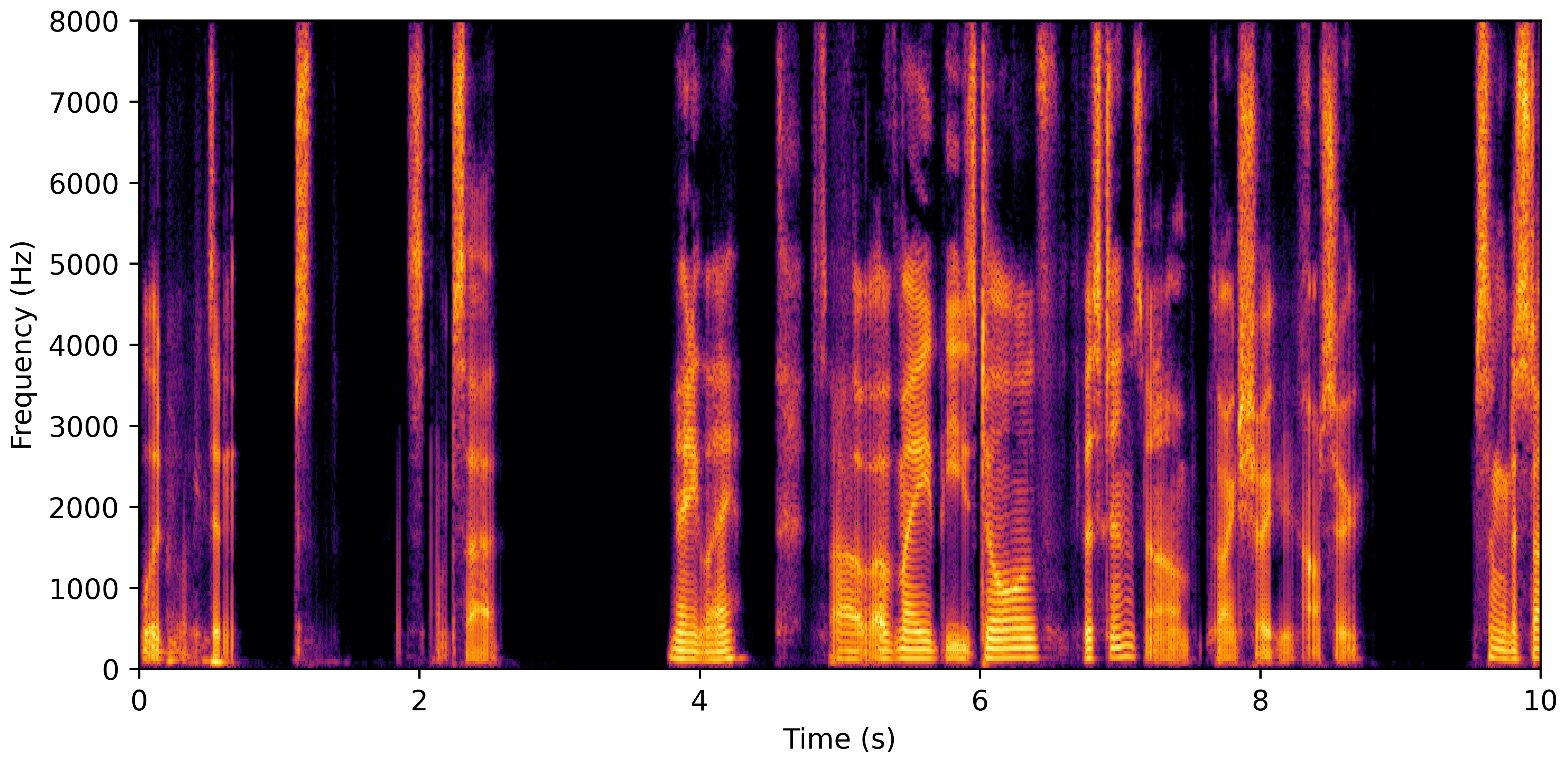
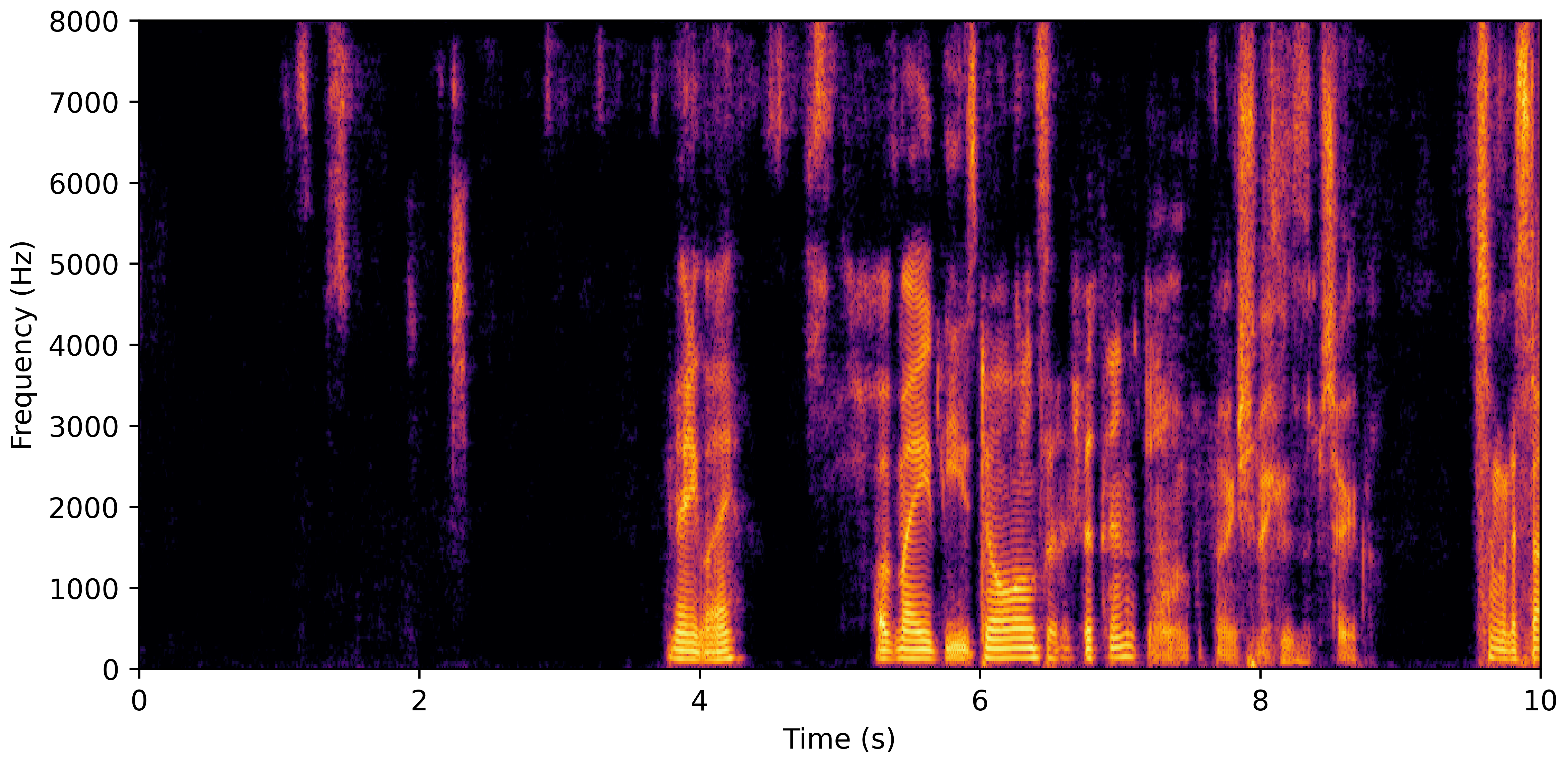
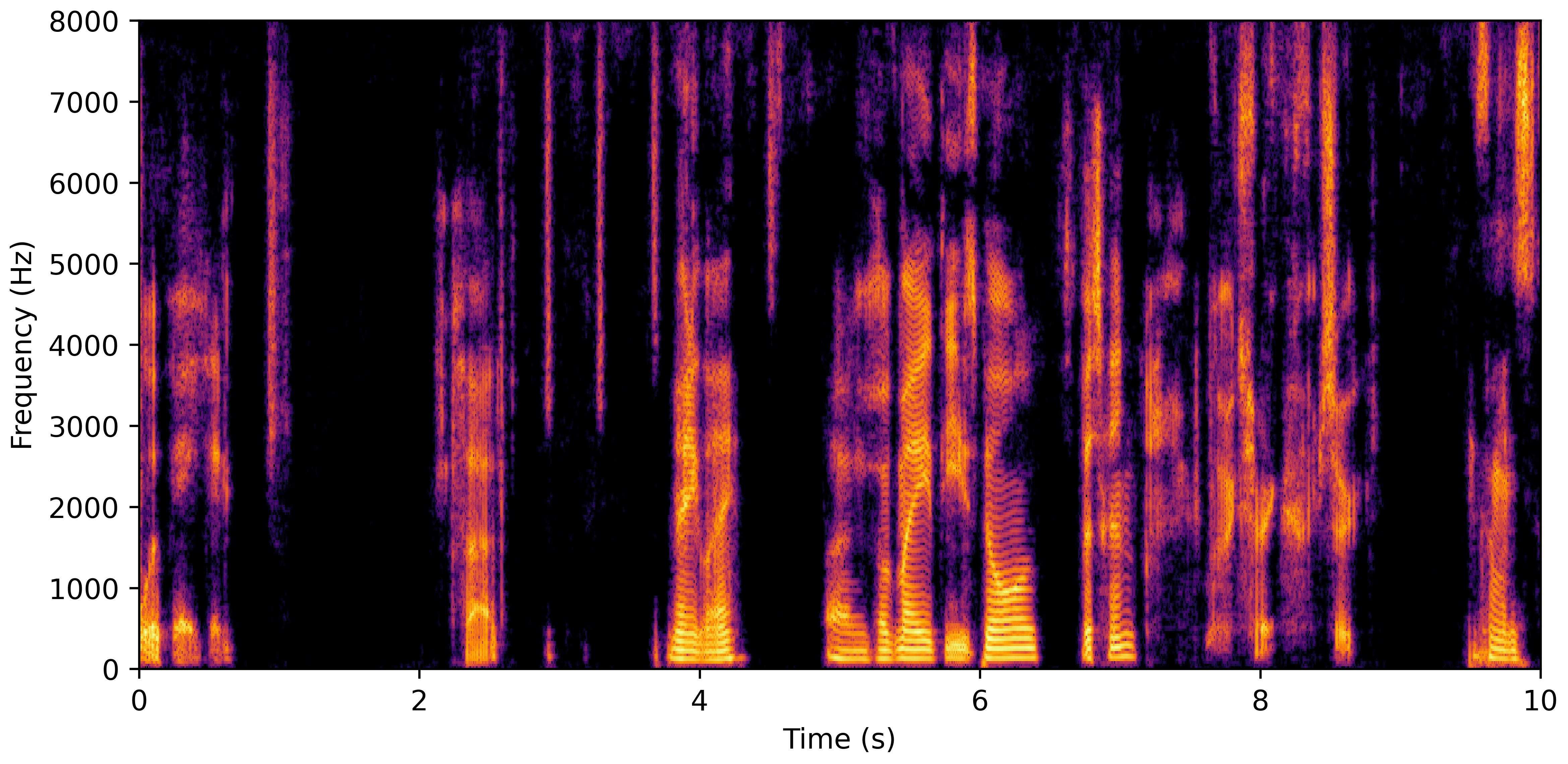
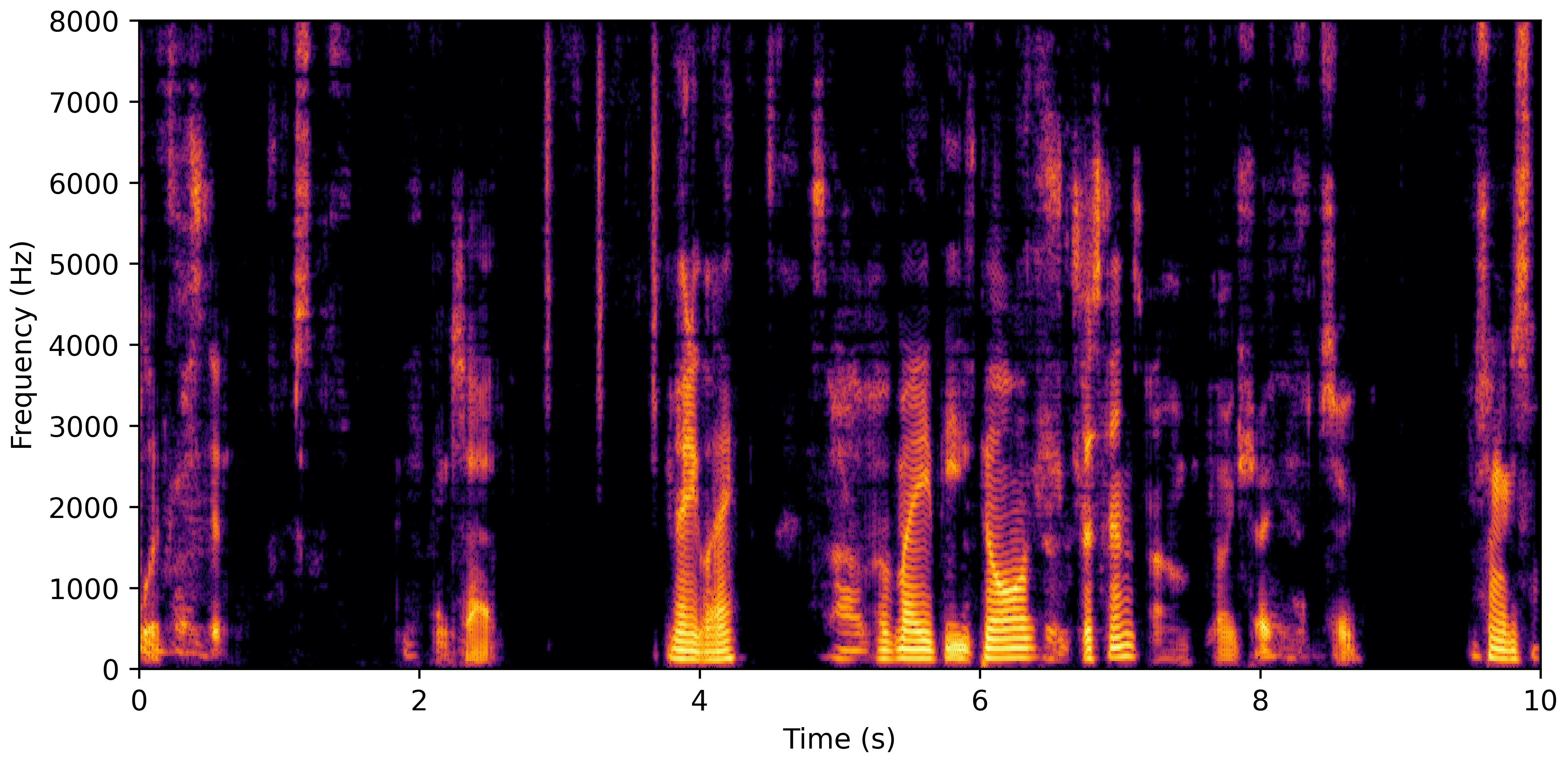
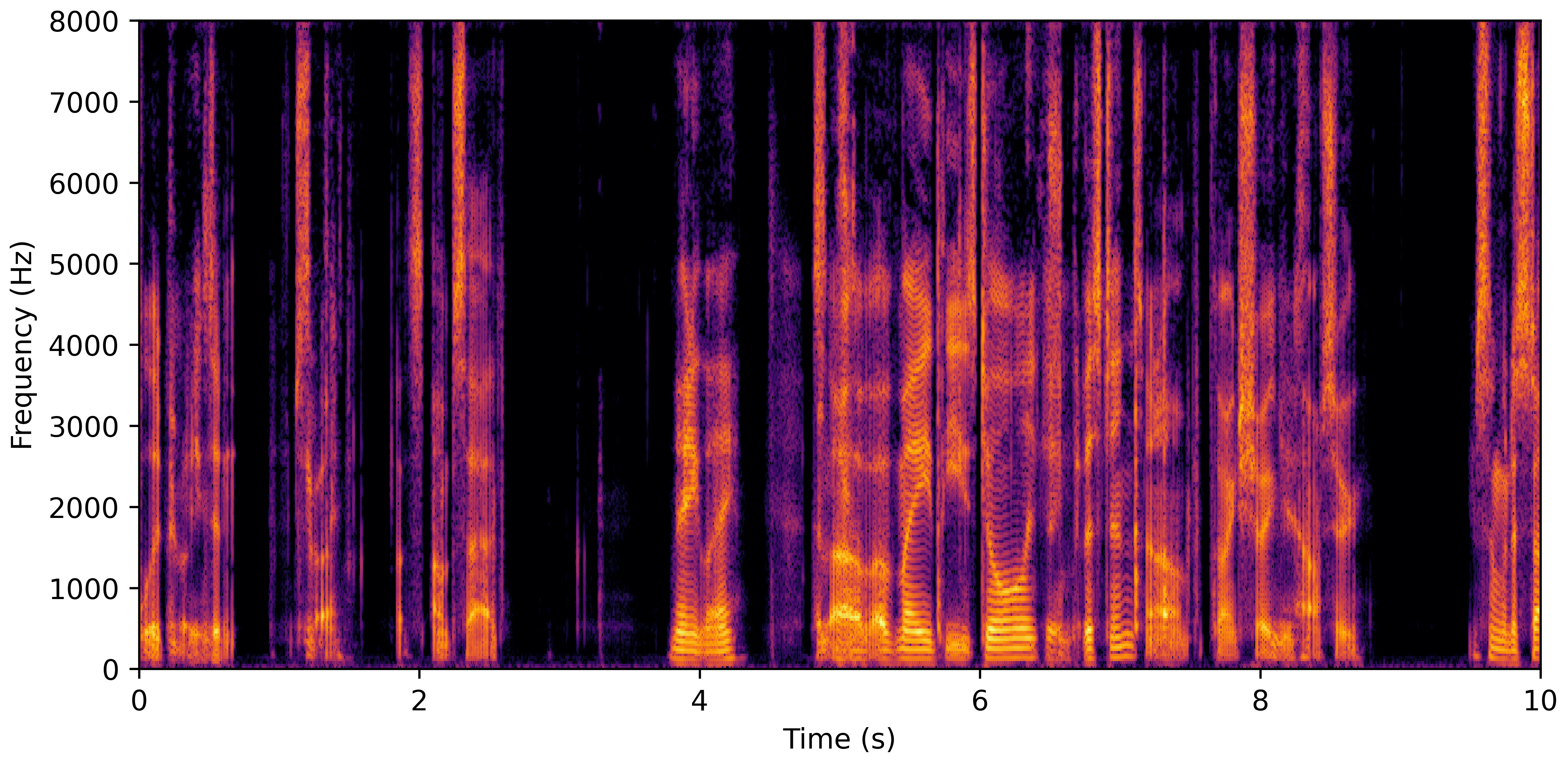
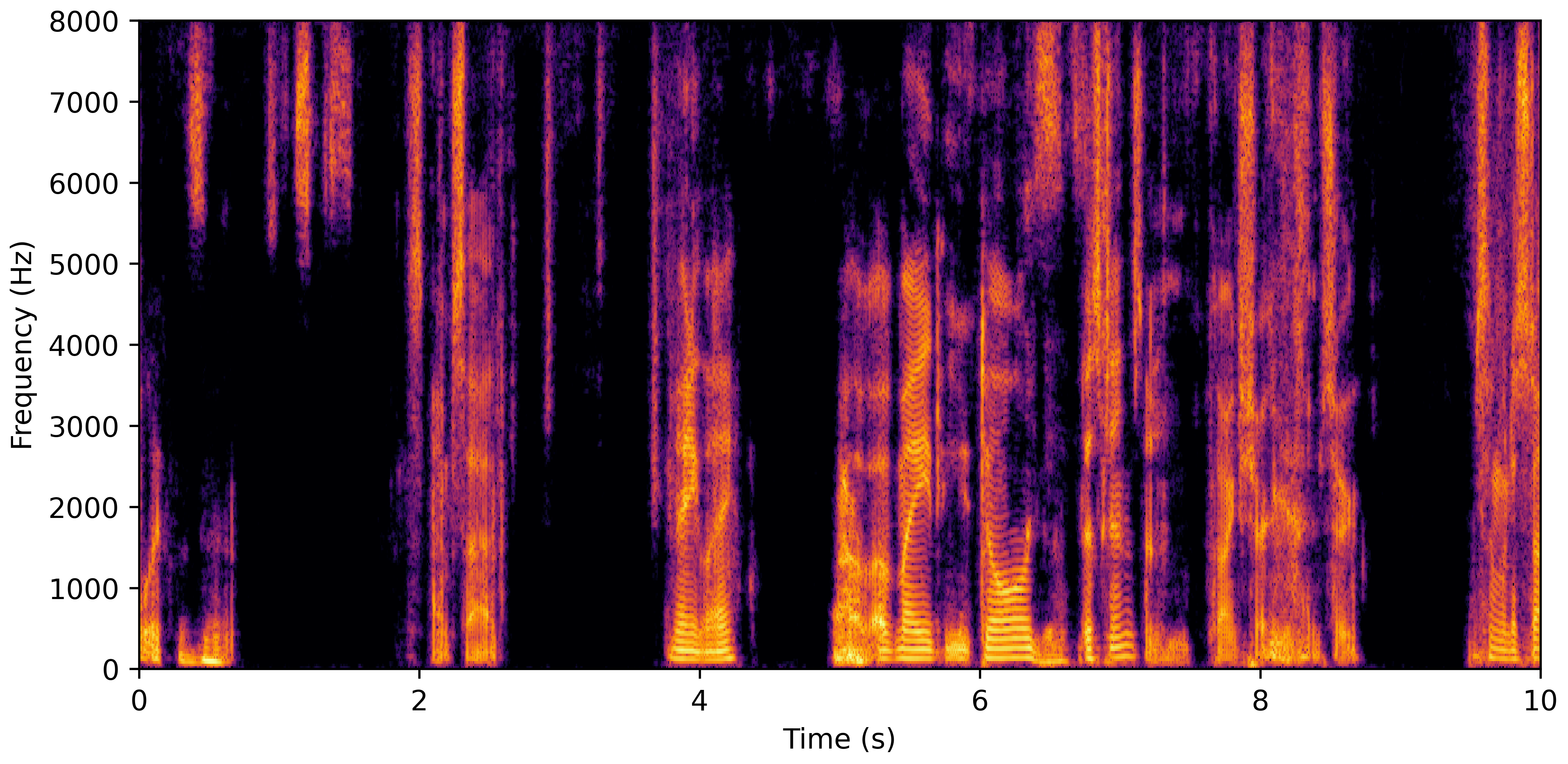
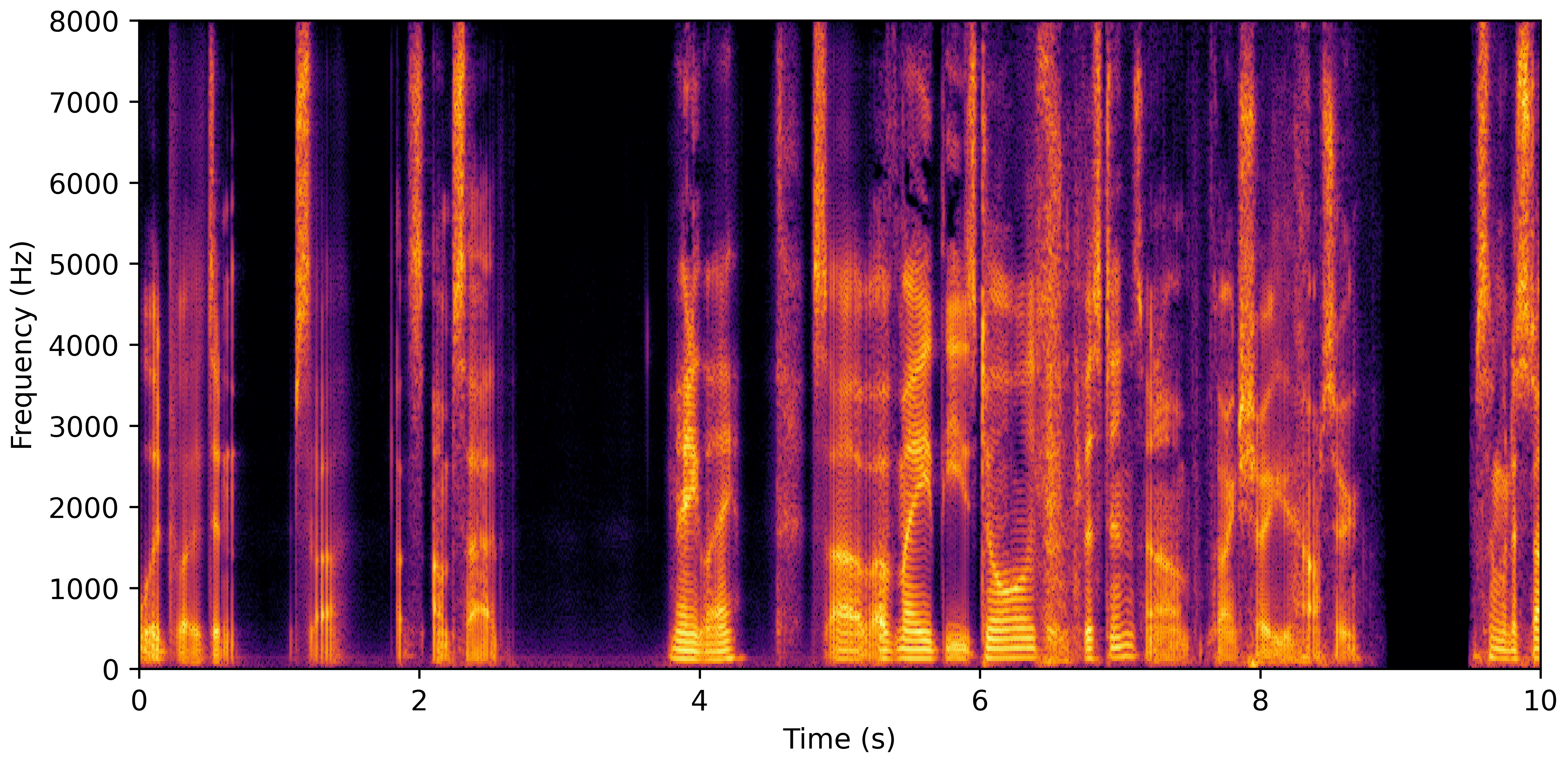
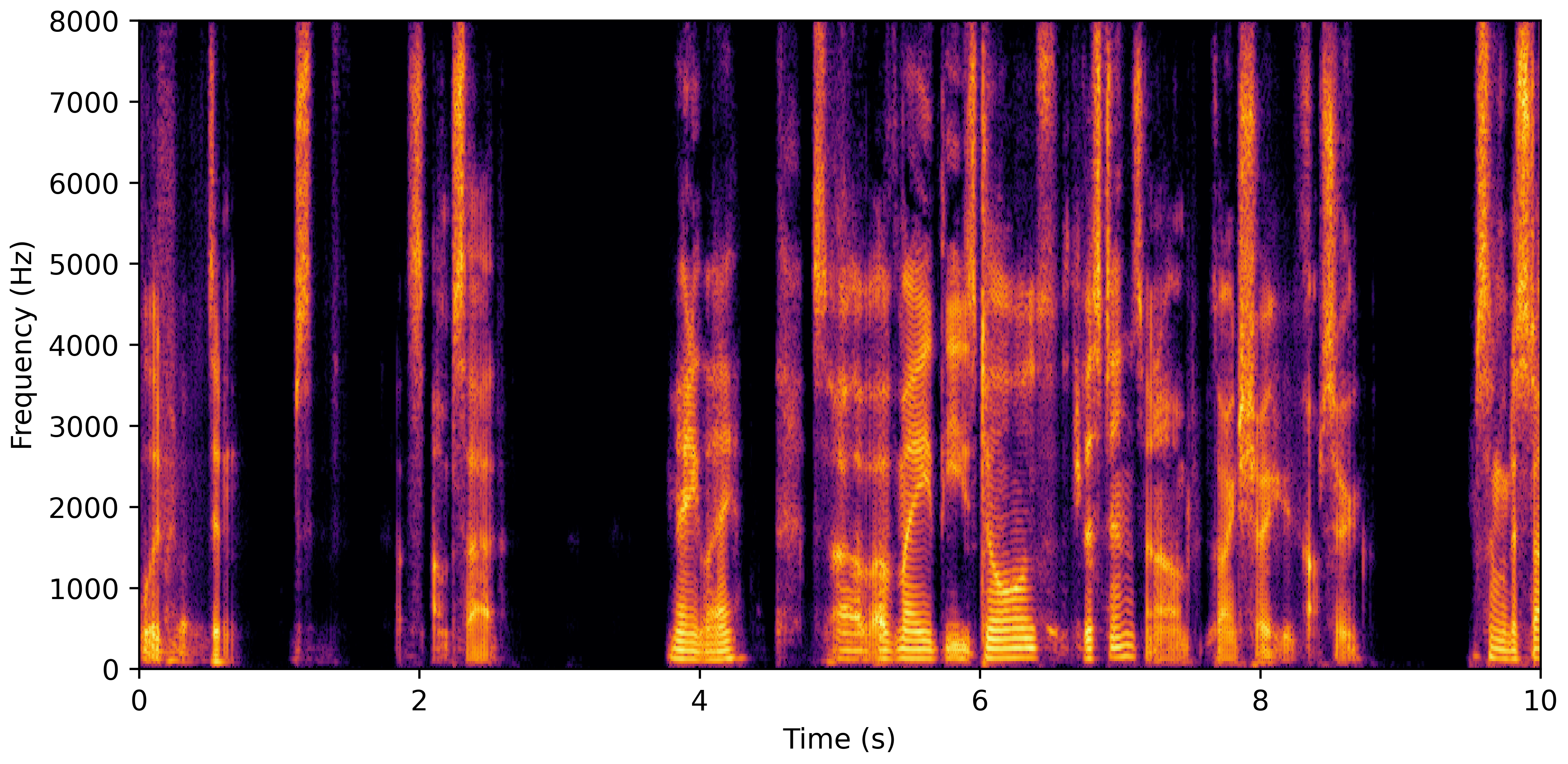
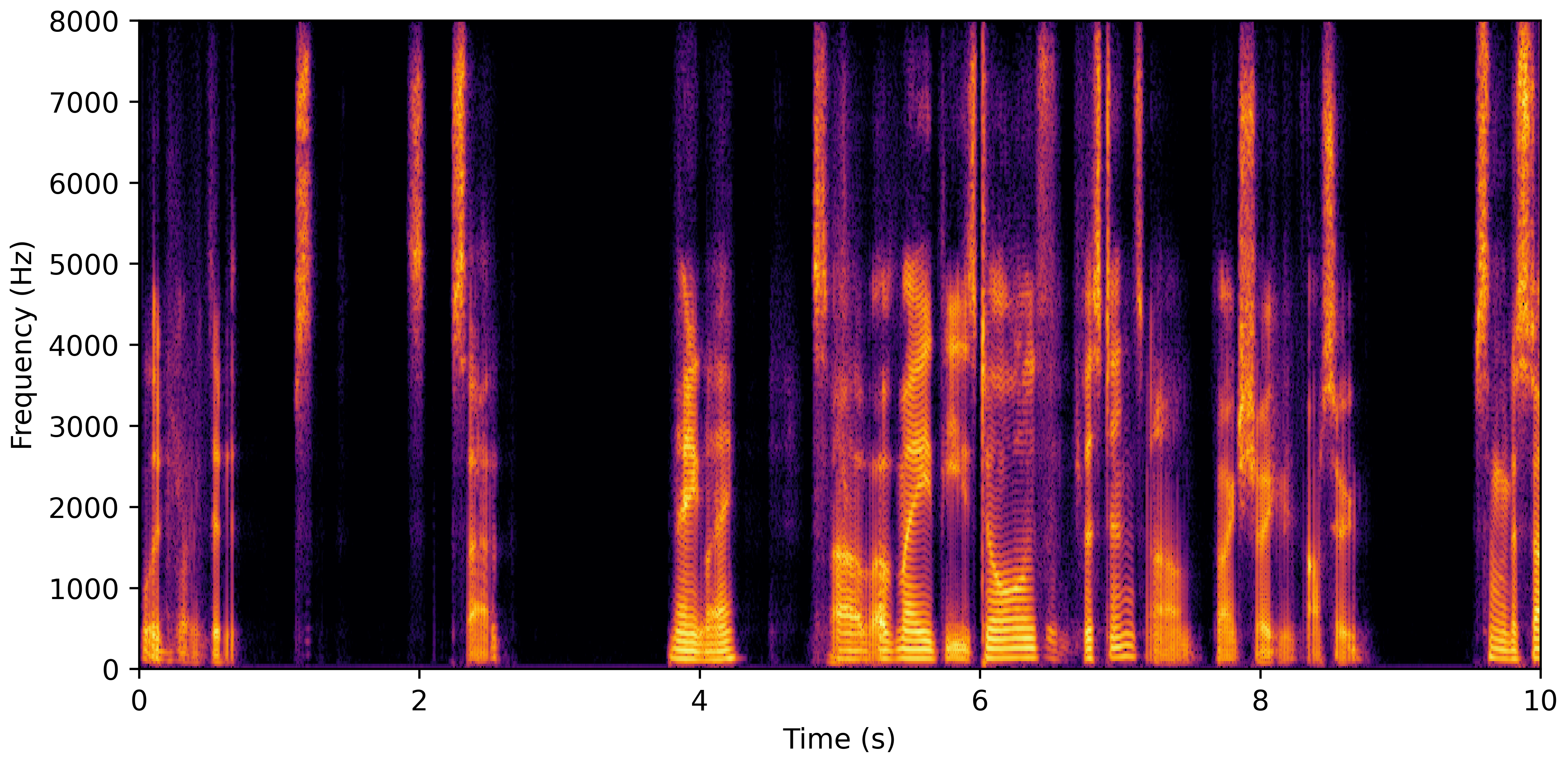
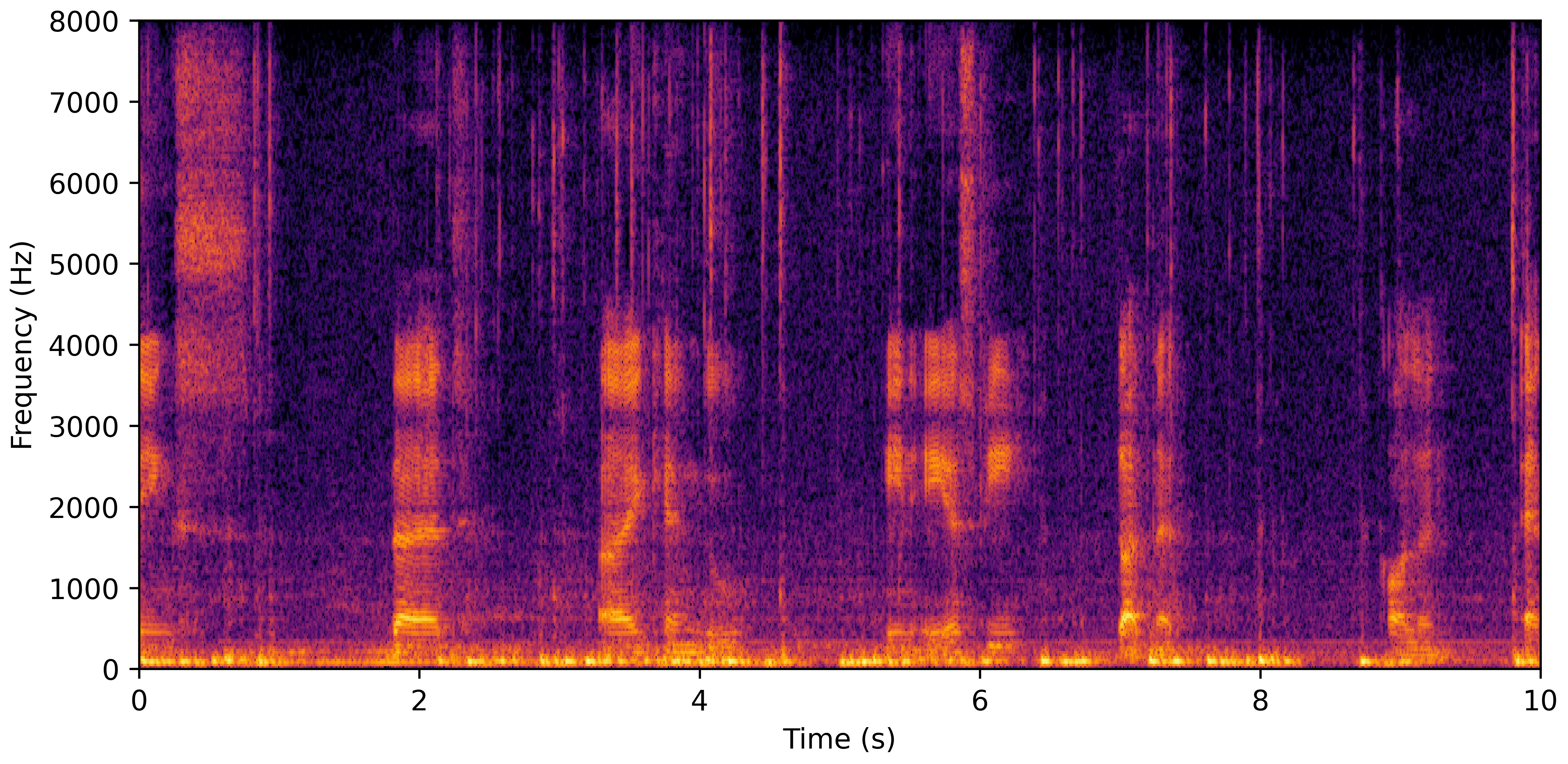
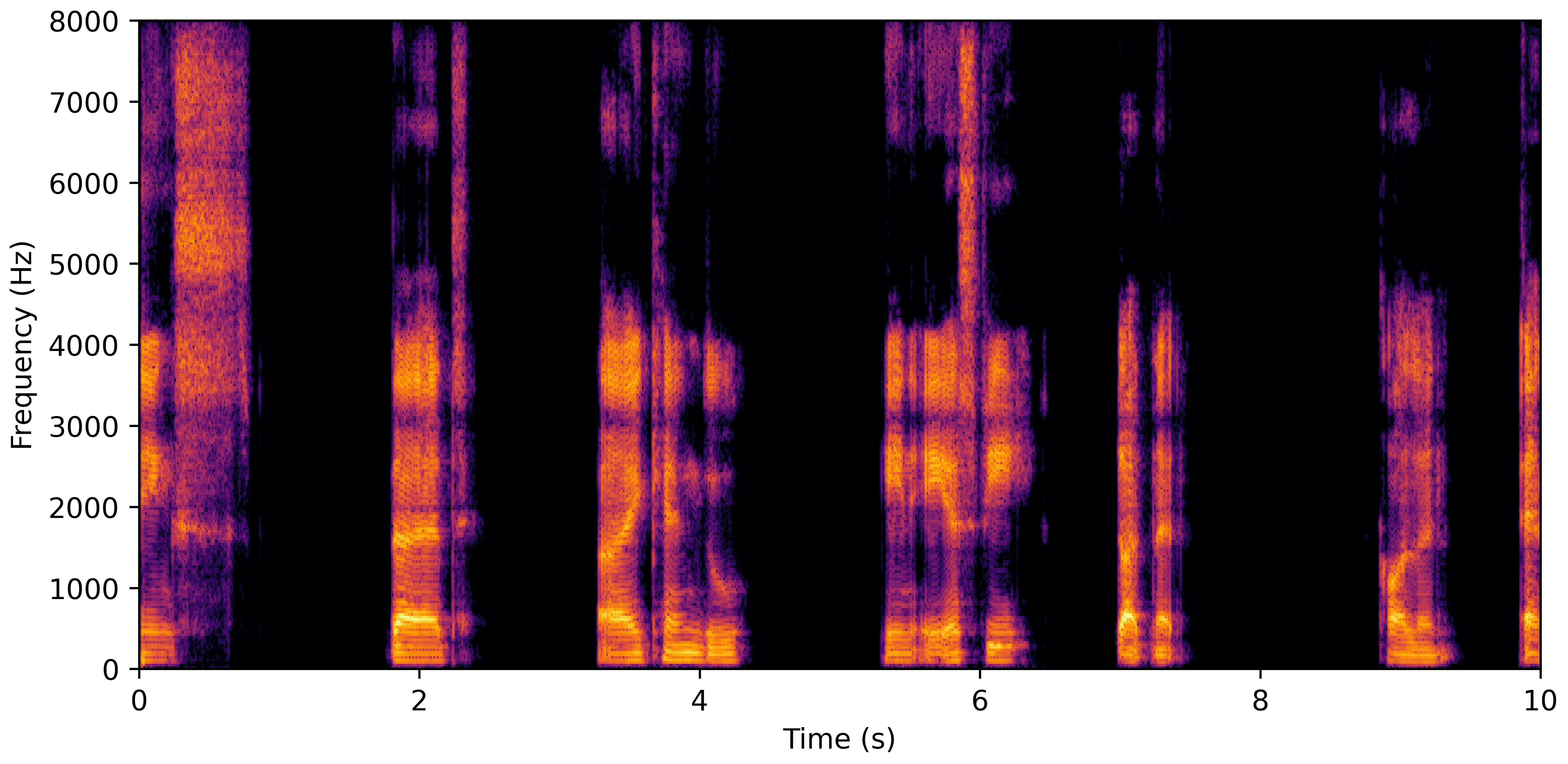
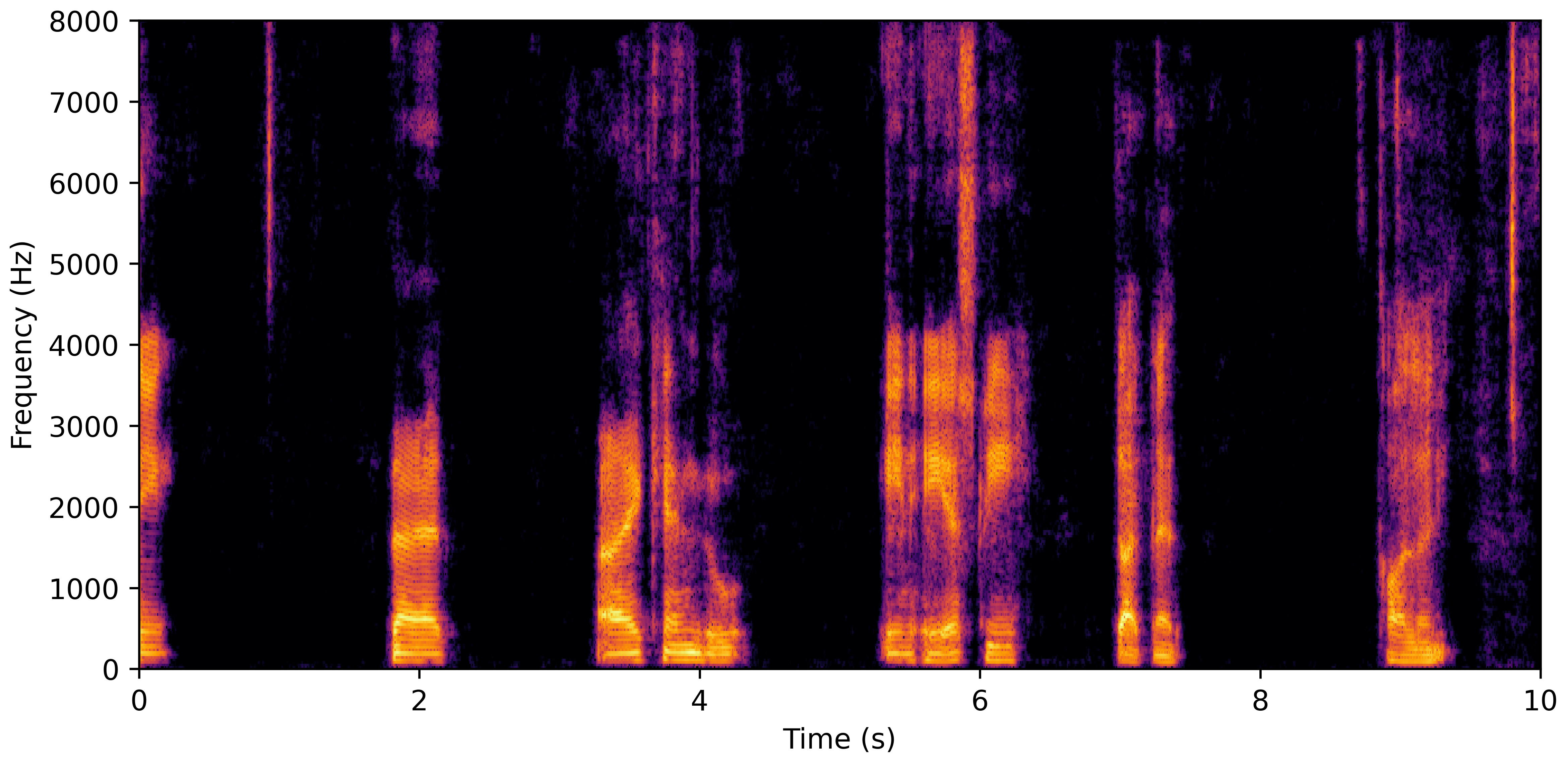
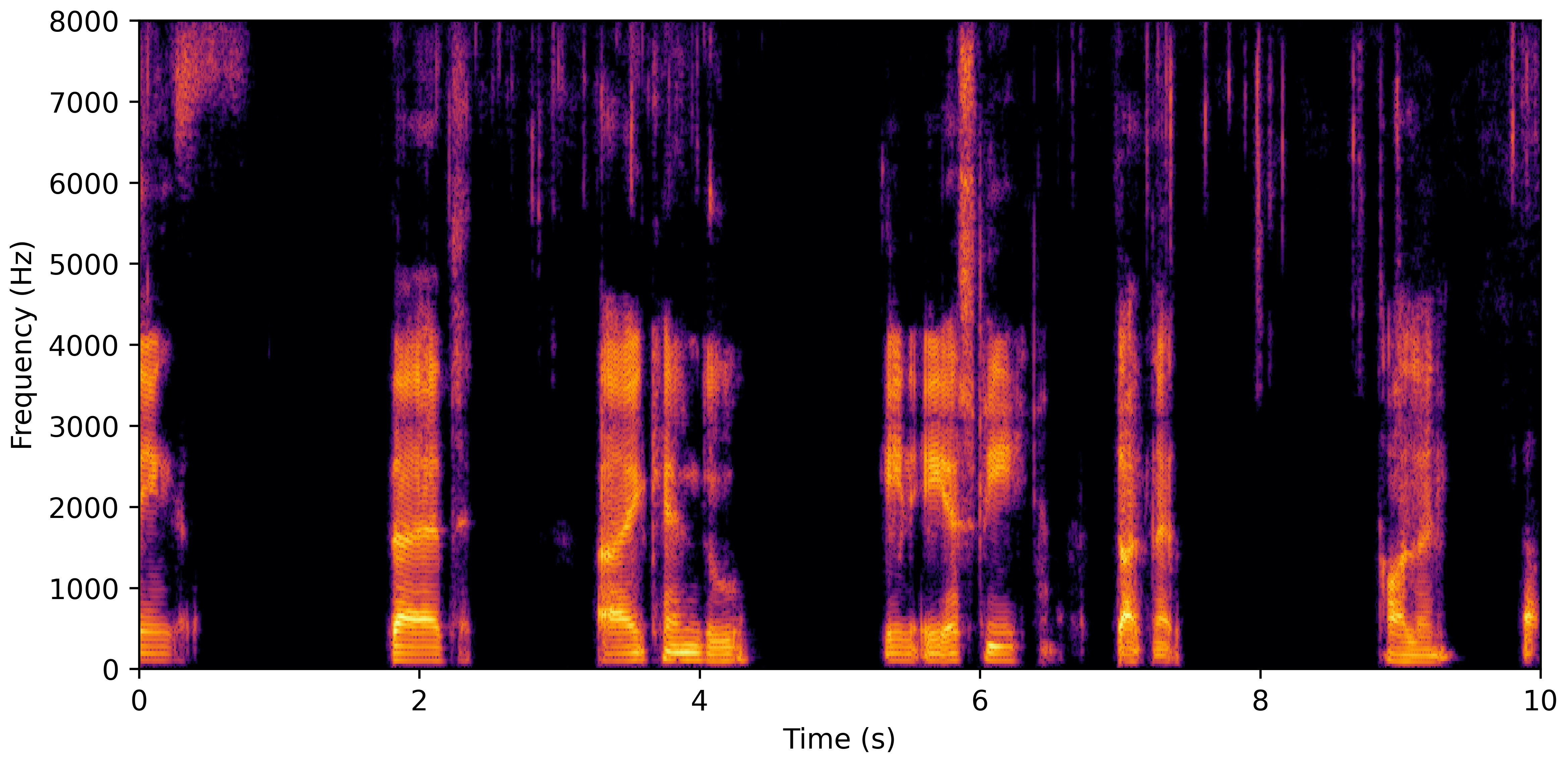
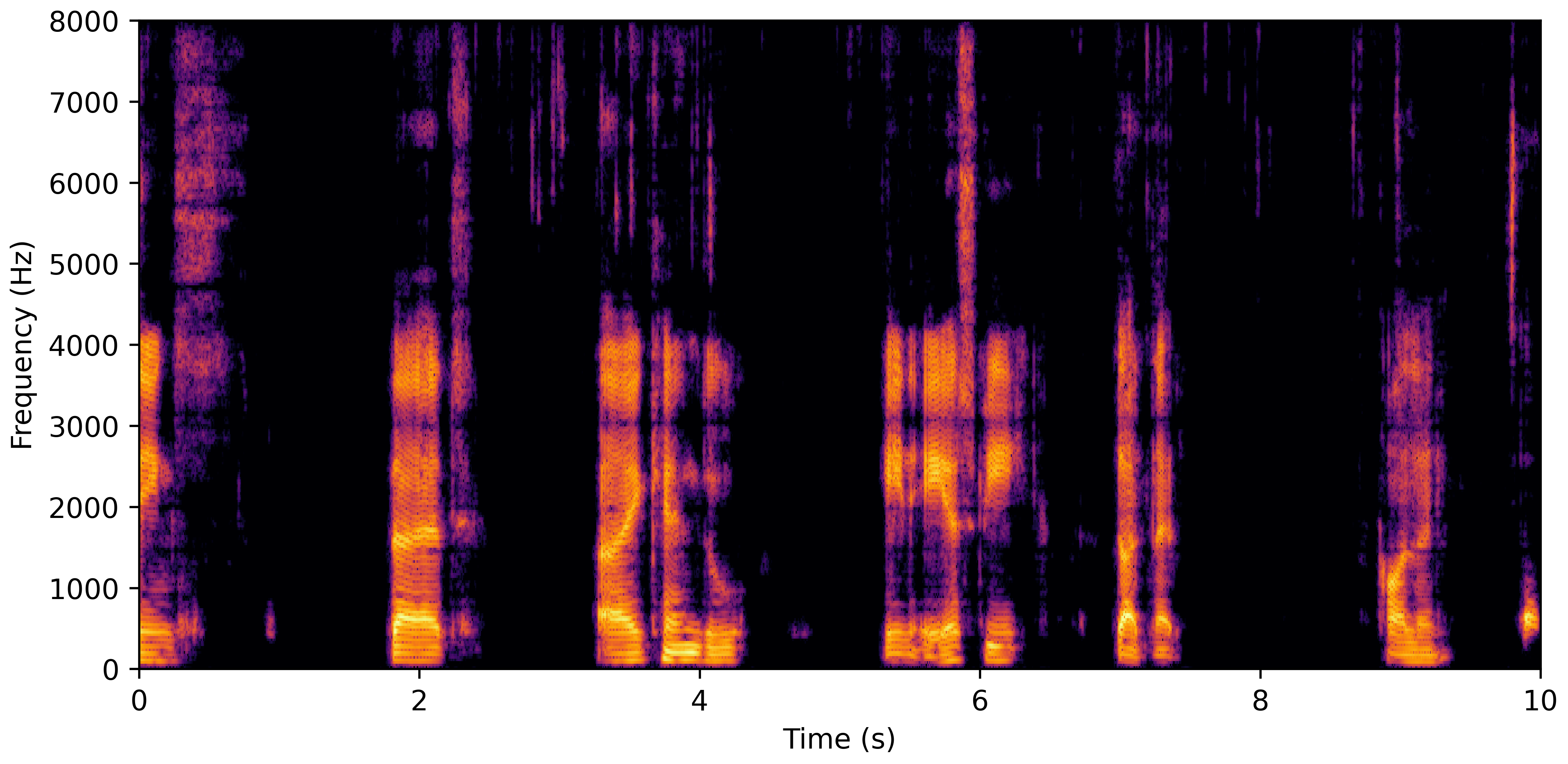
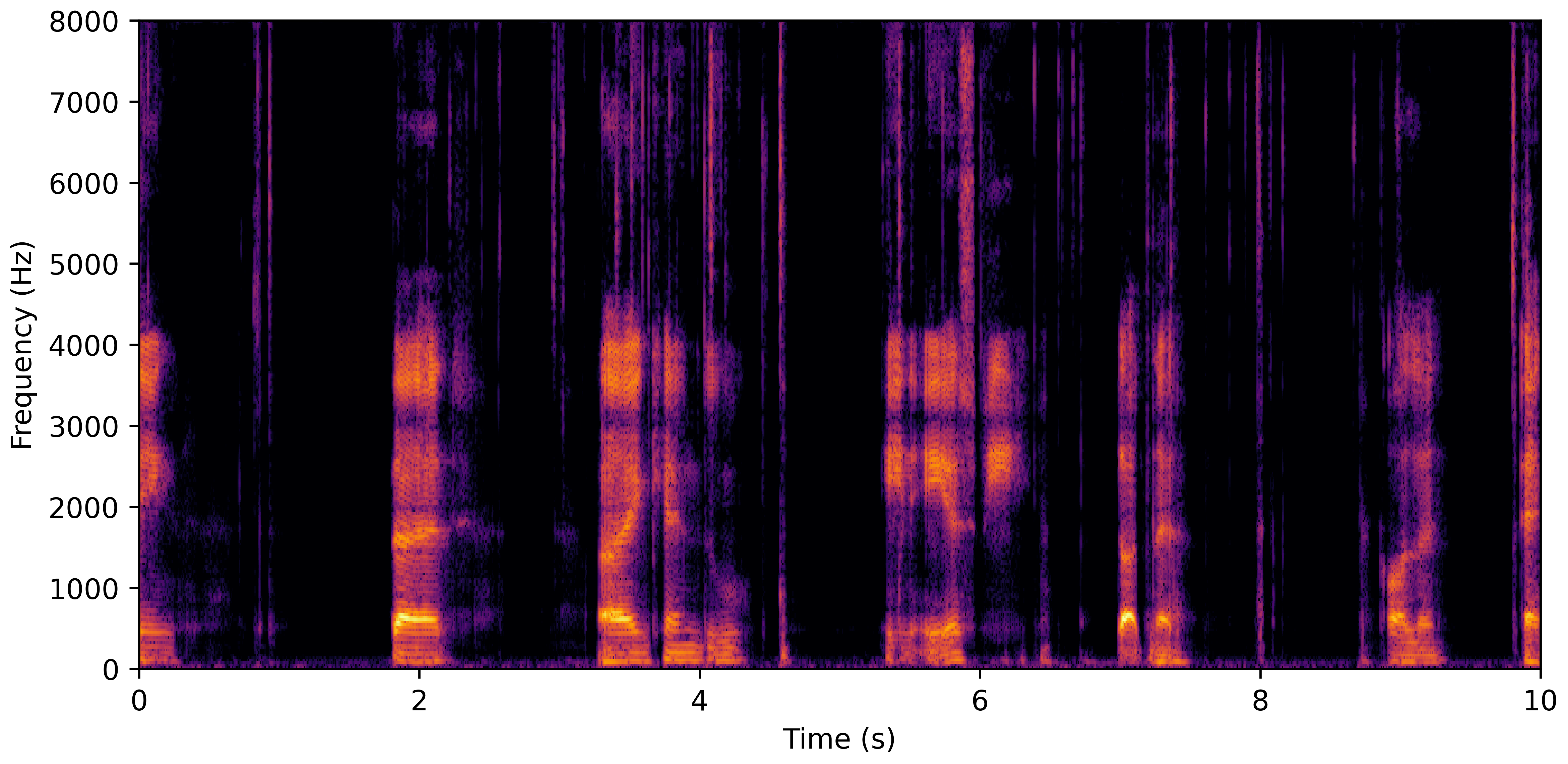
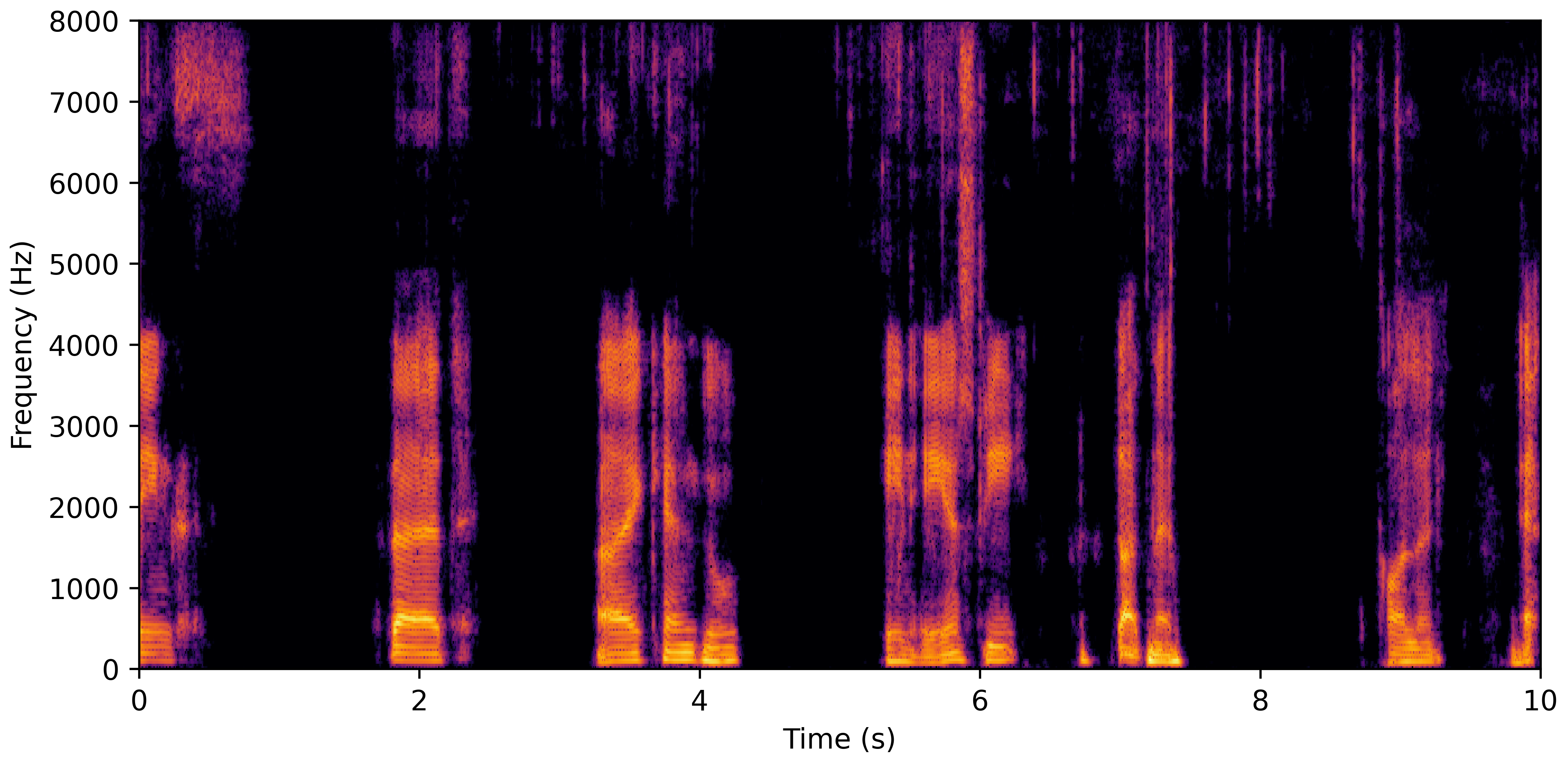
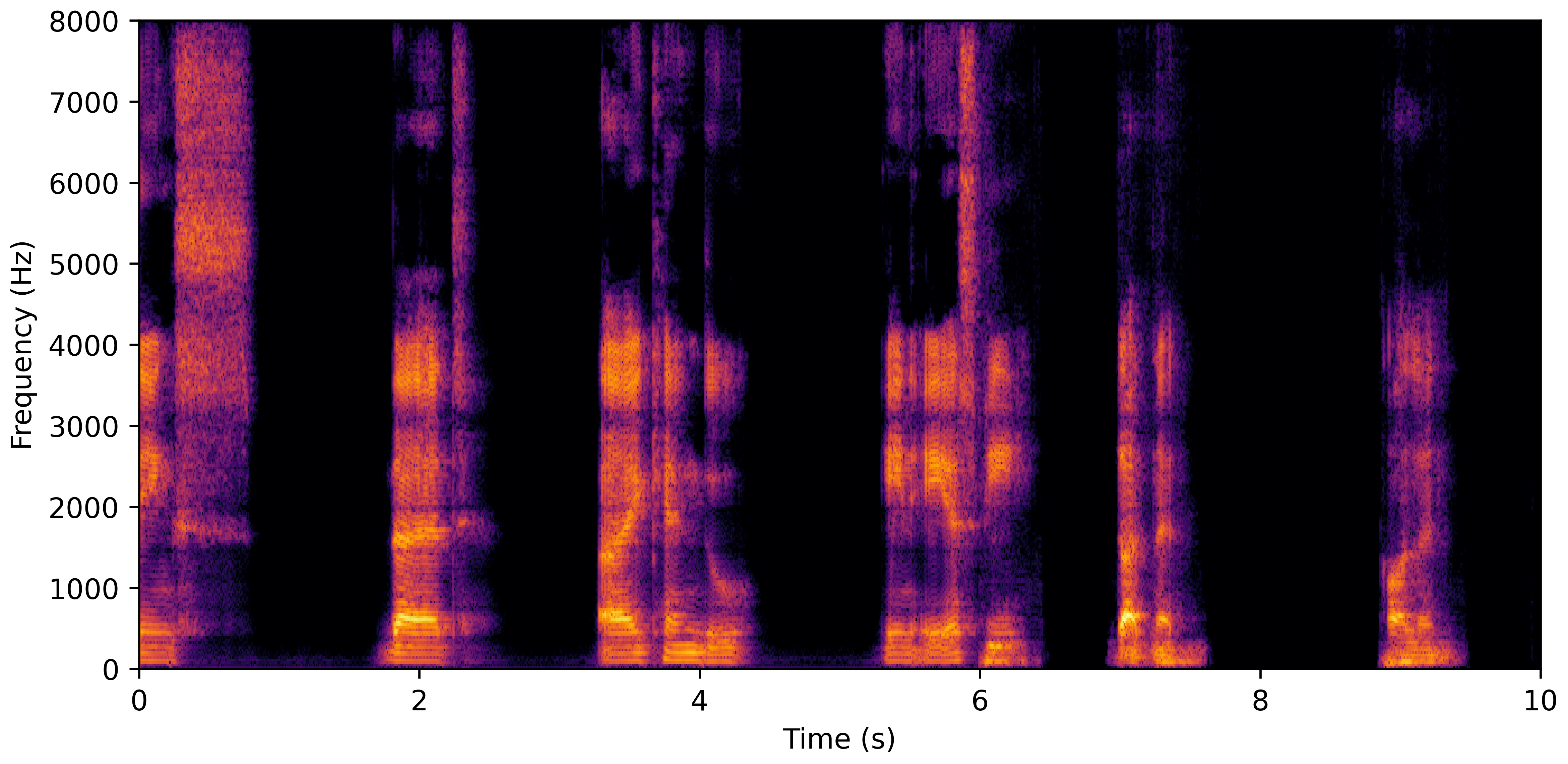
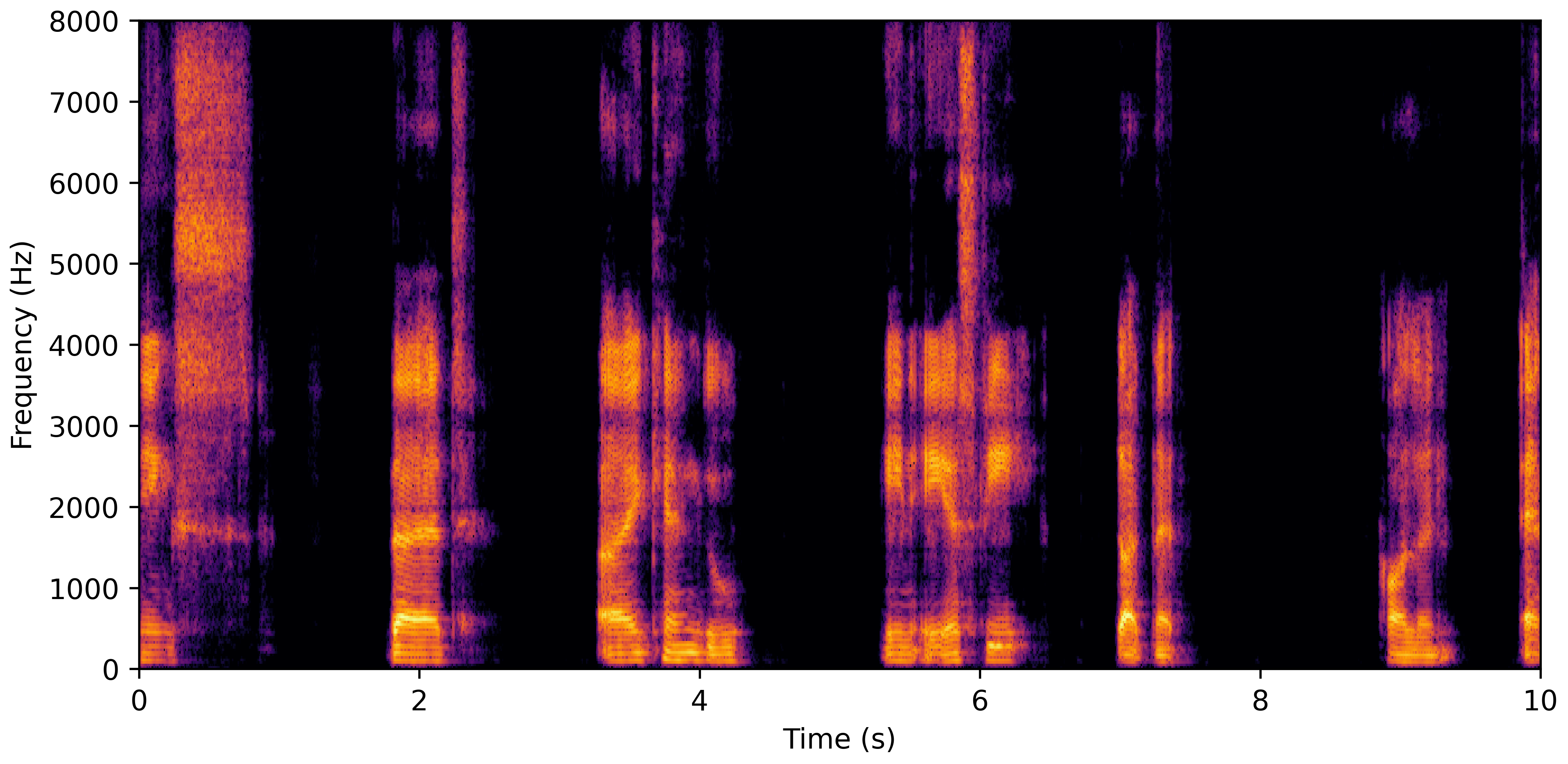
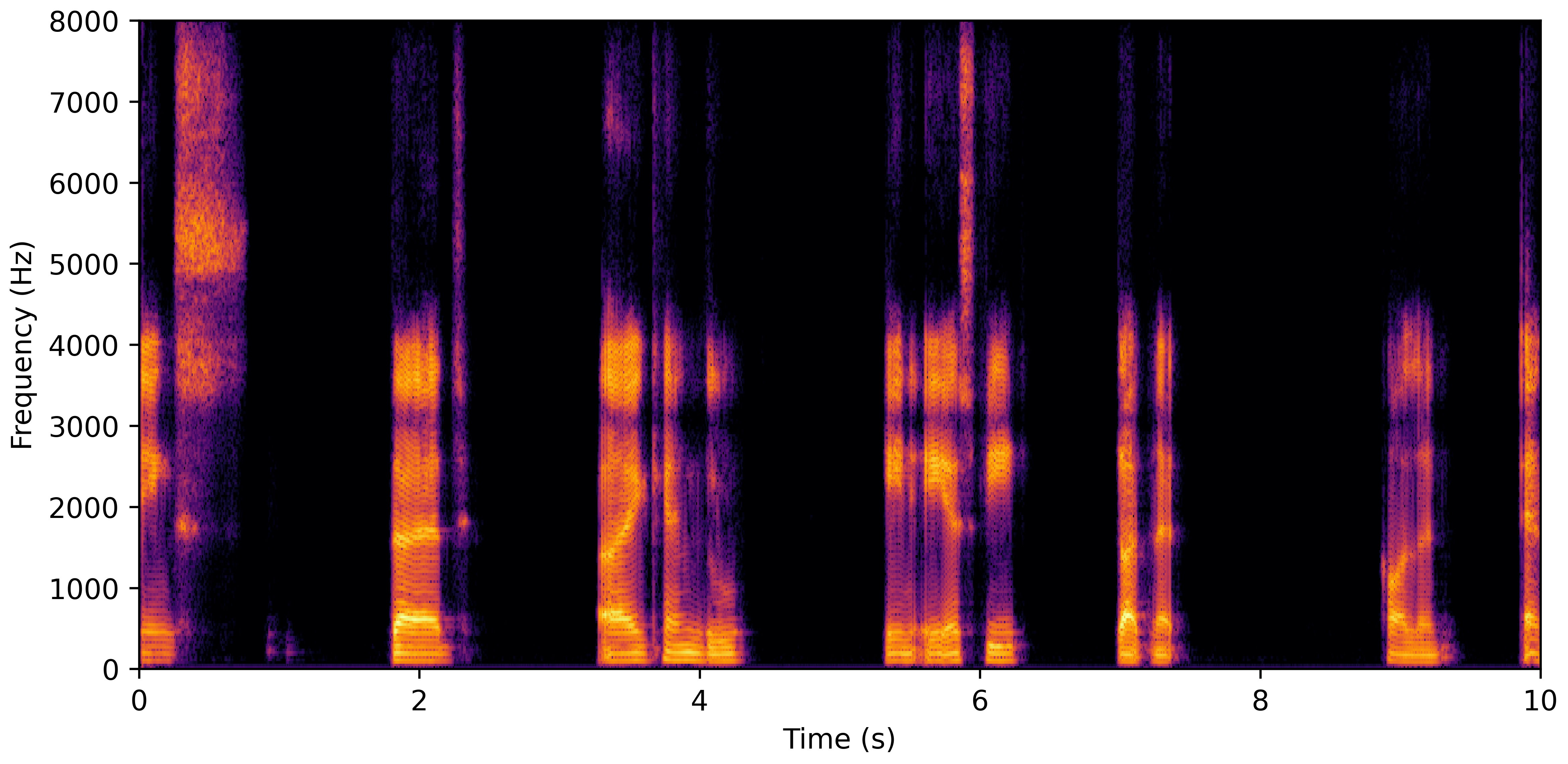
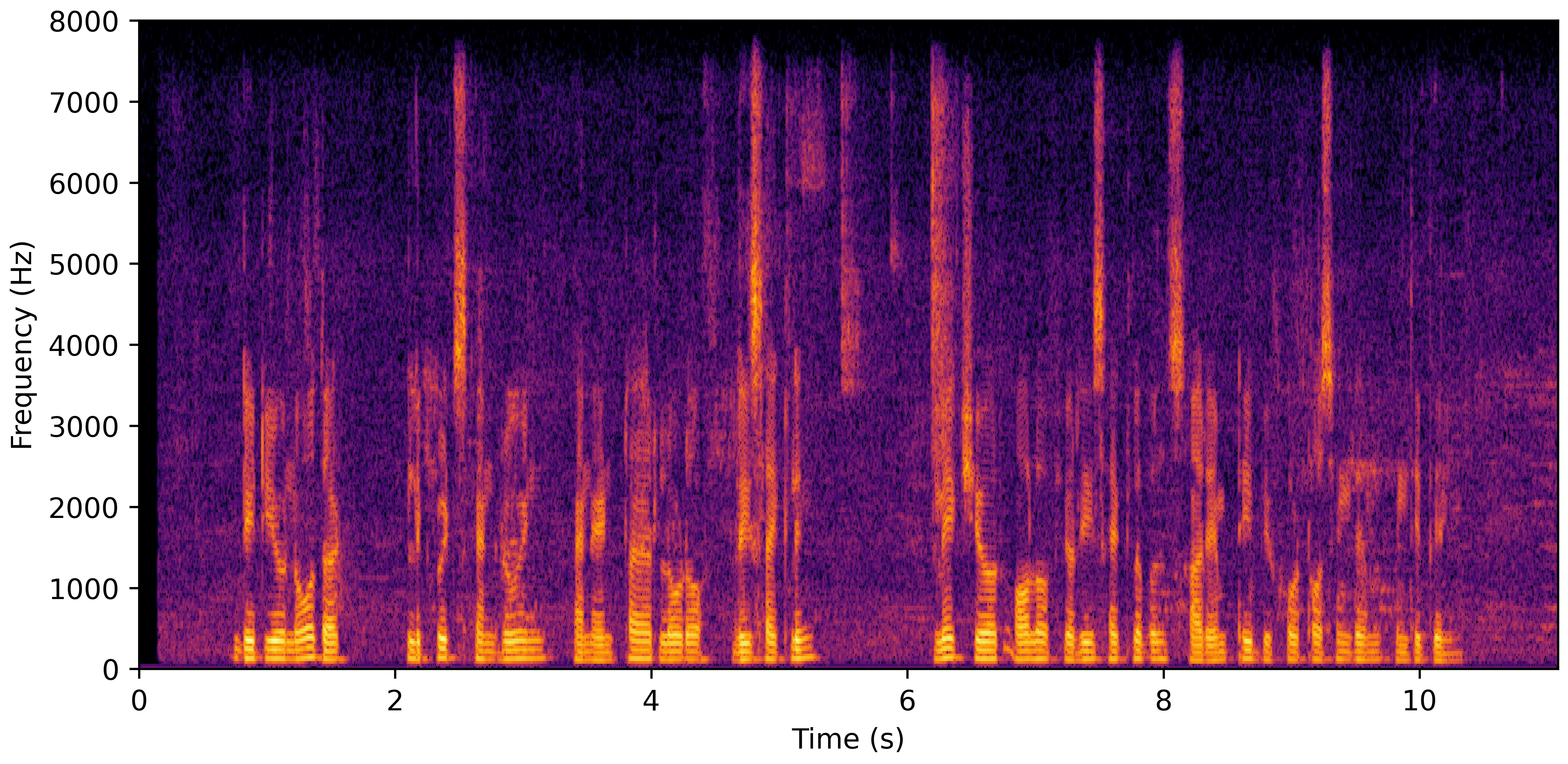
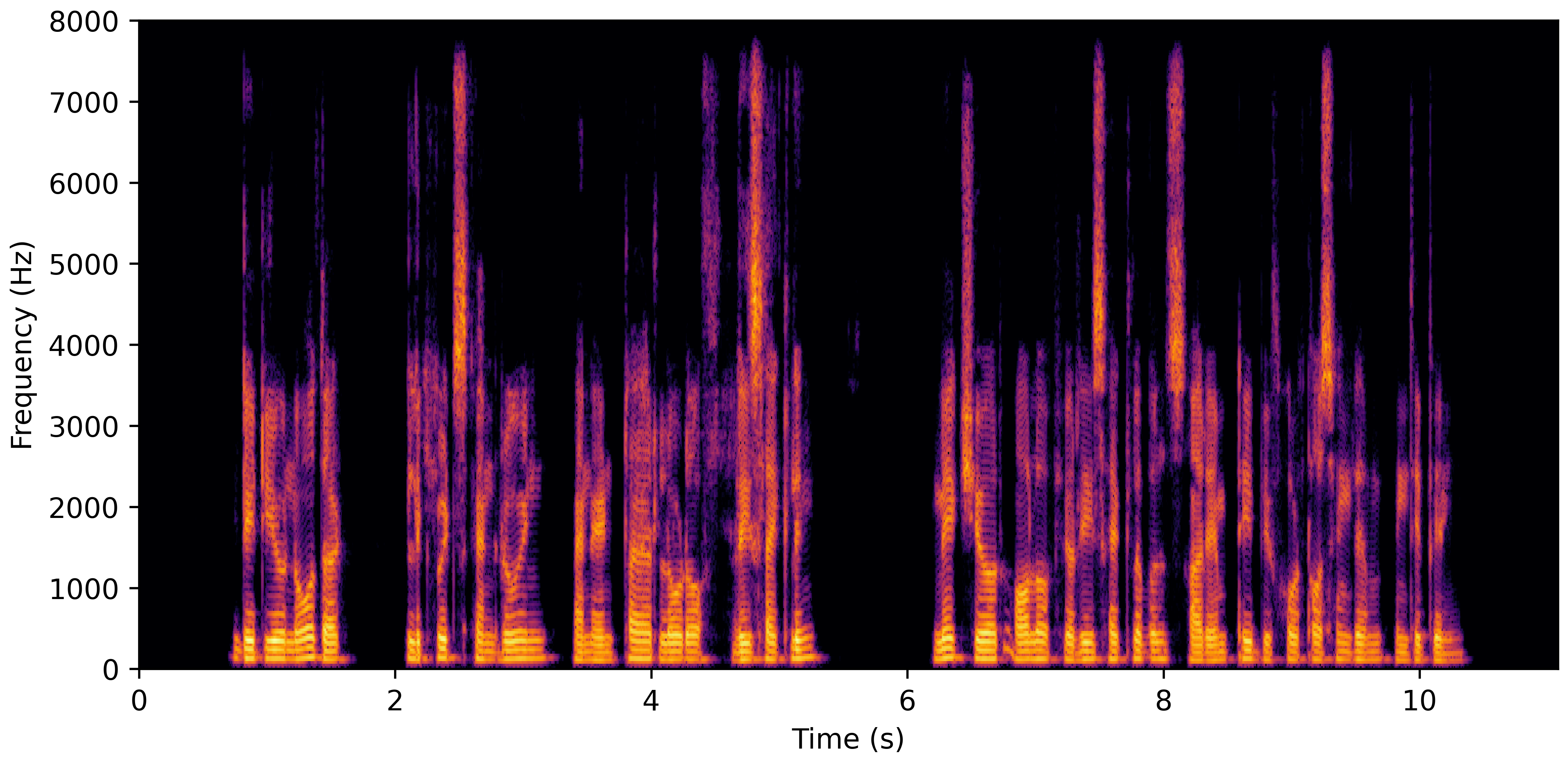
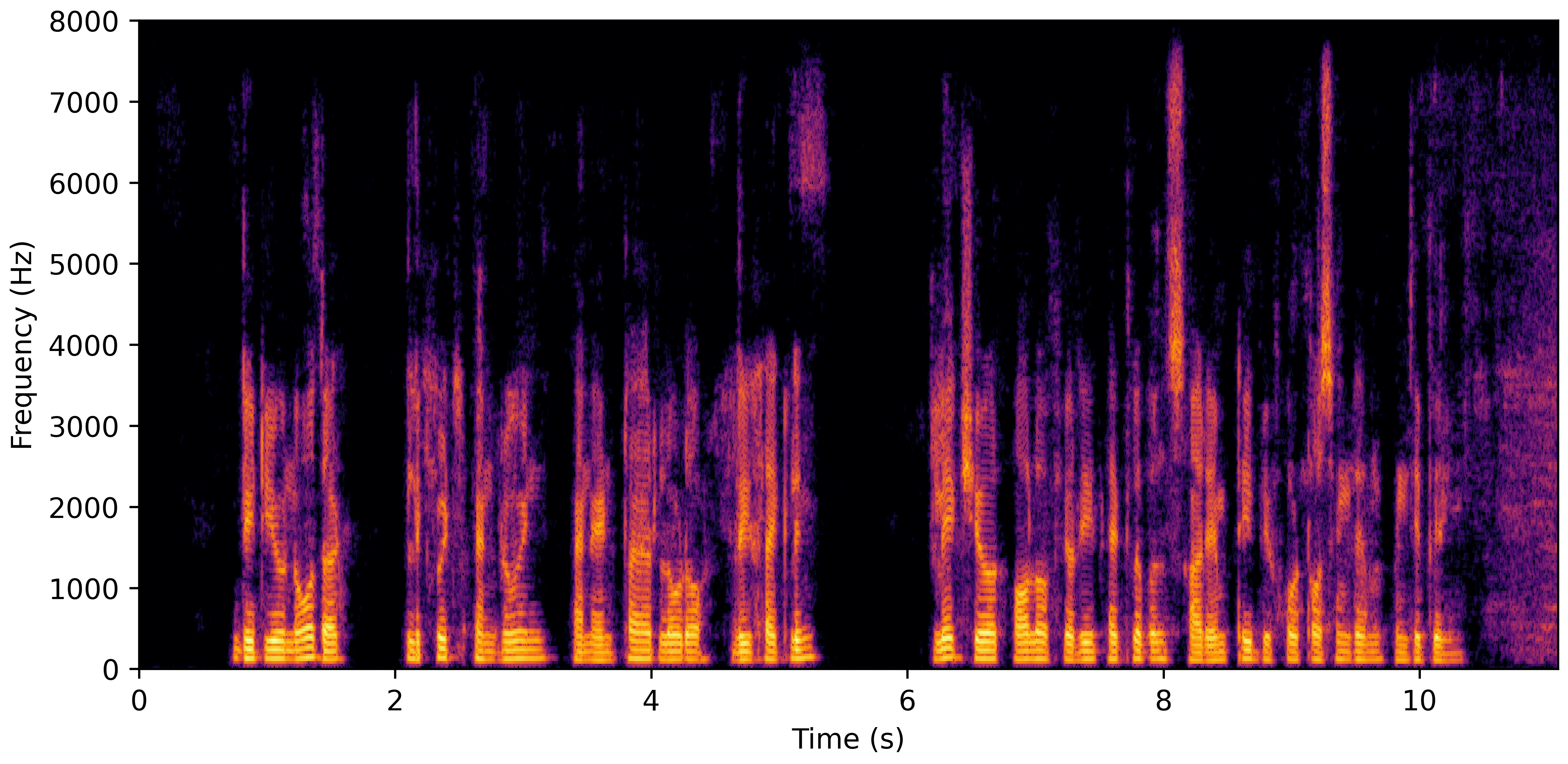
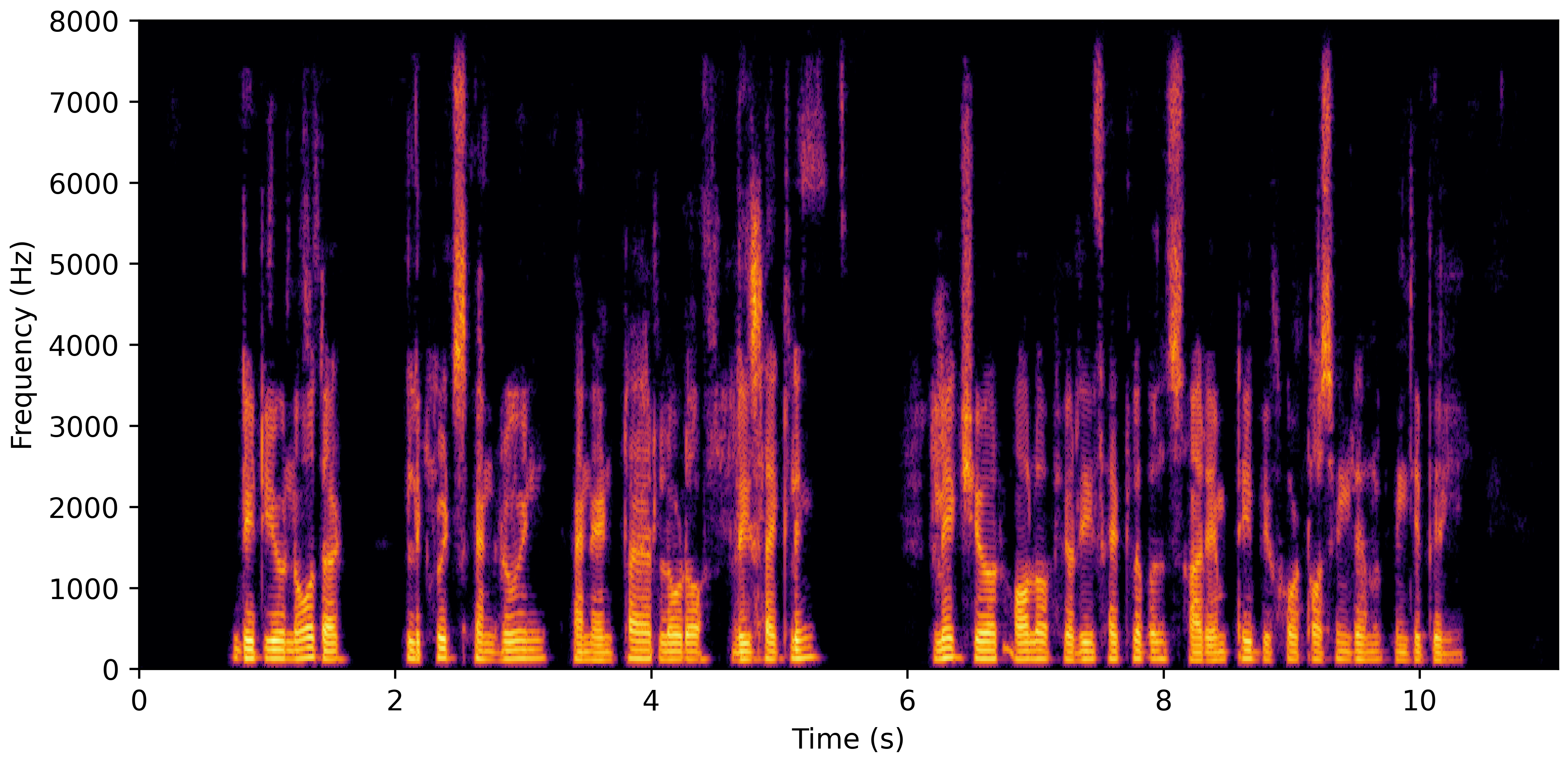
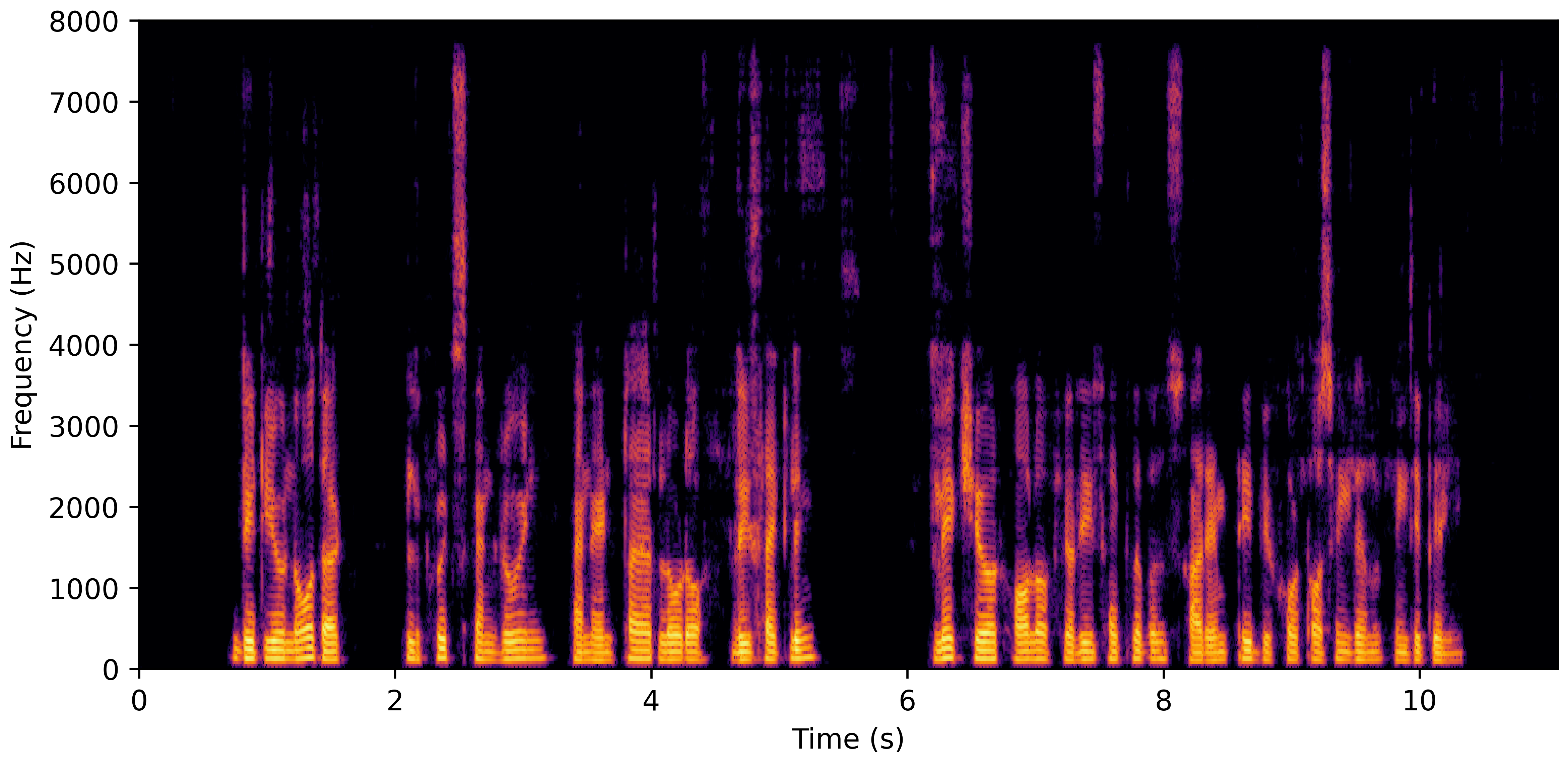
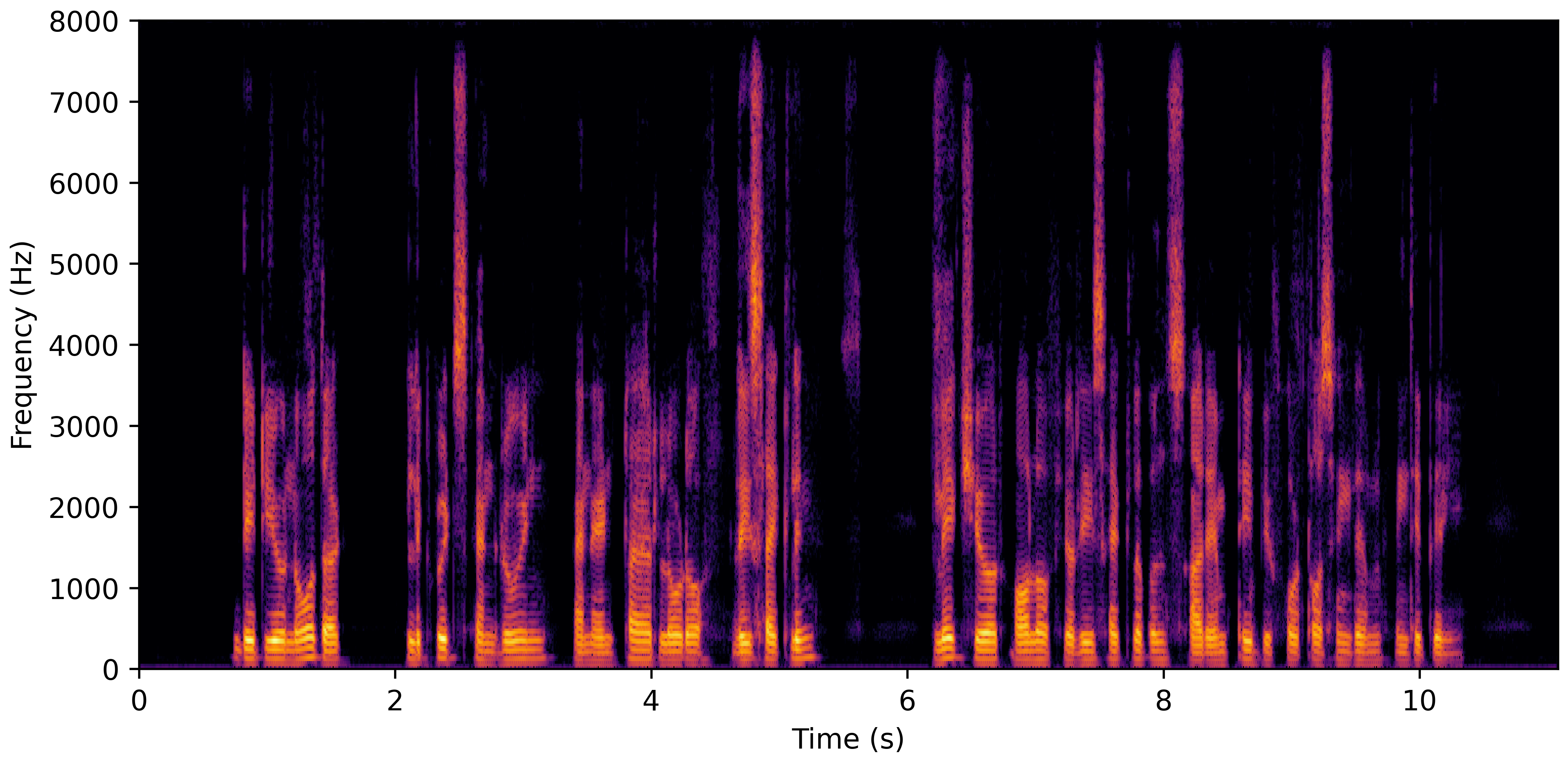
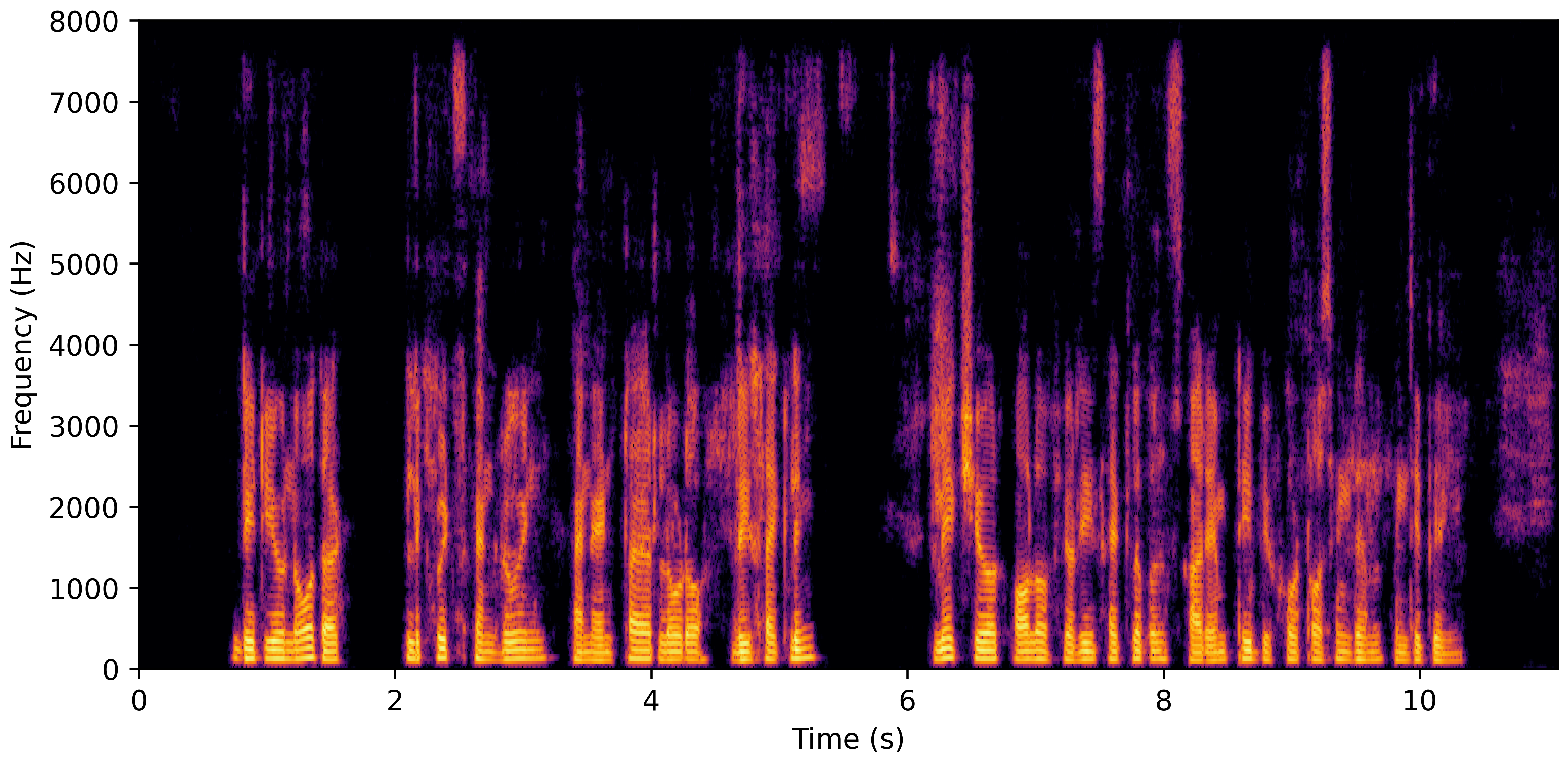
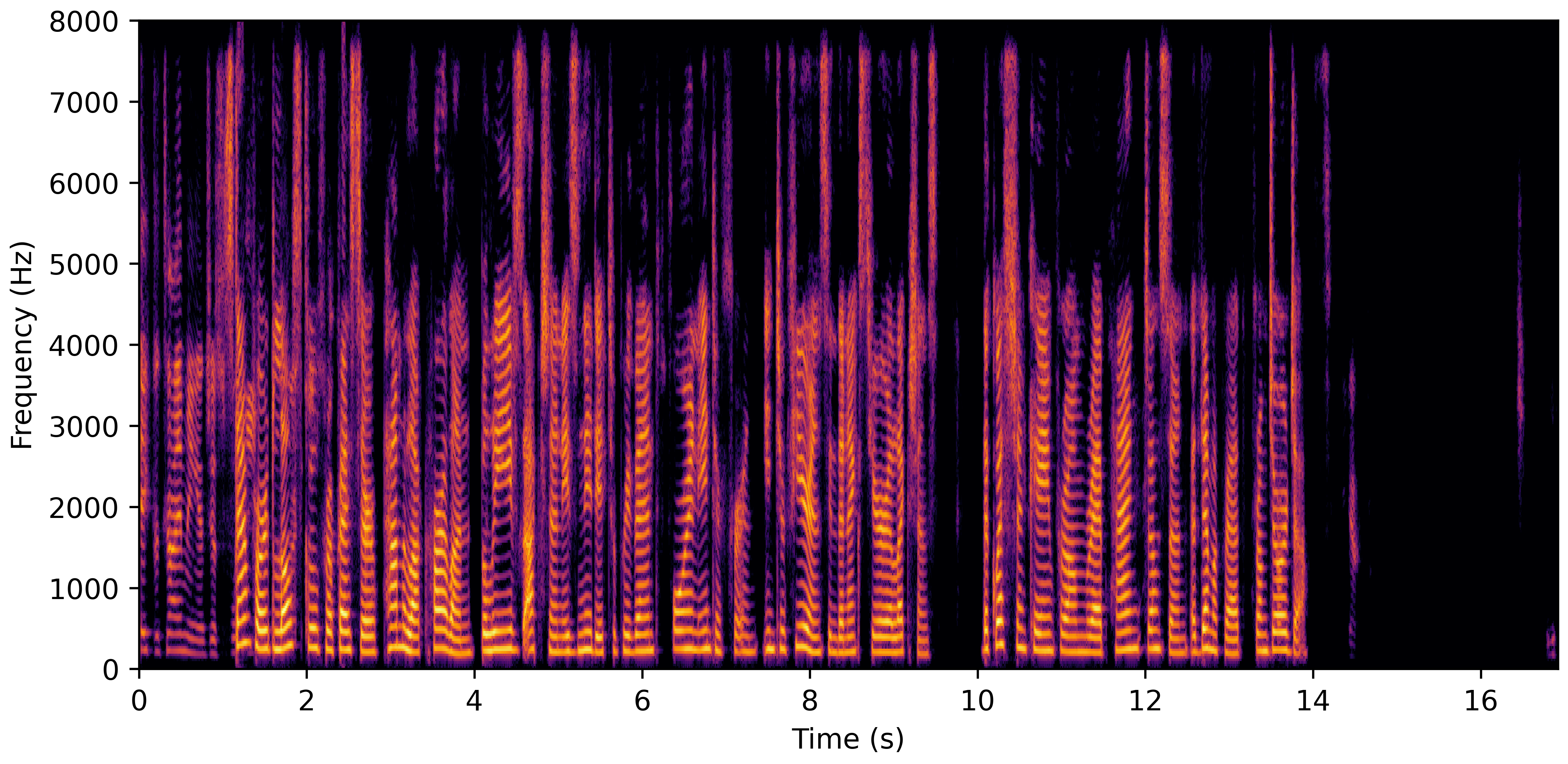
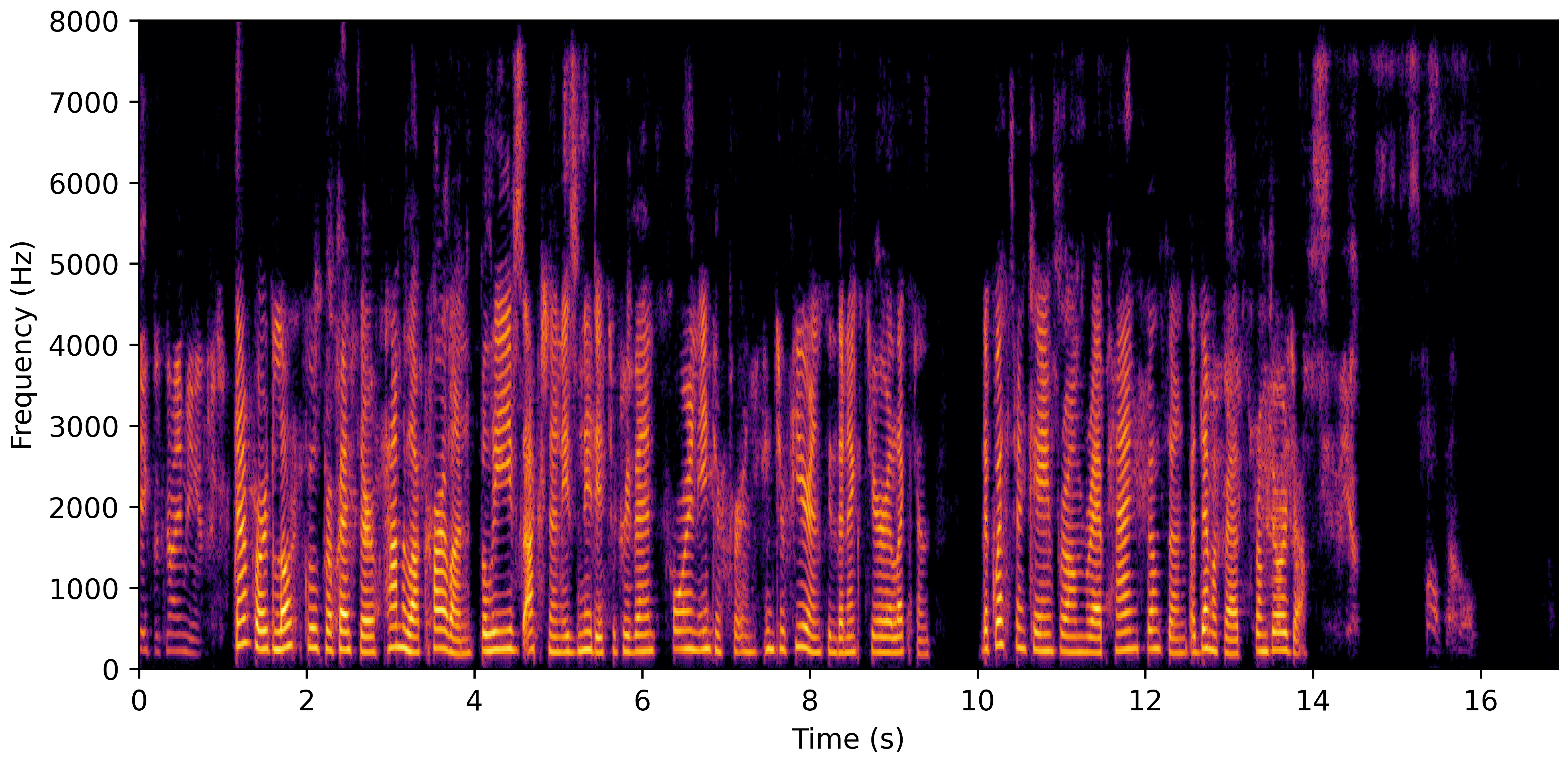
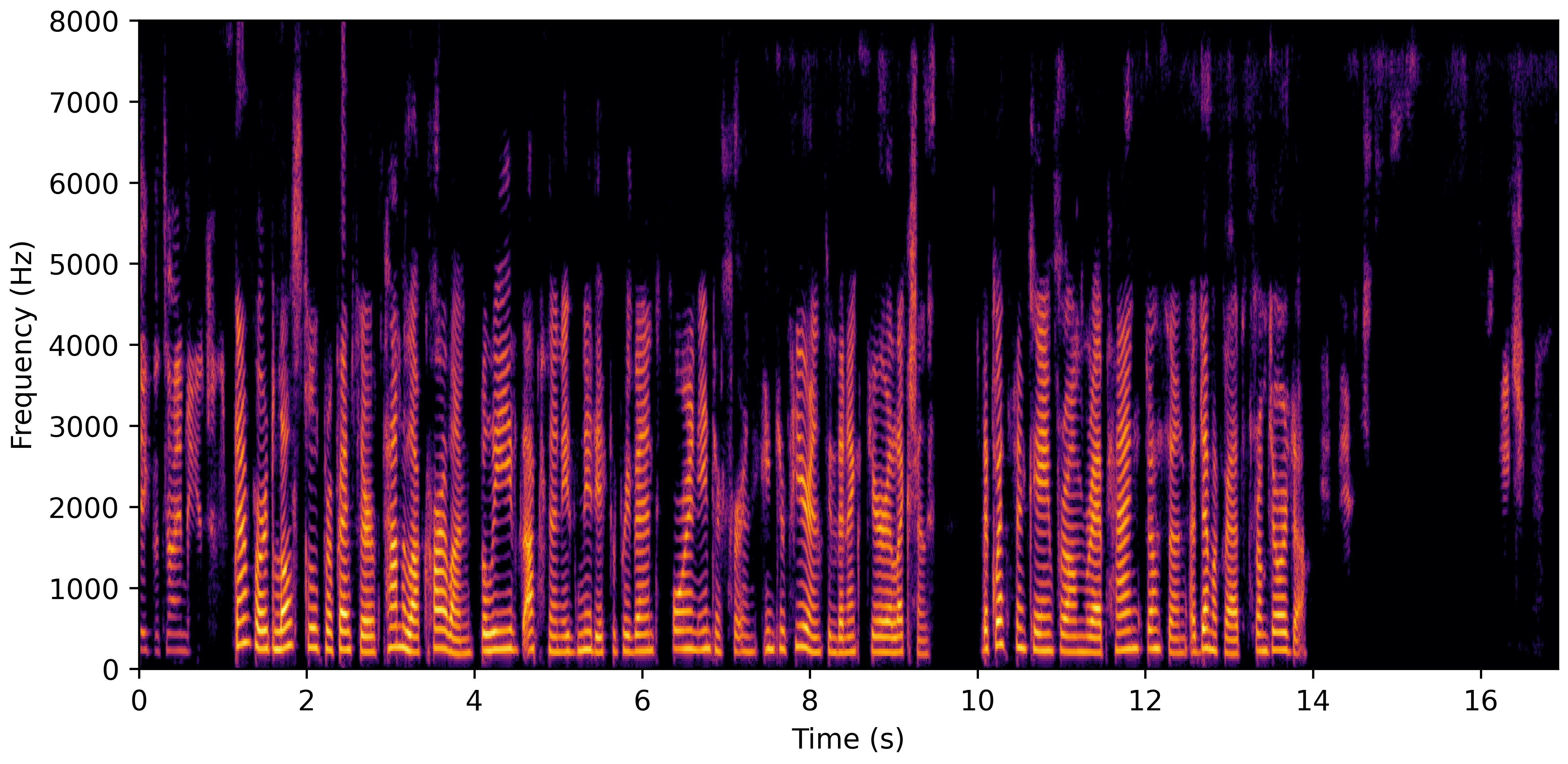
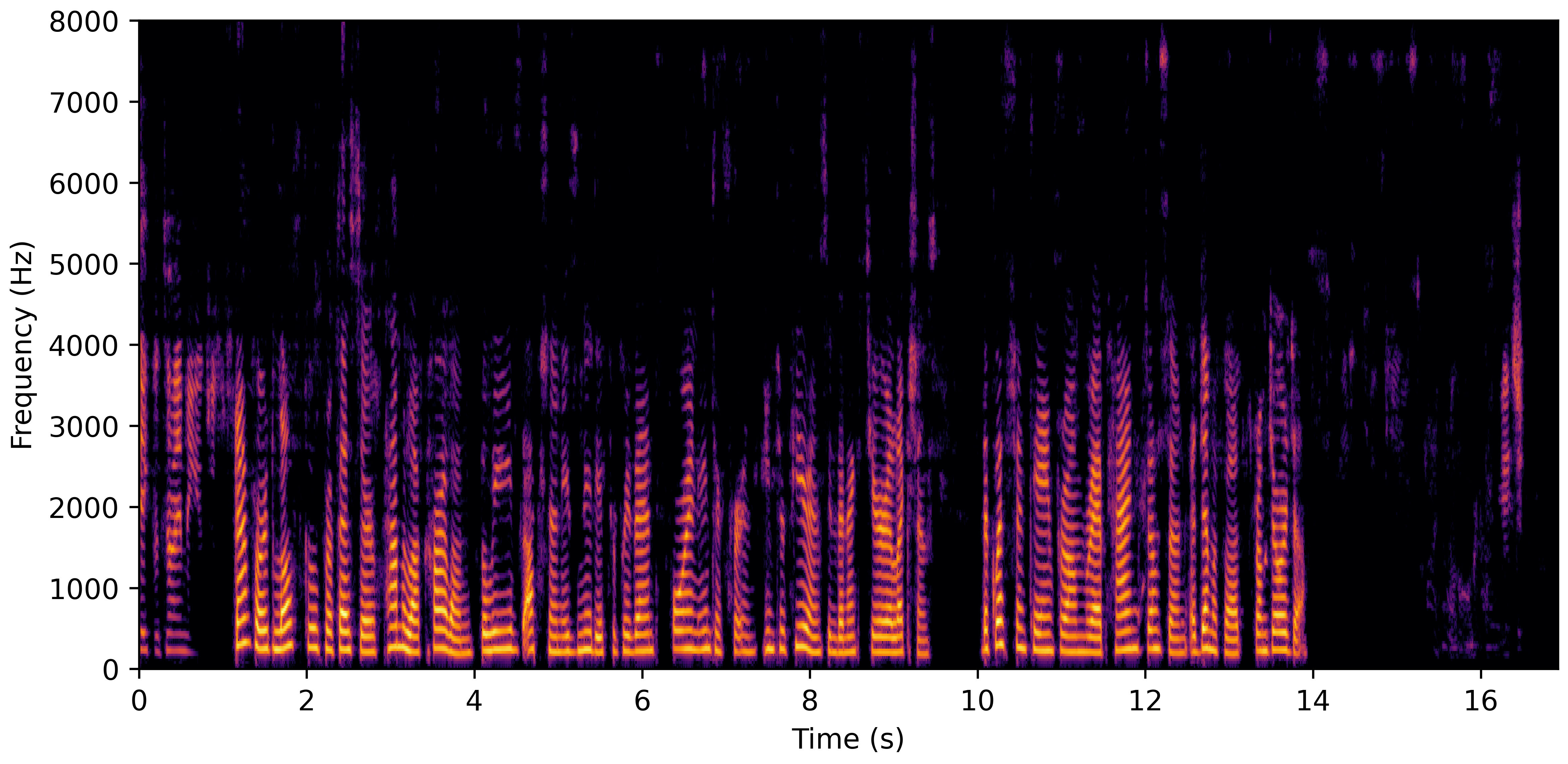
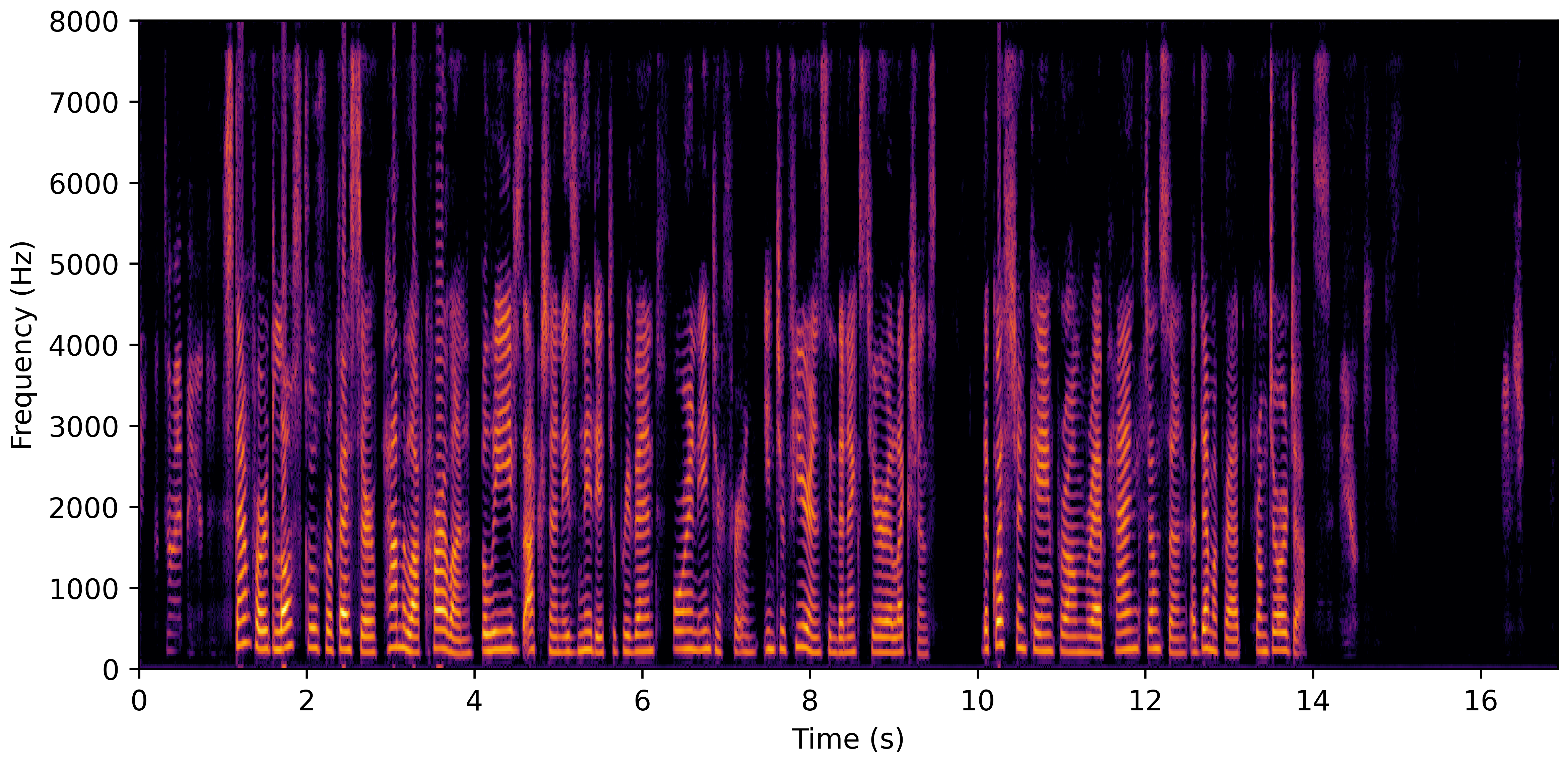
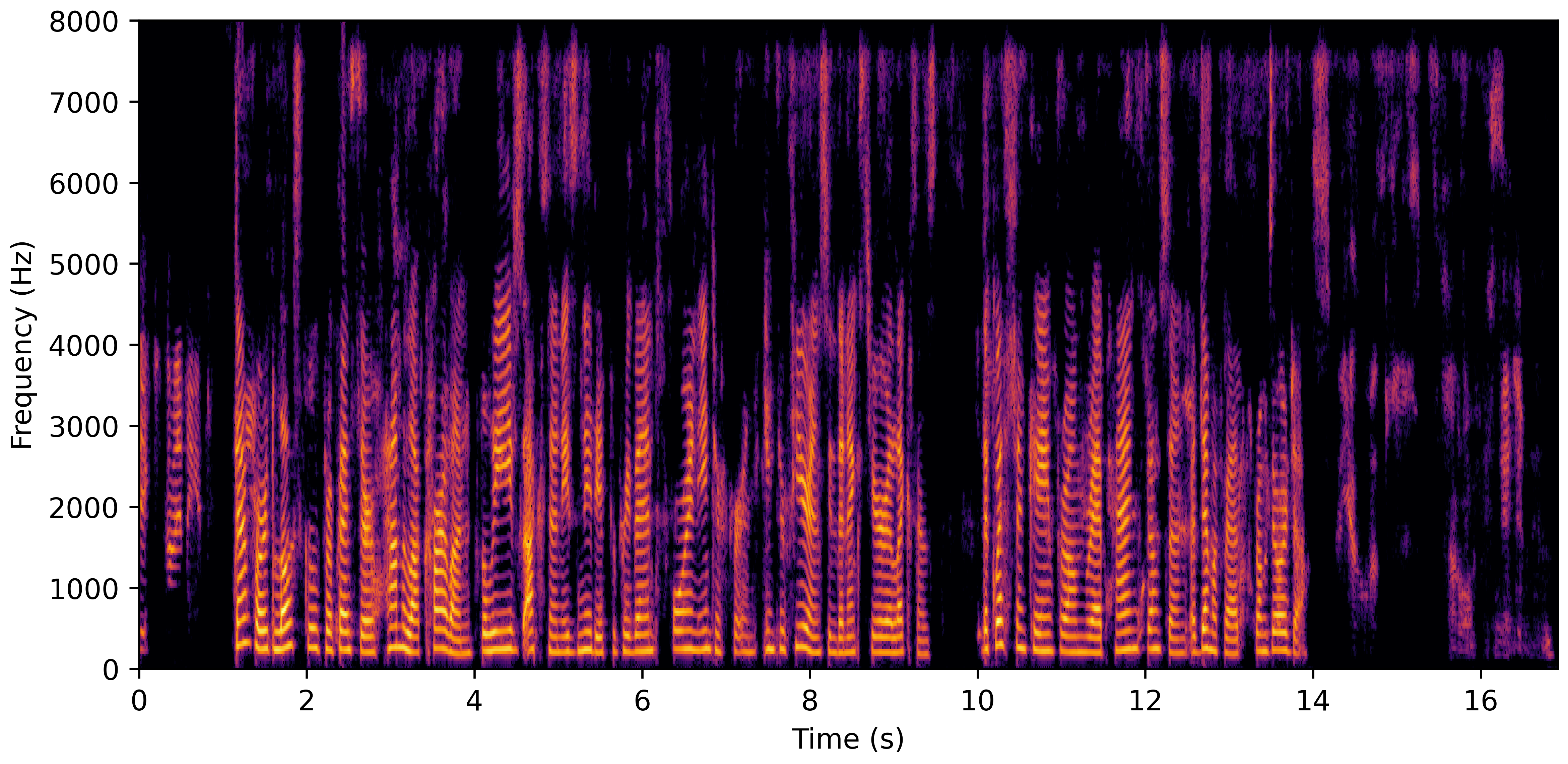
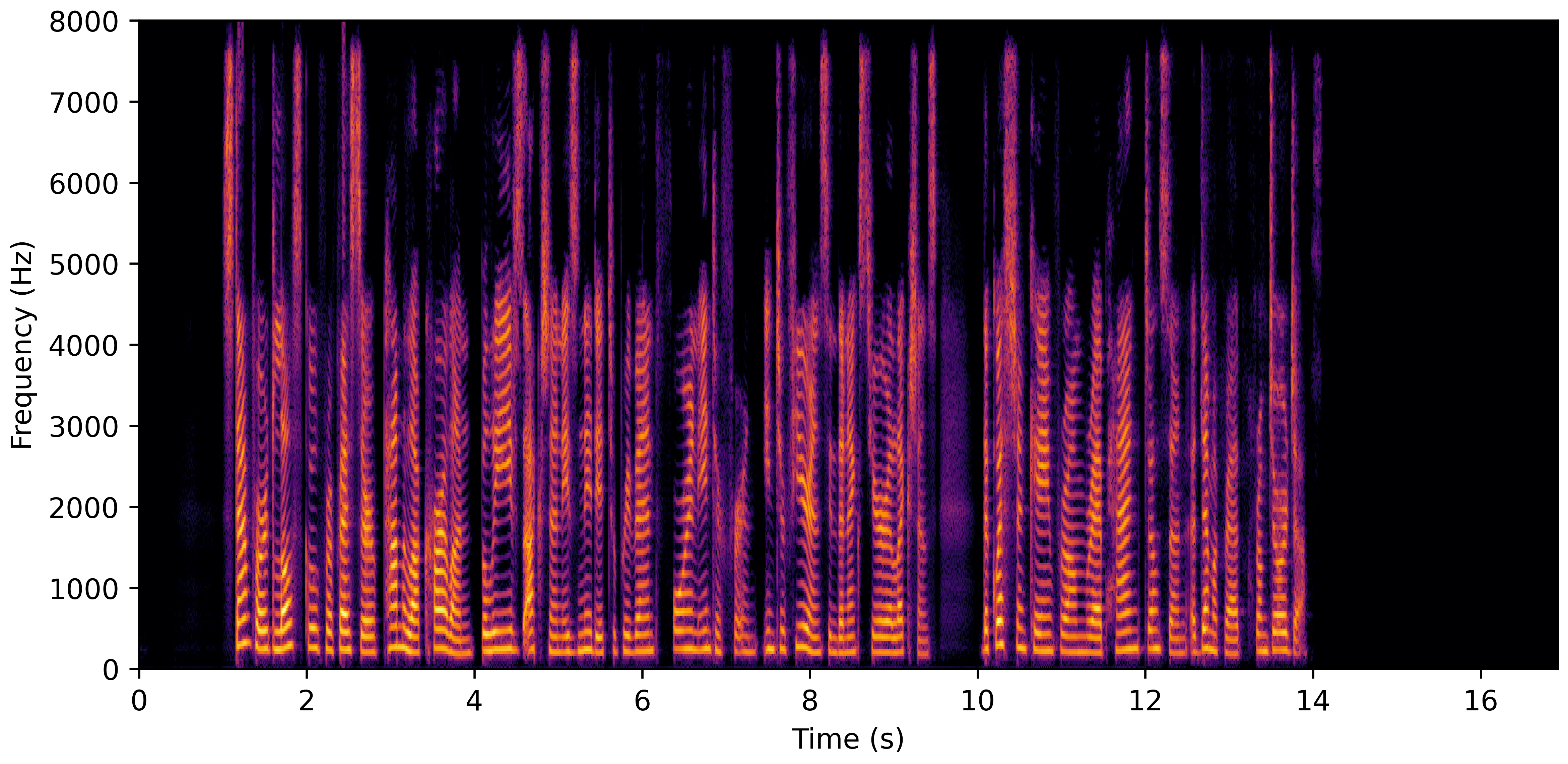
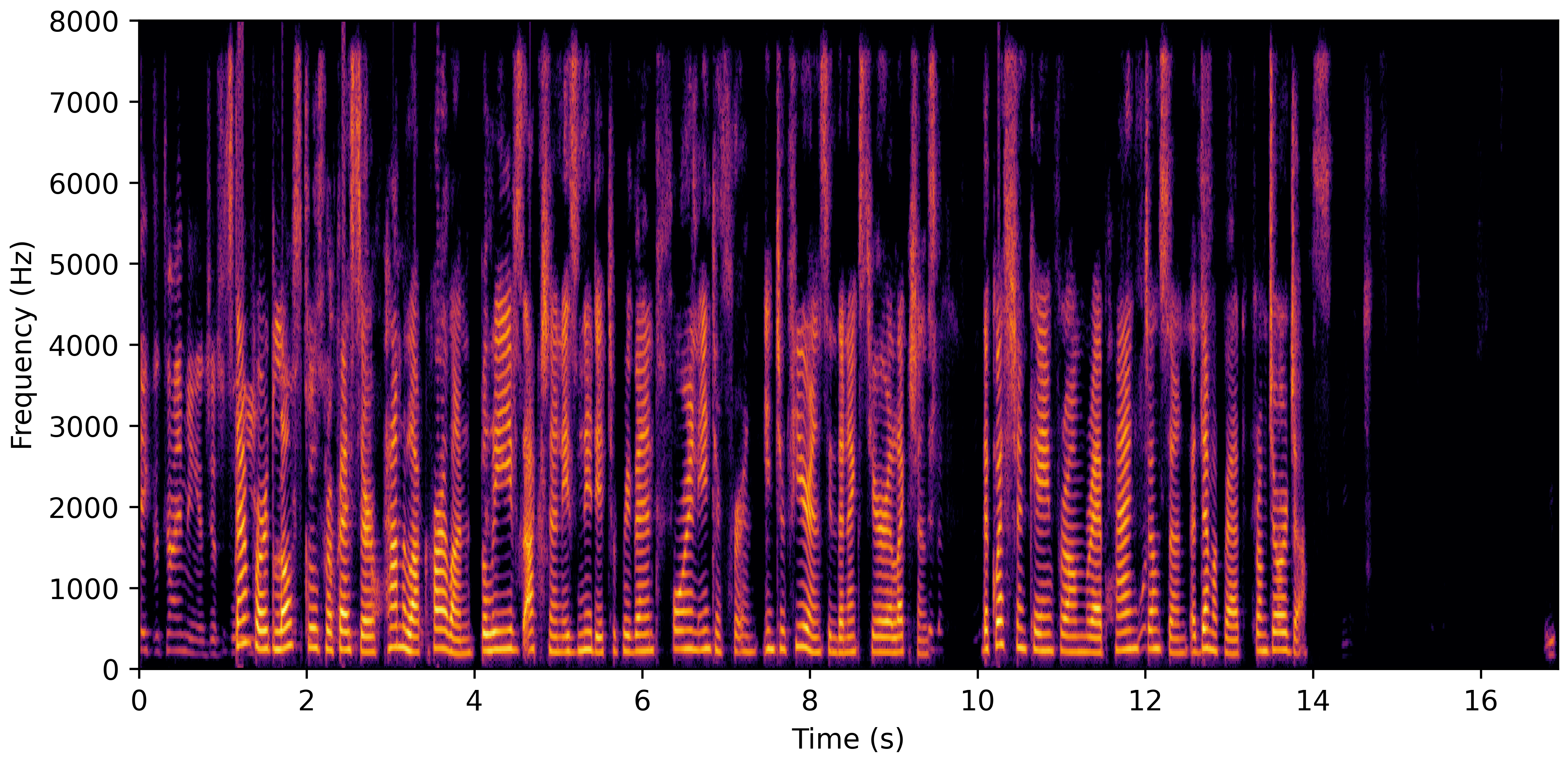
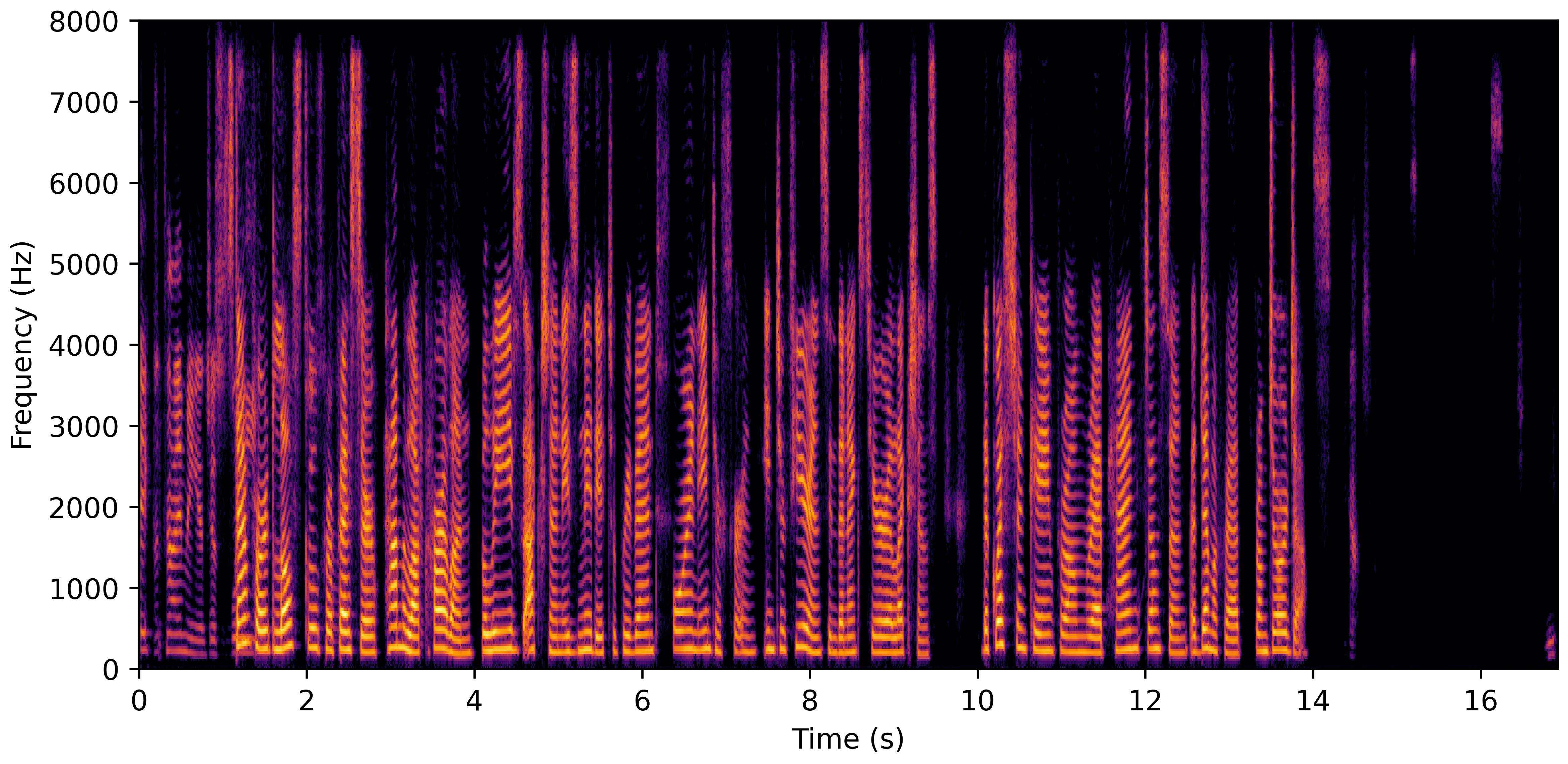
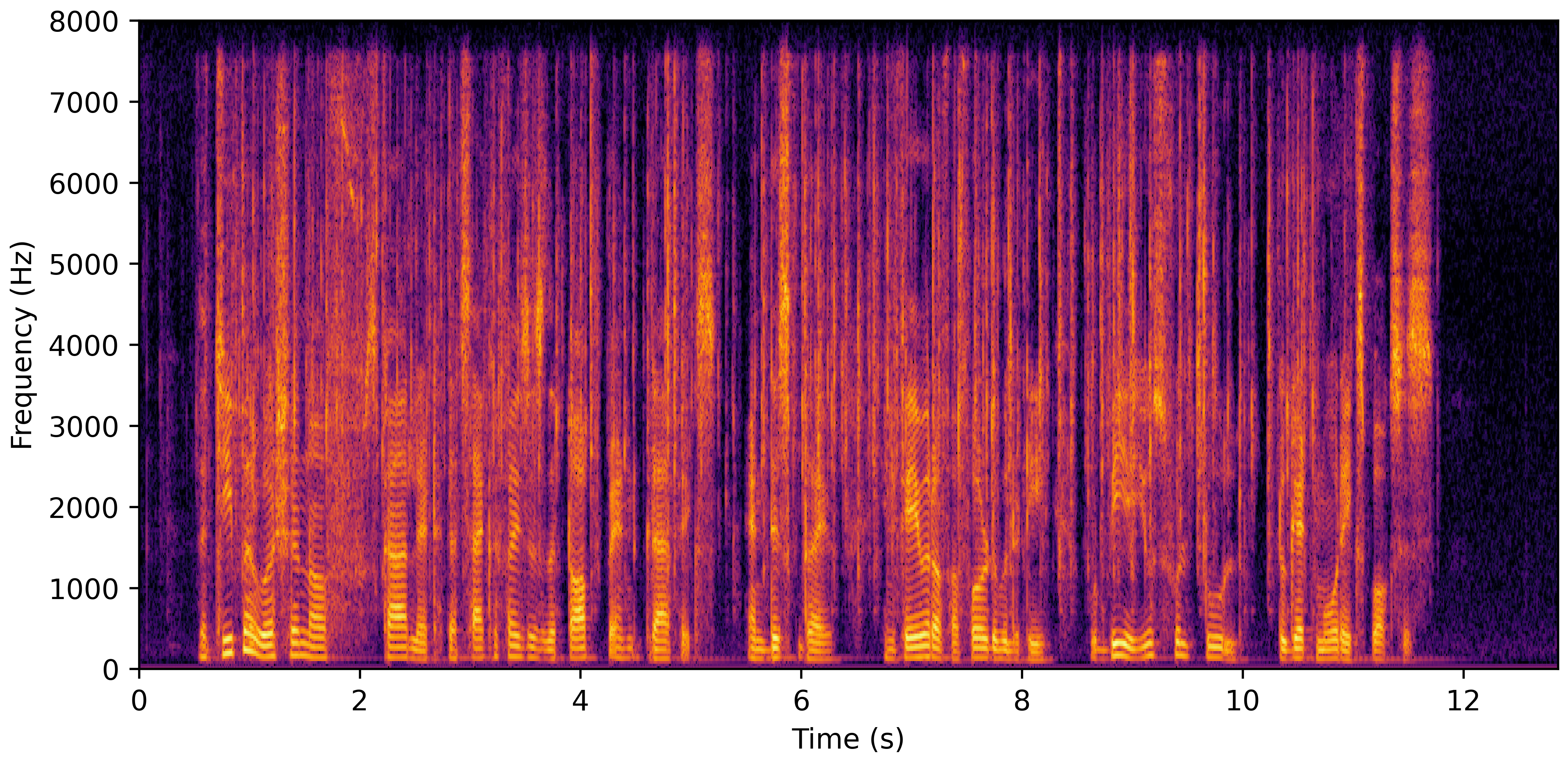
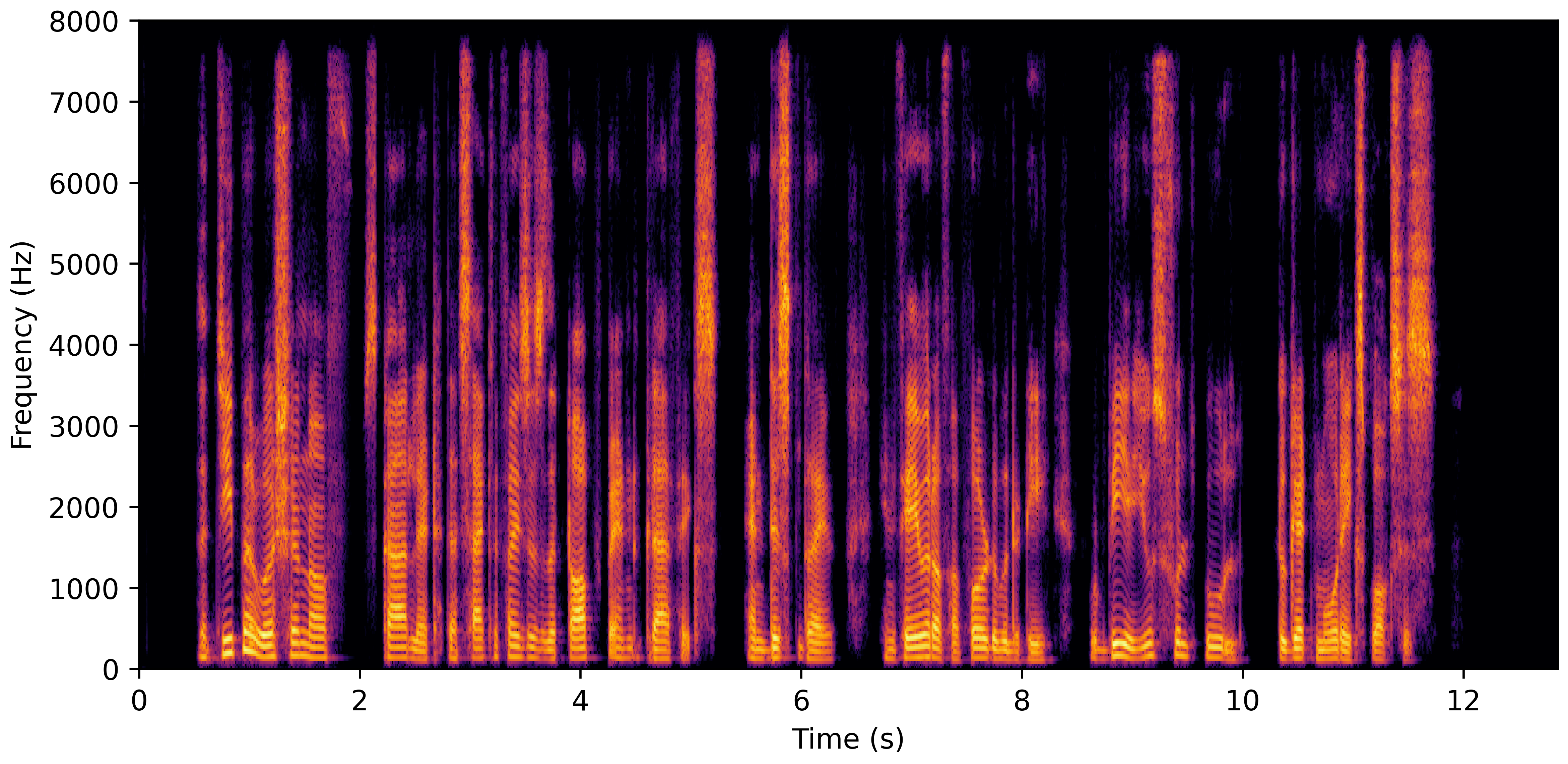
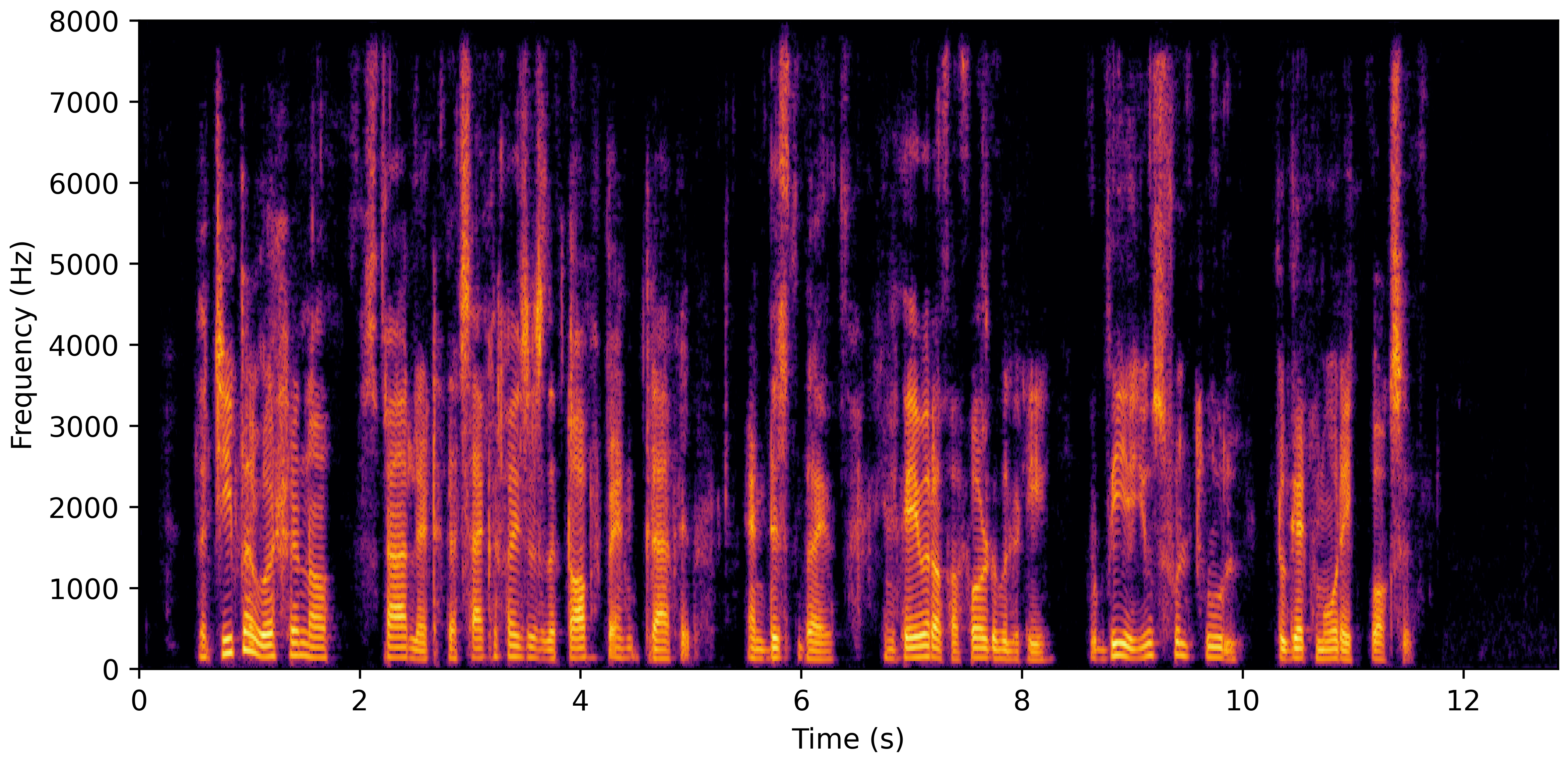
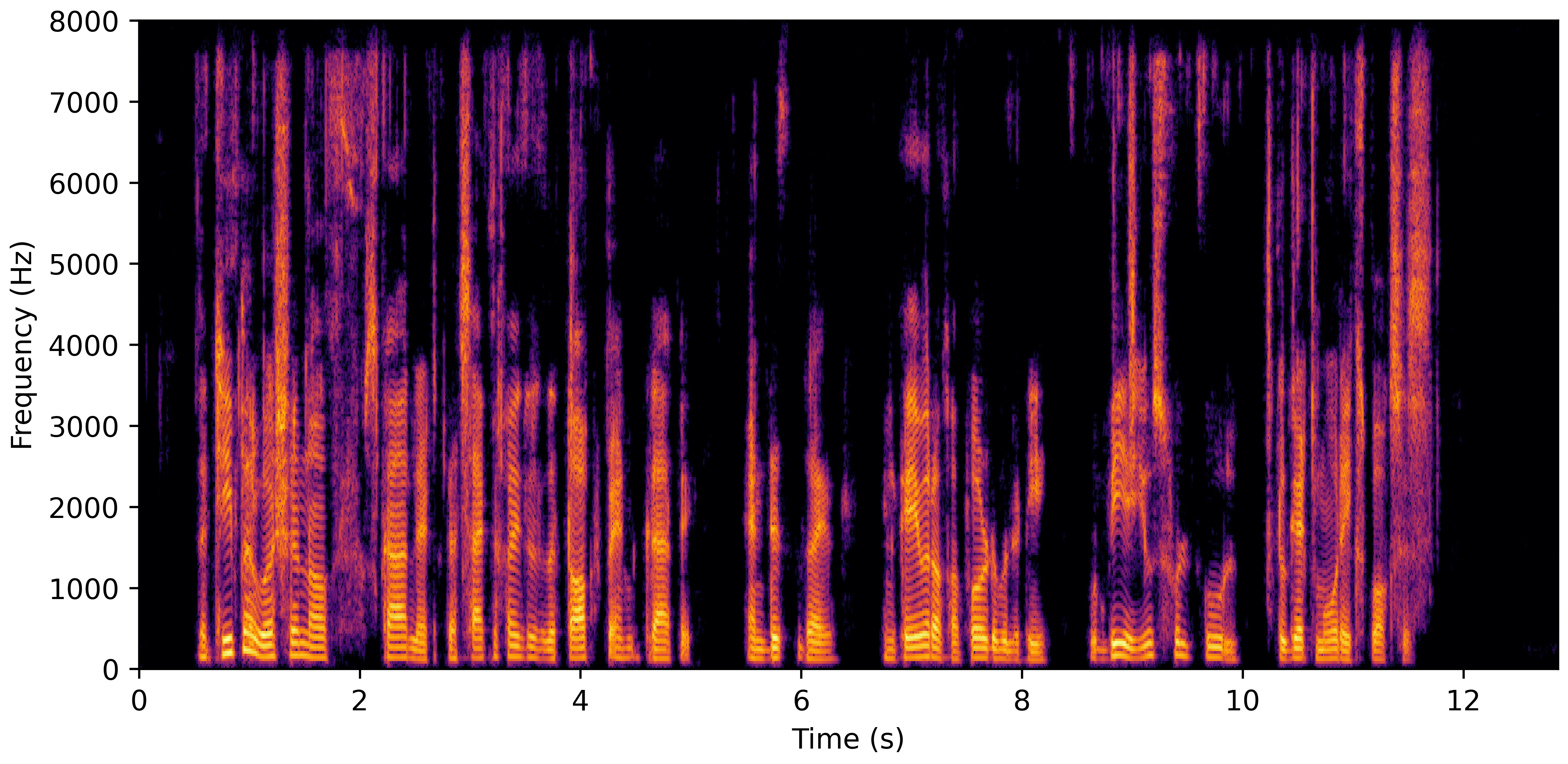
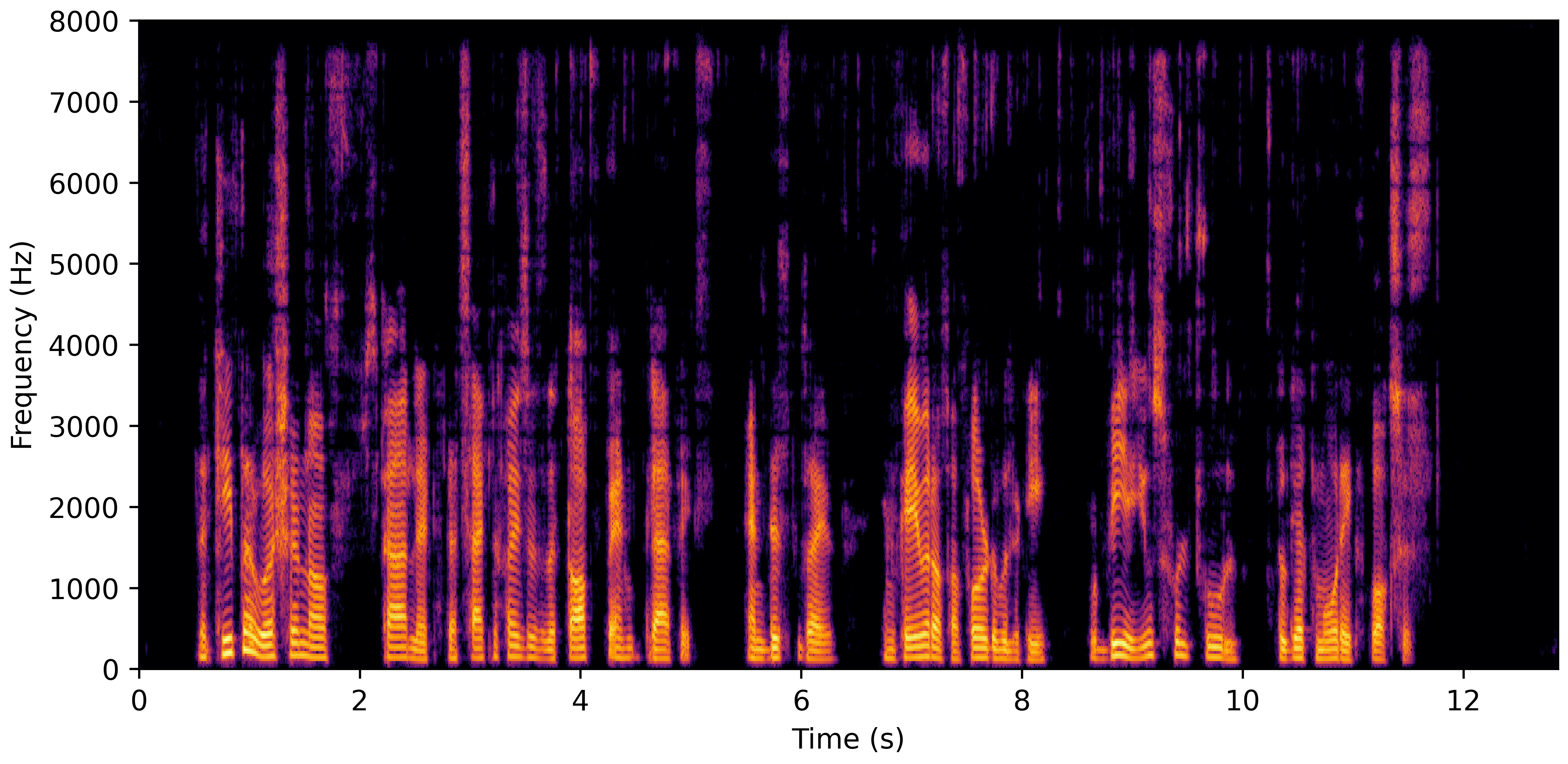
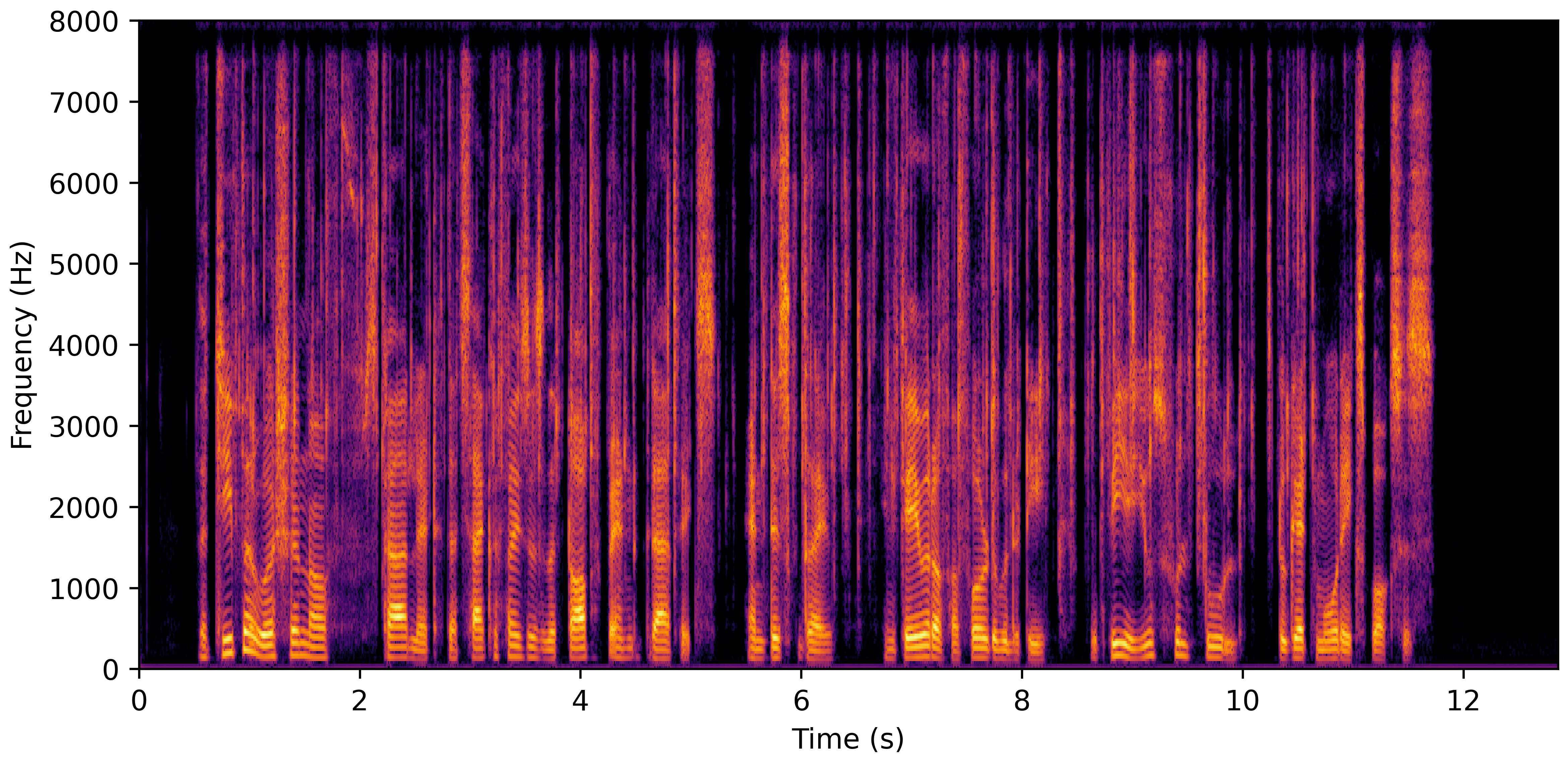
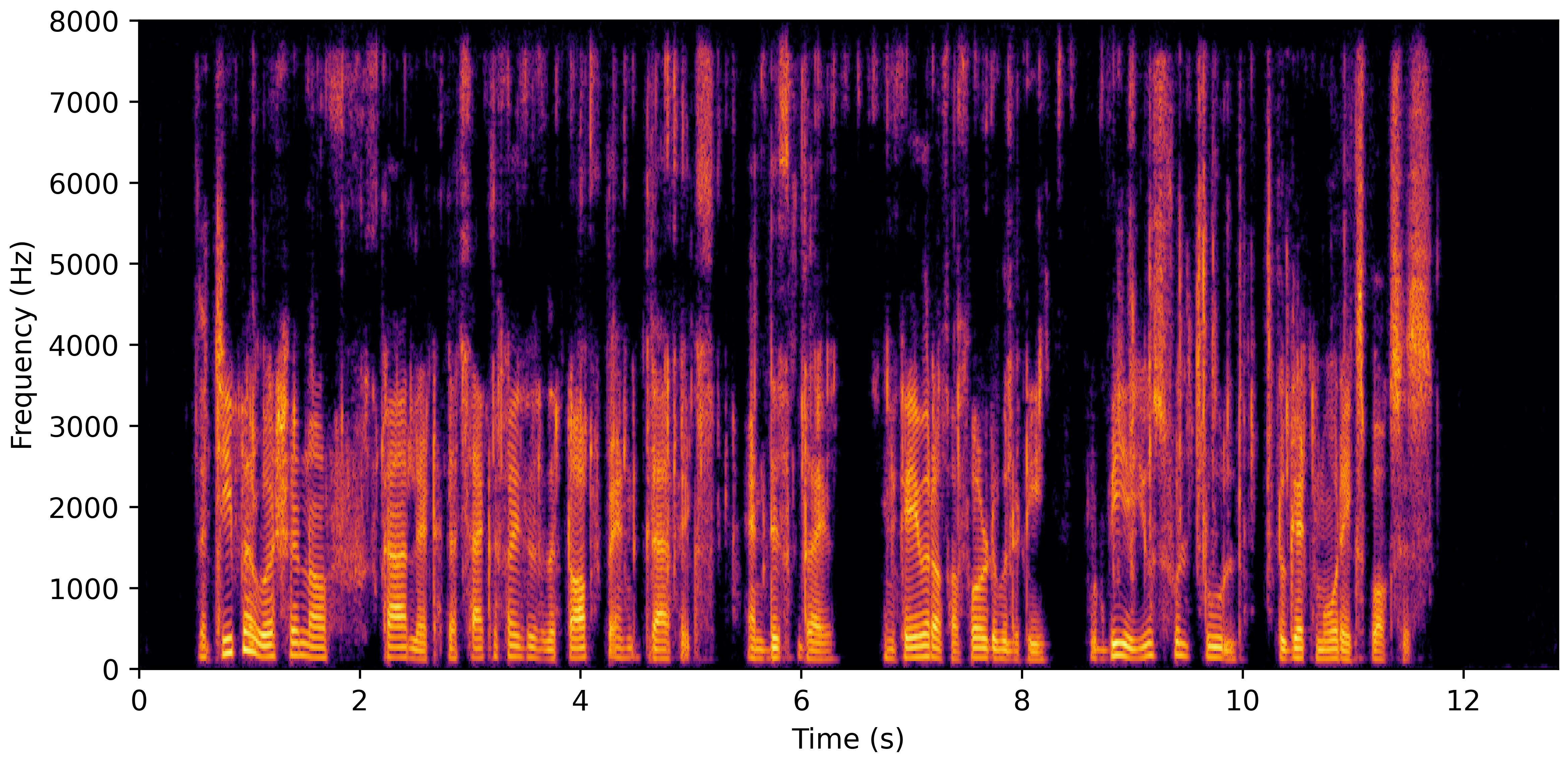
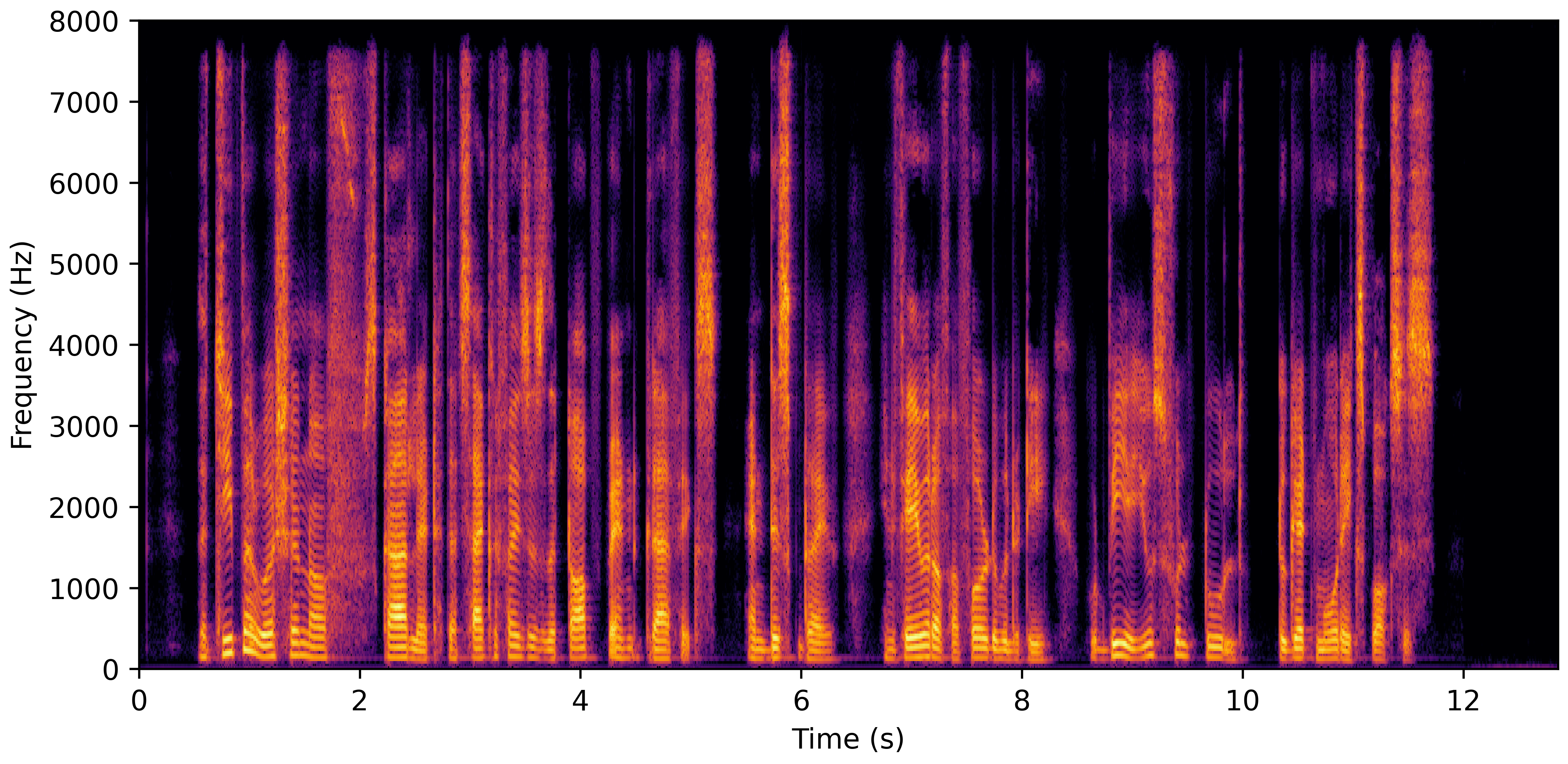
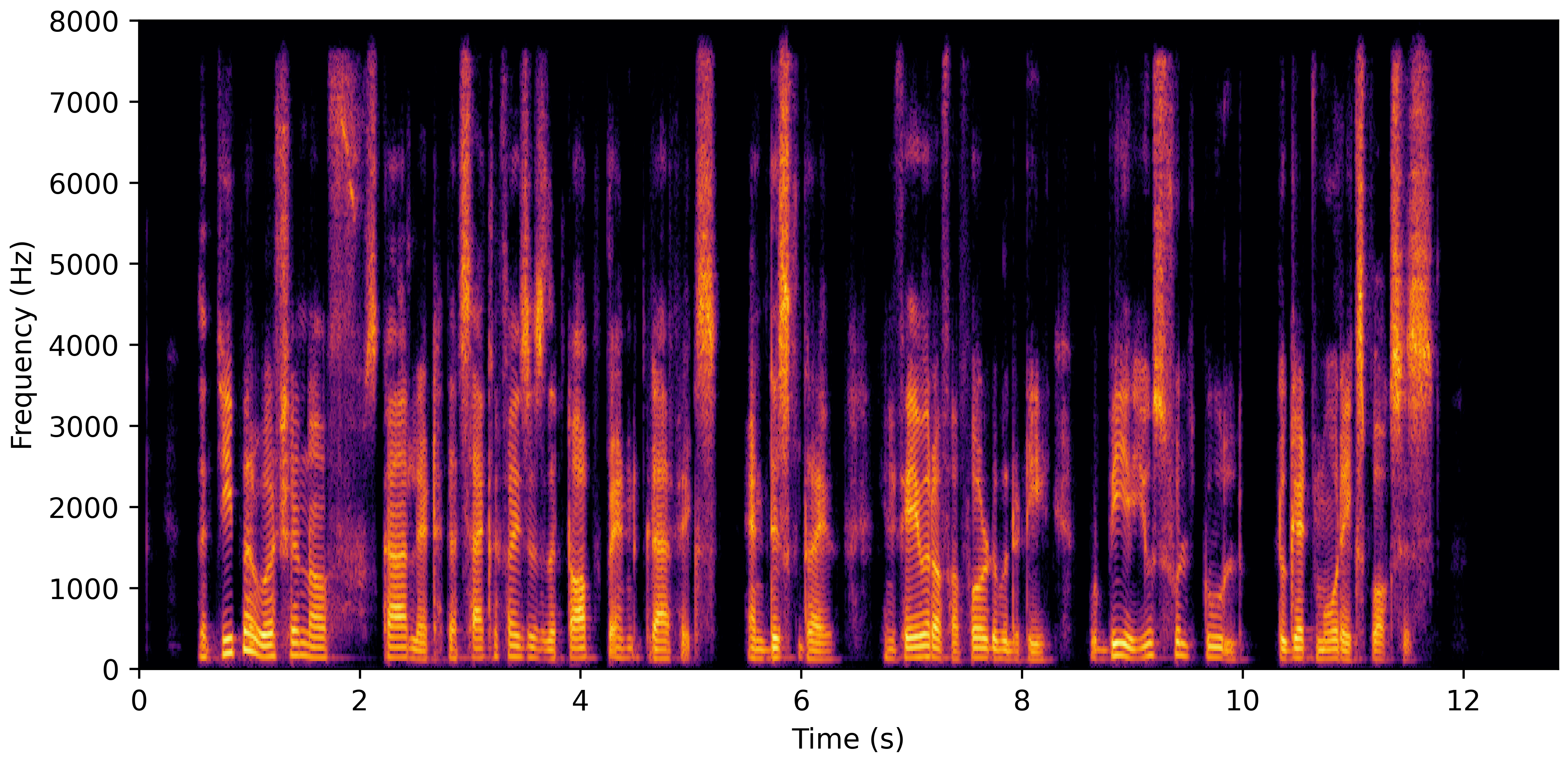
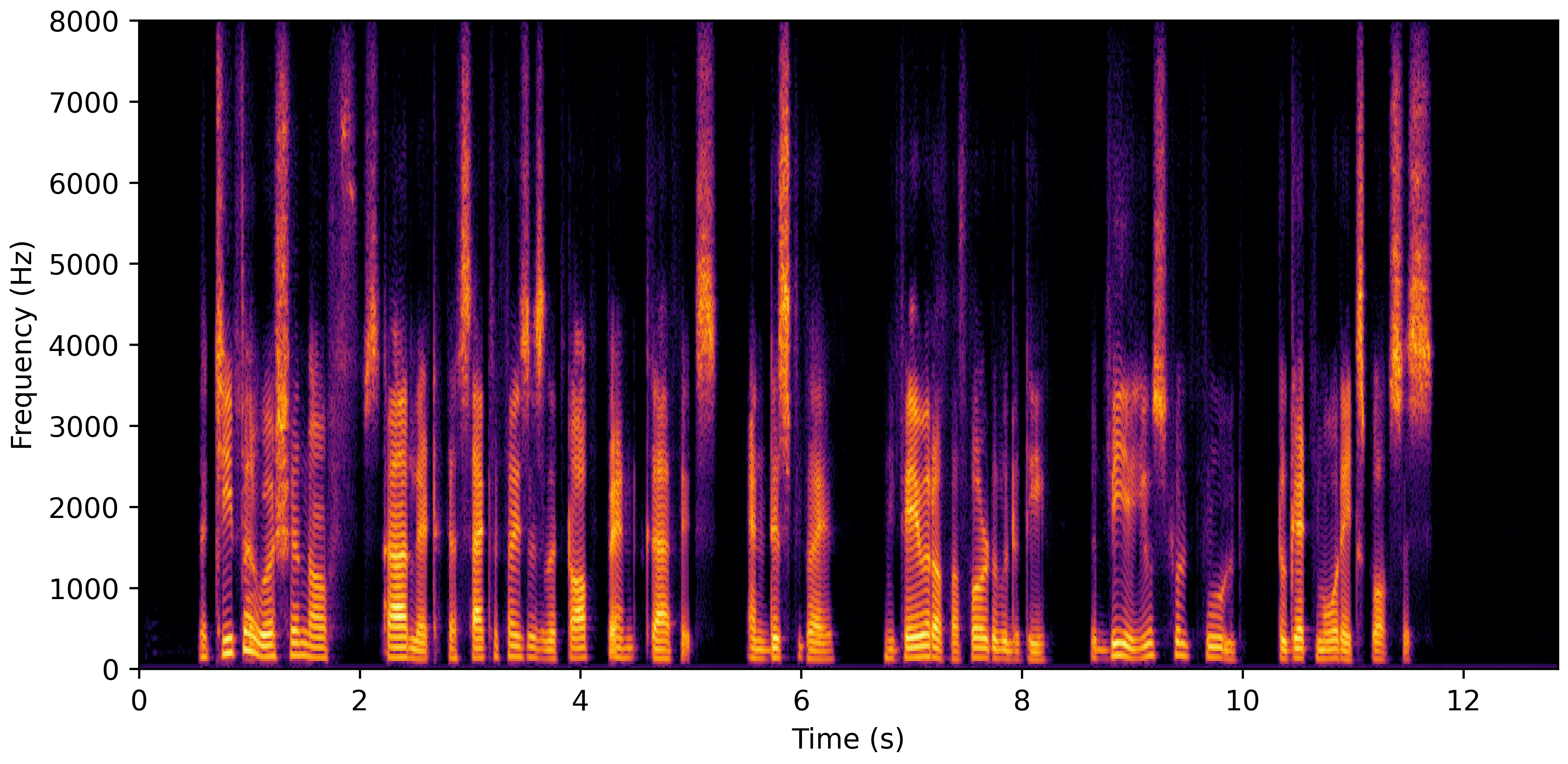
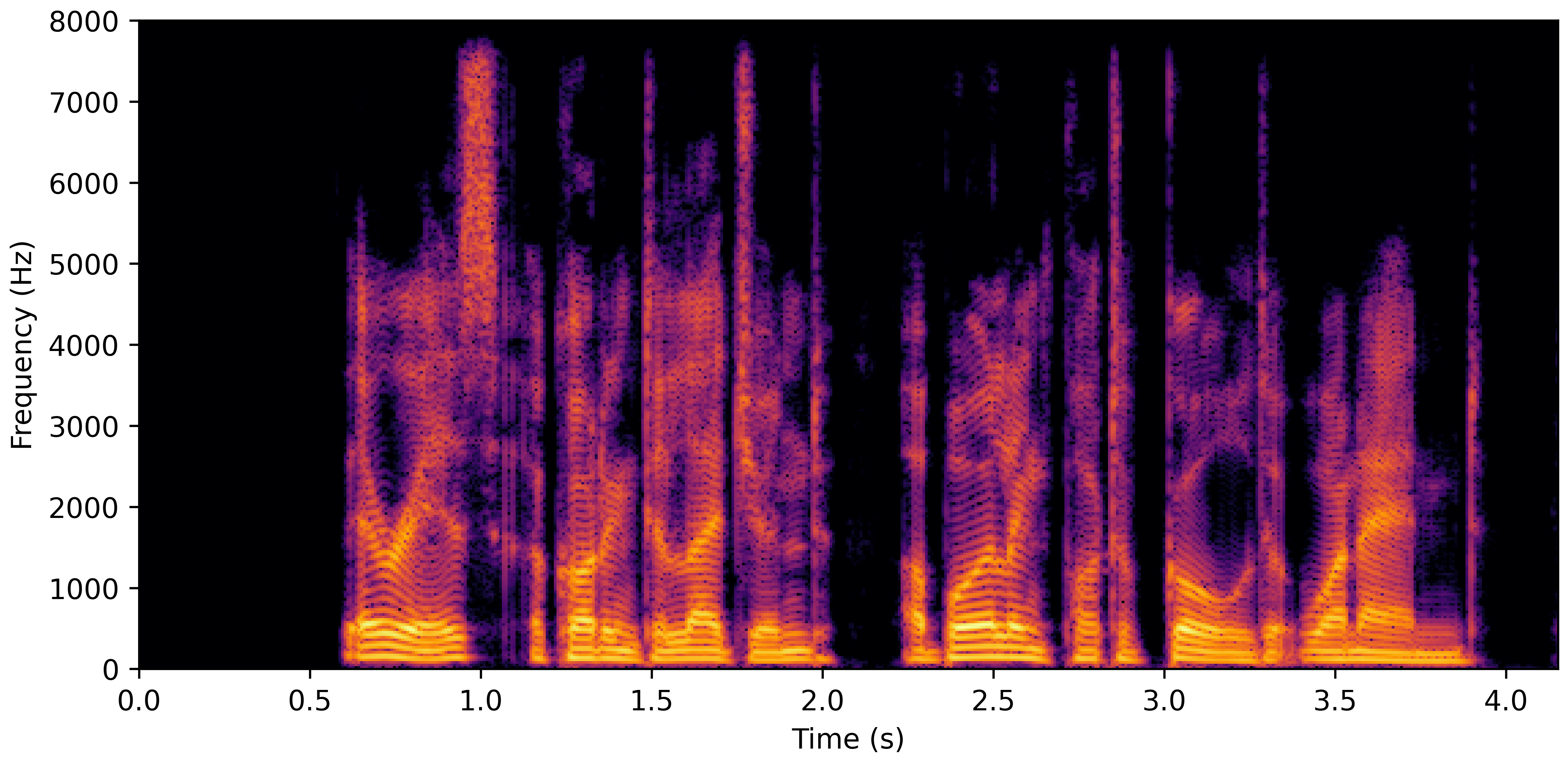
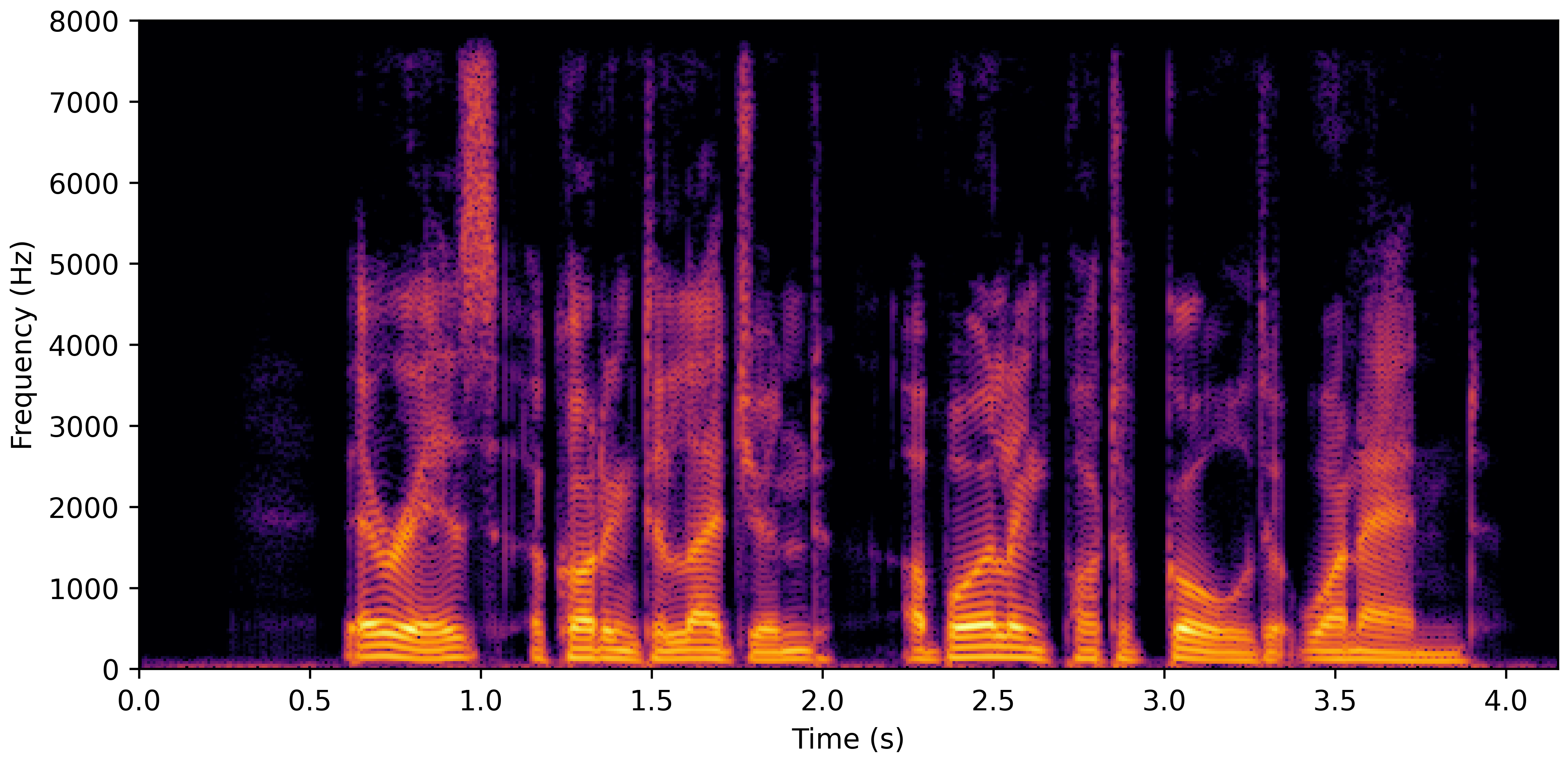
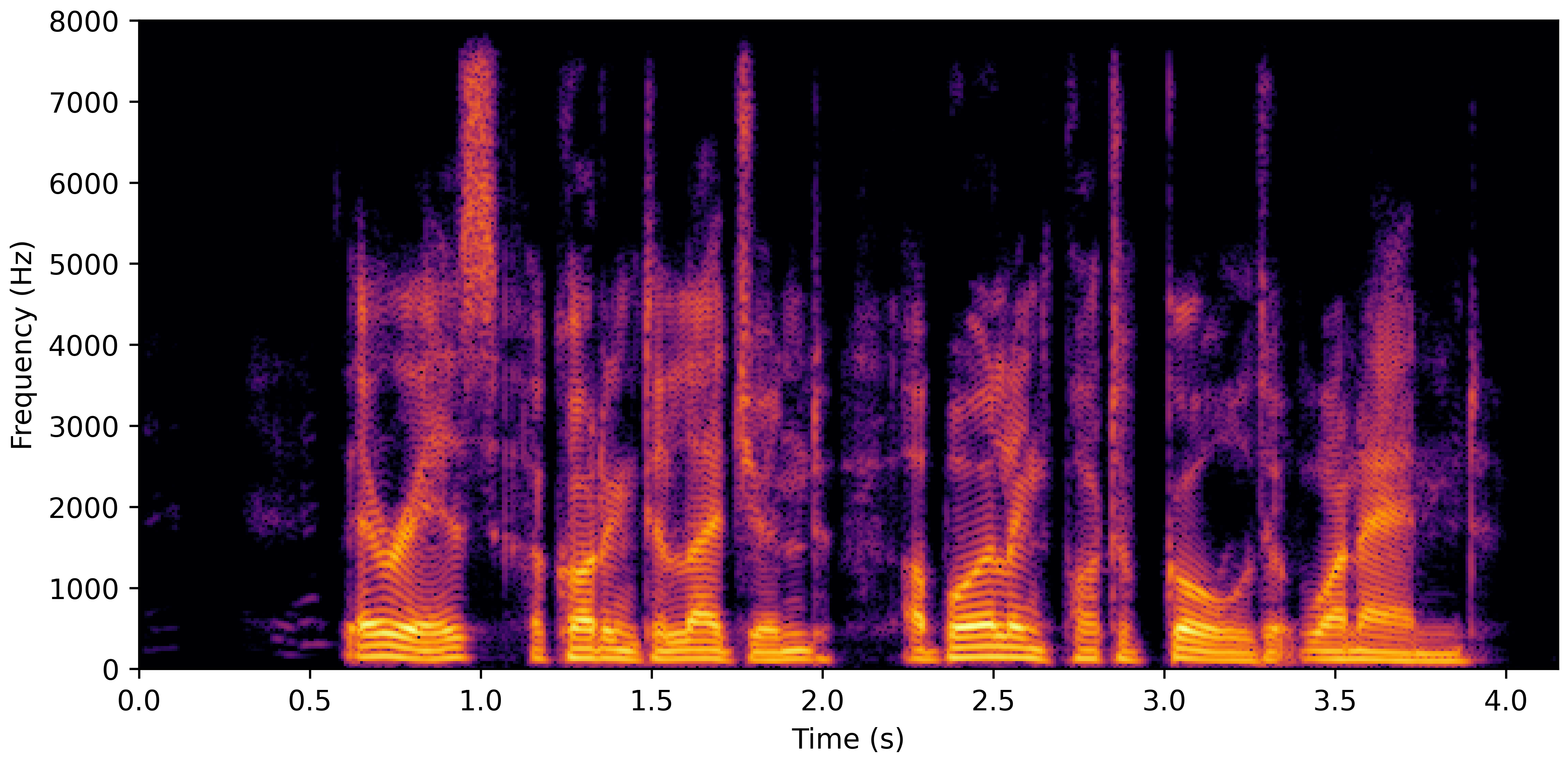
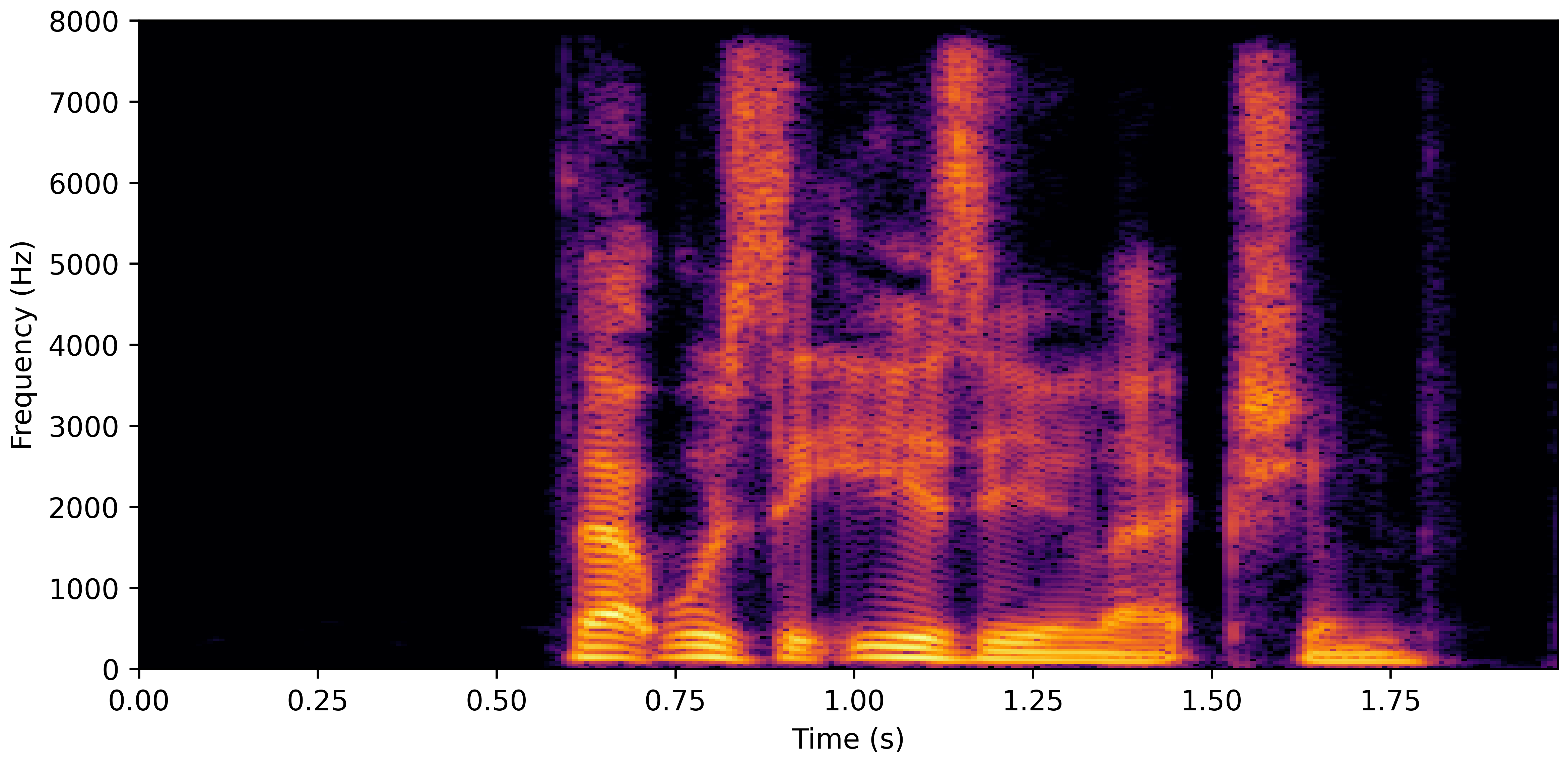
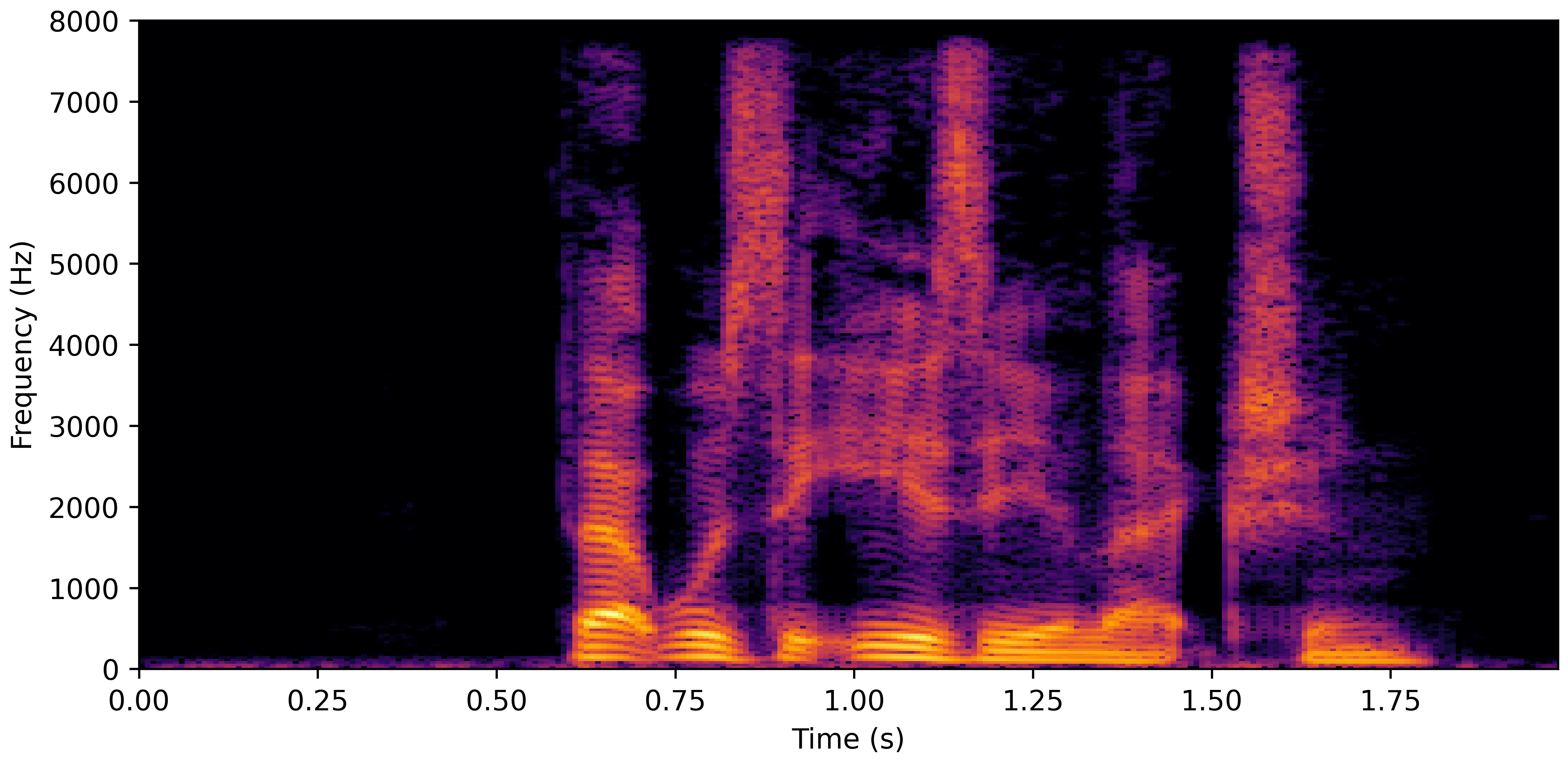
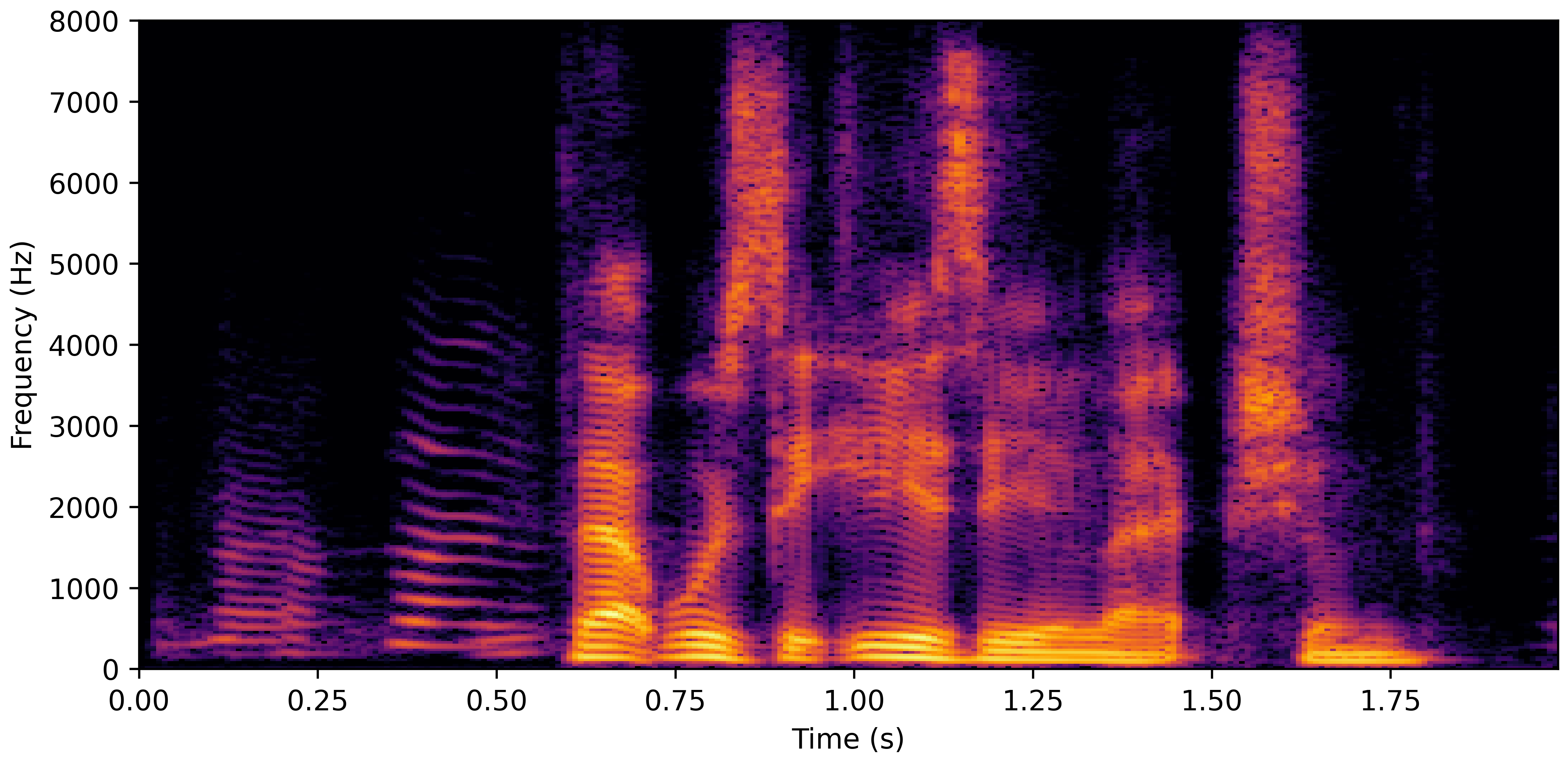
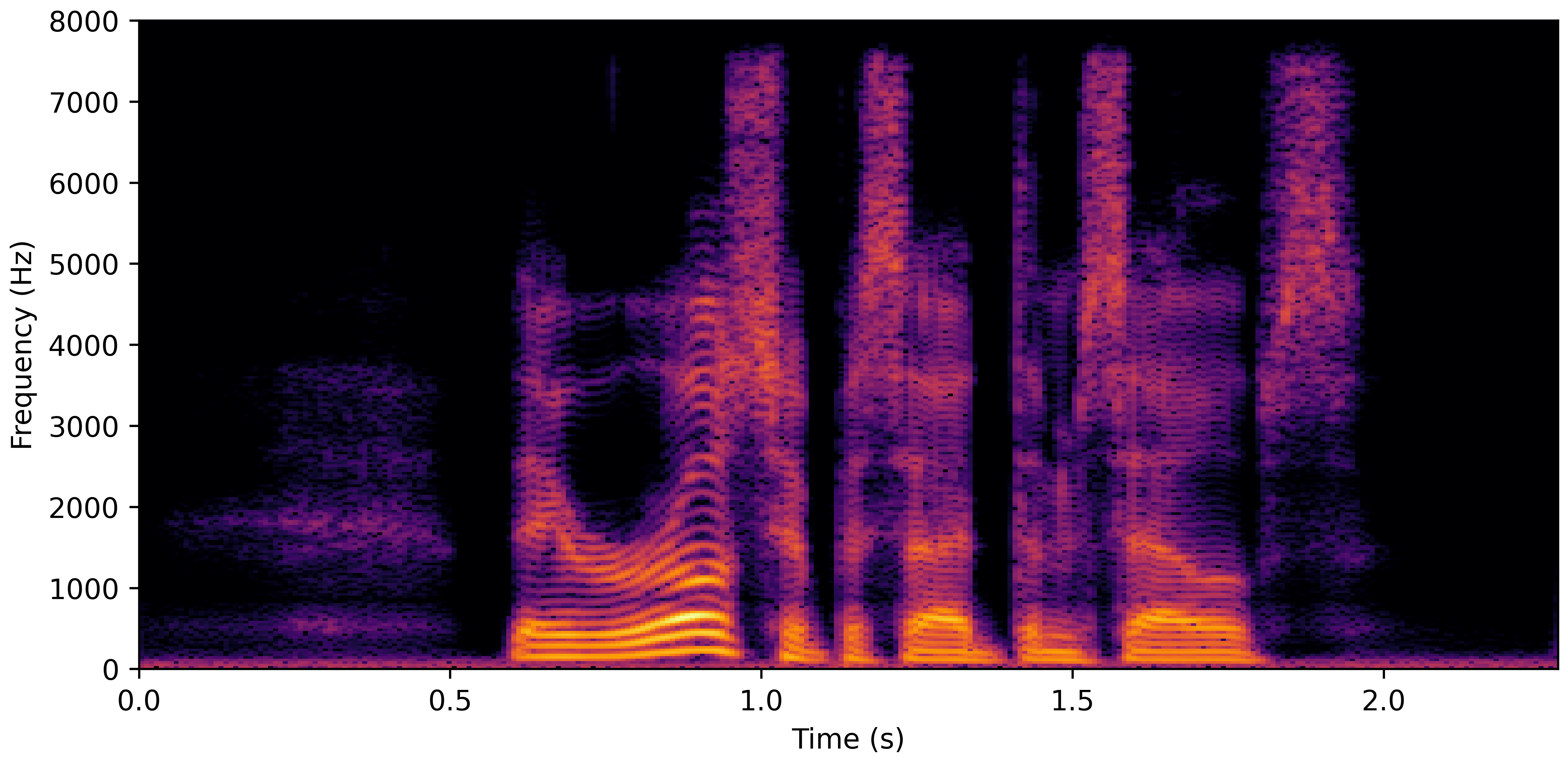
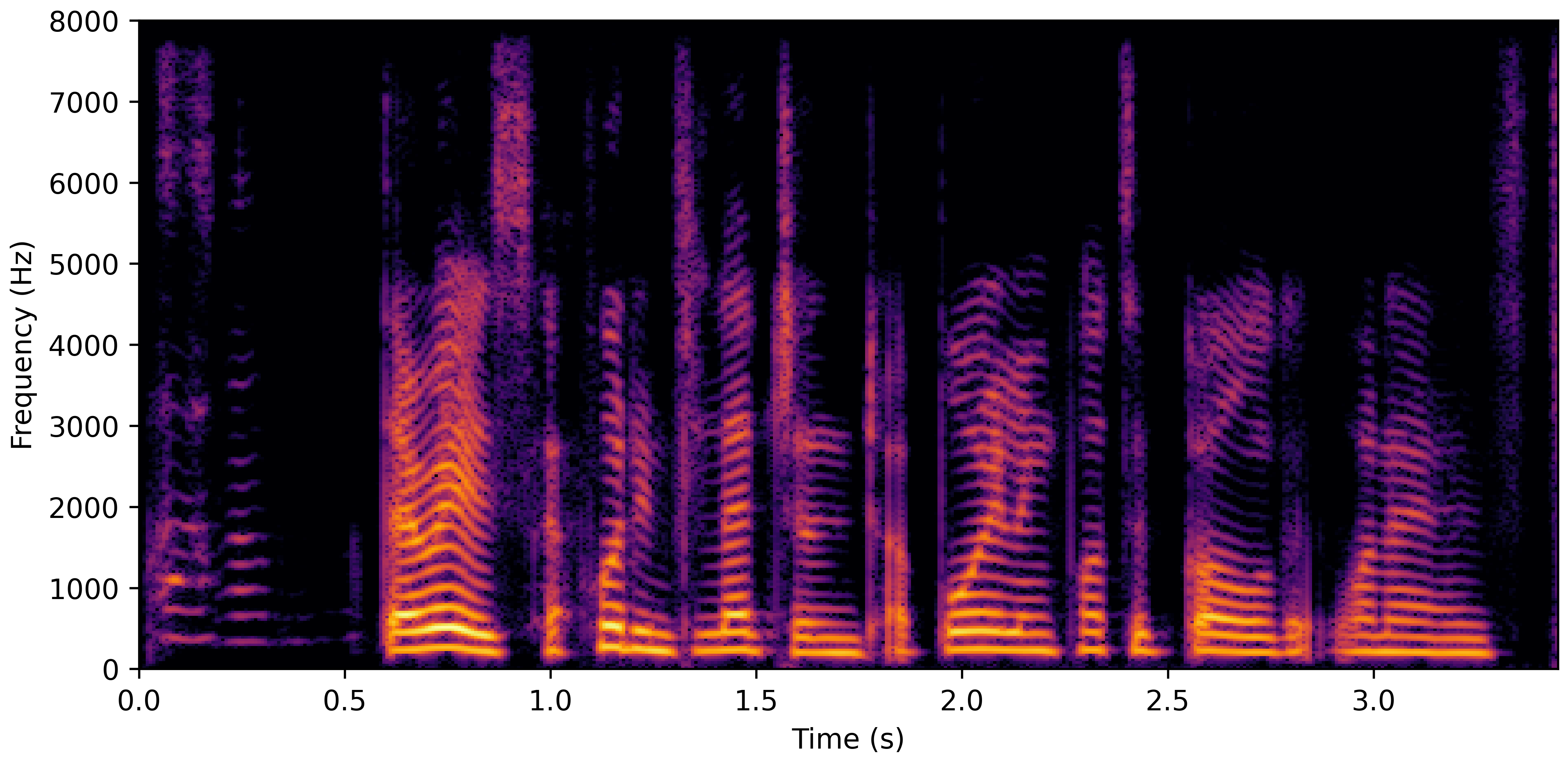
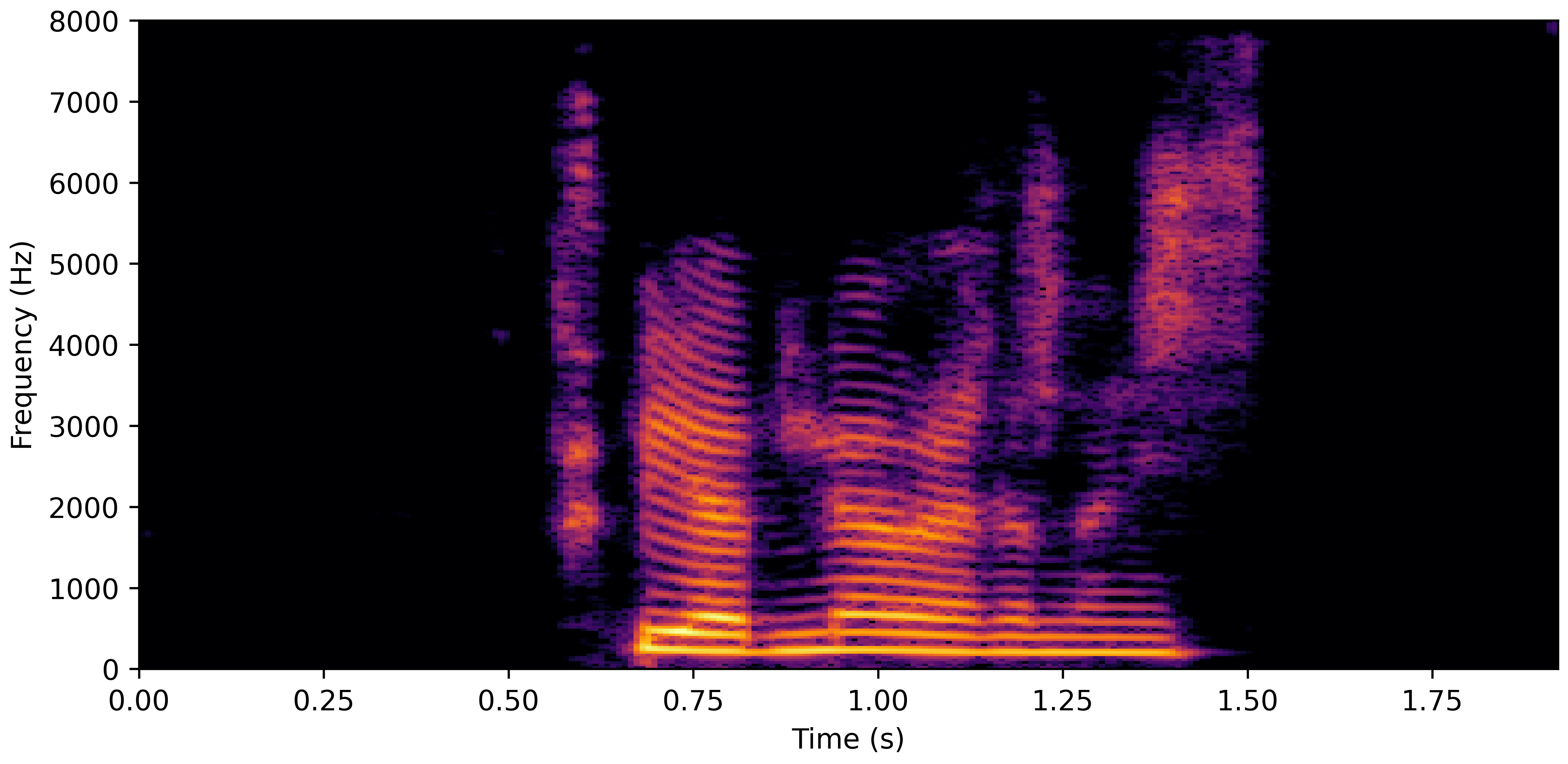
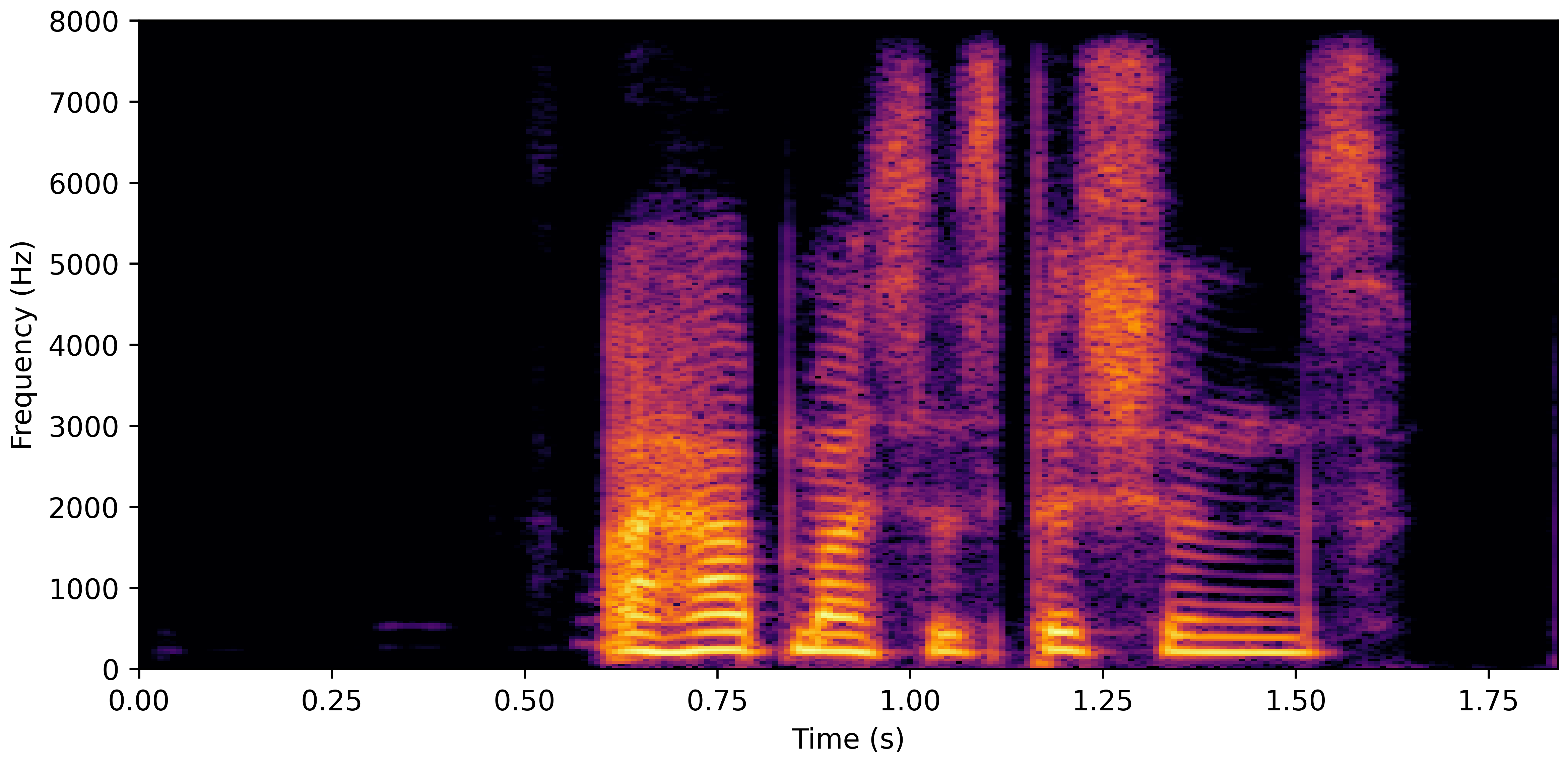
DNS With Reverb
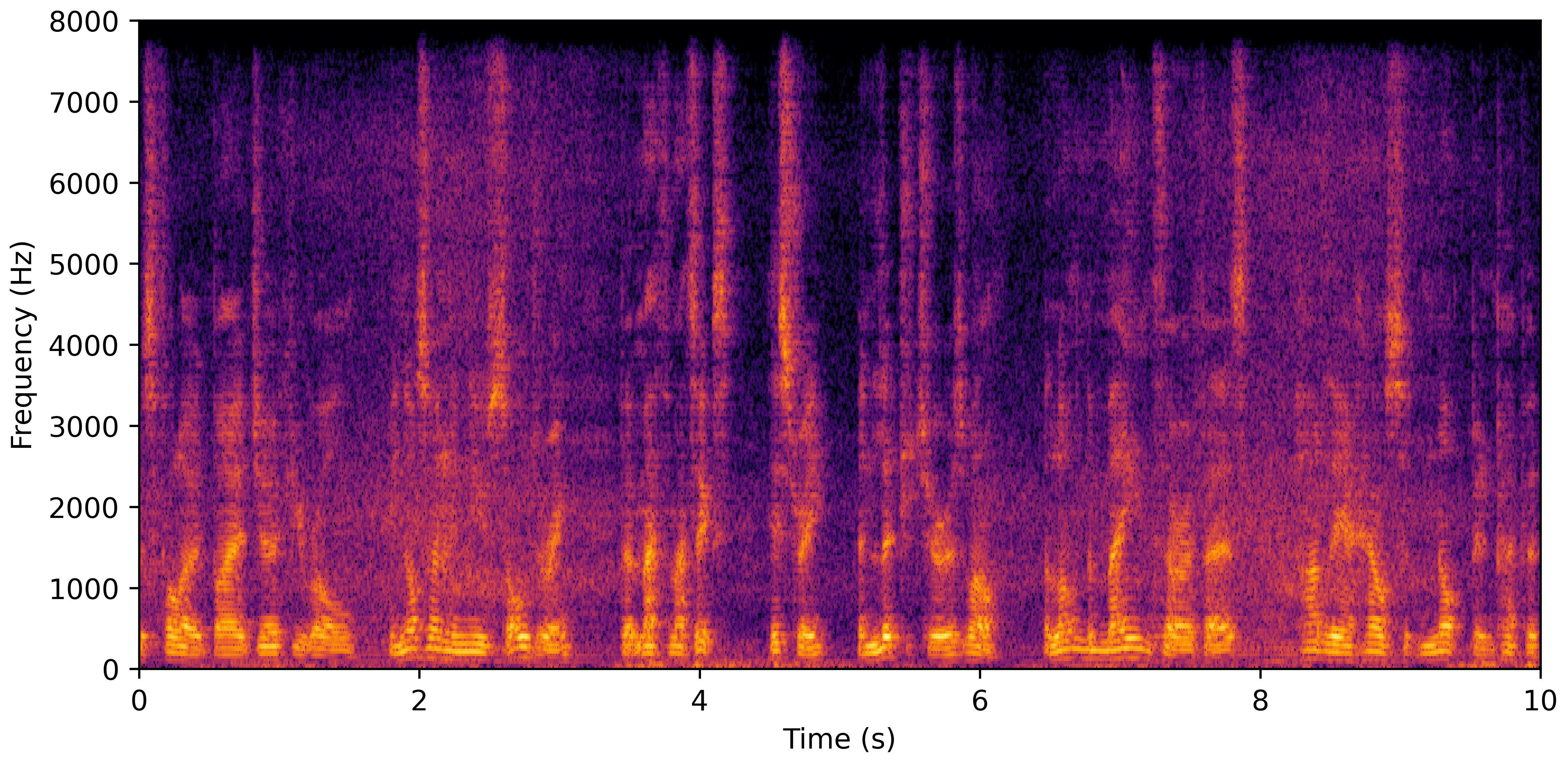
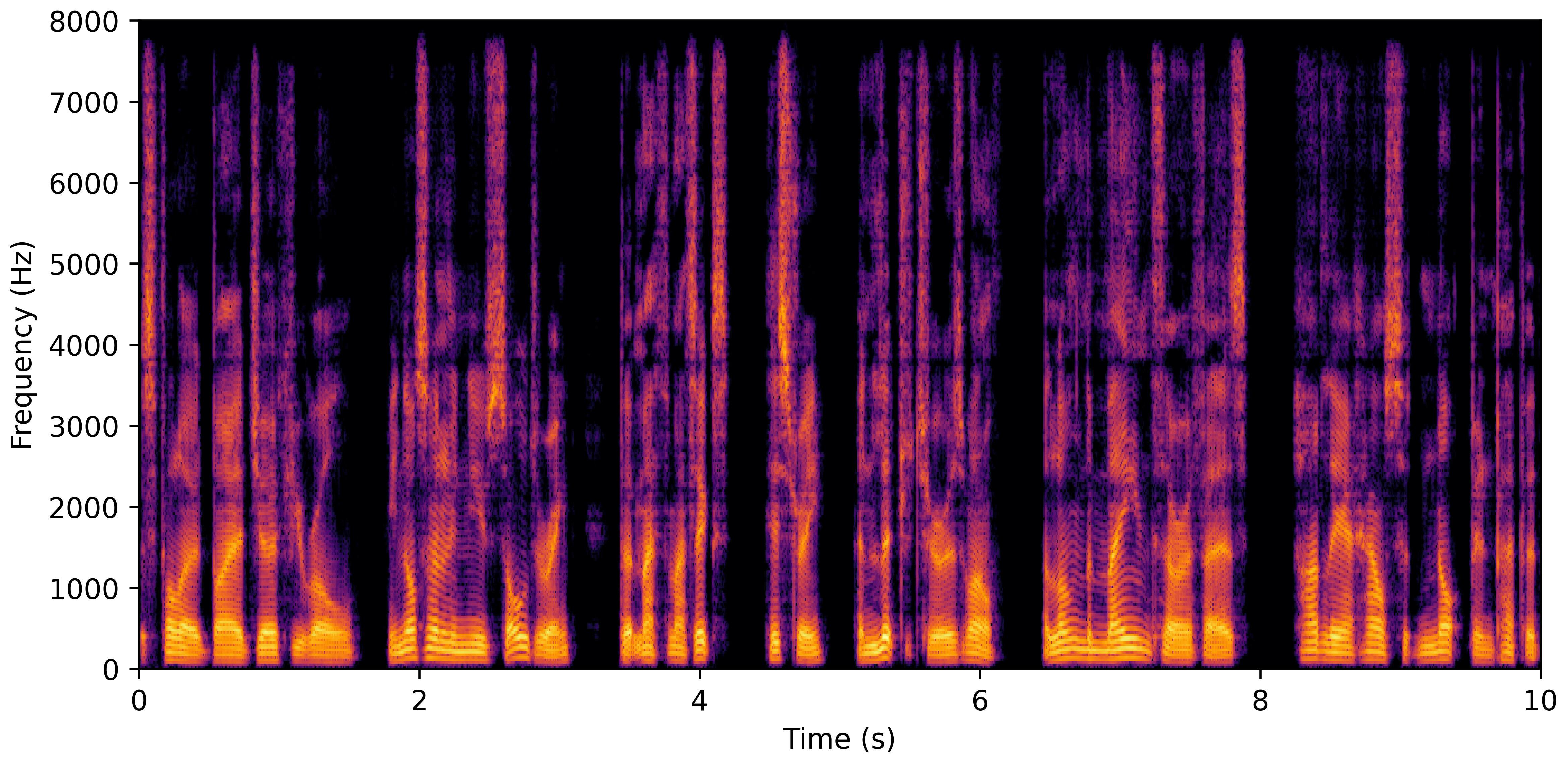
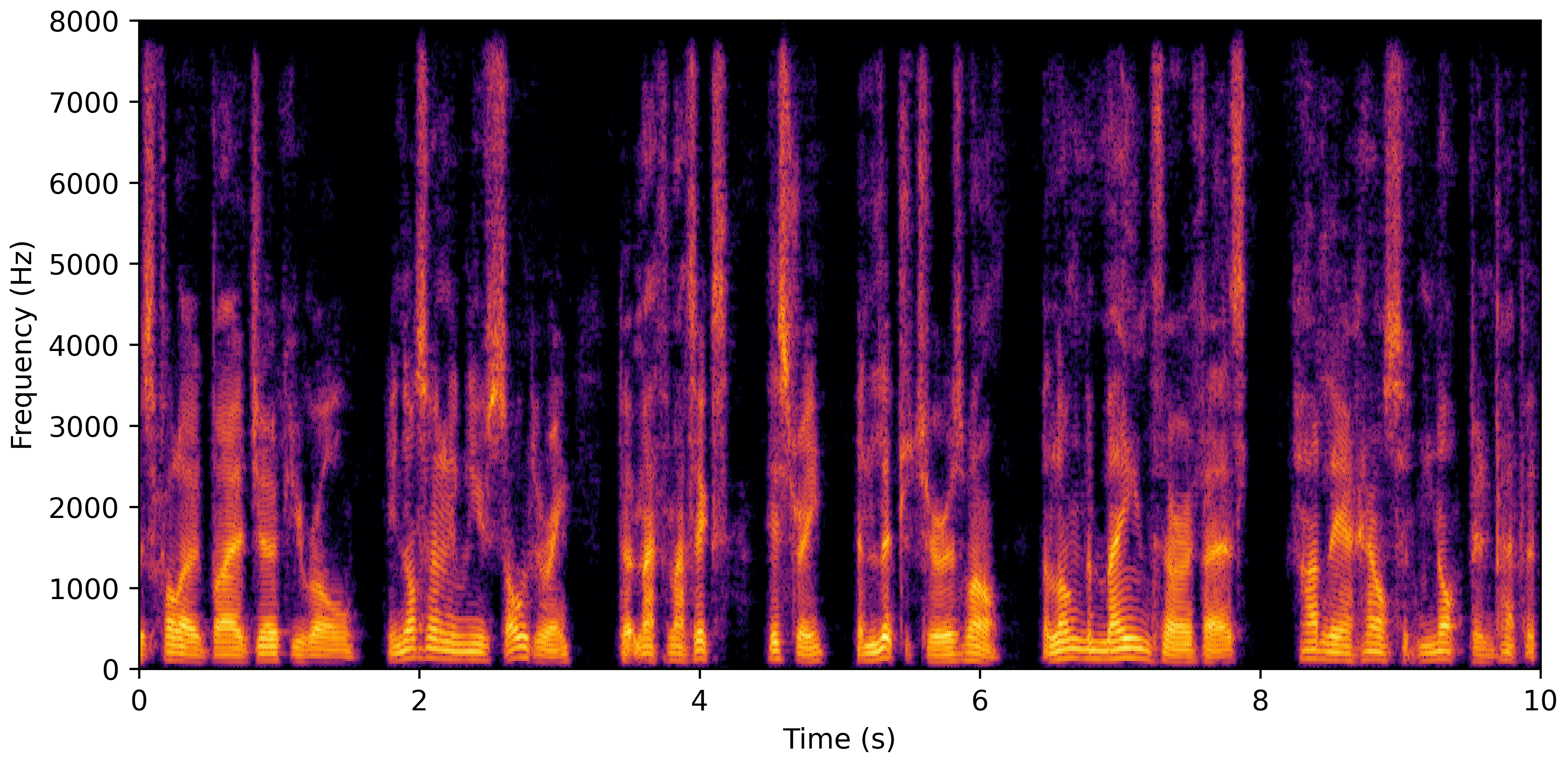
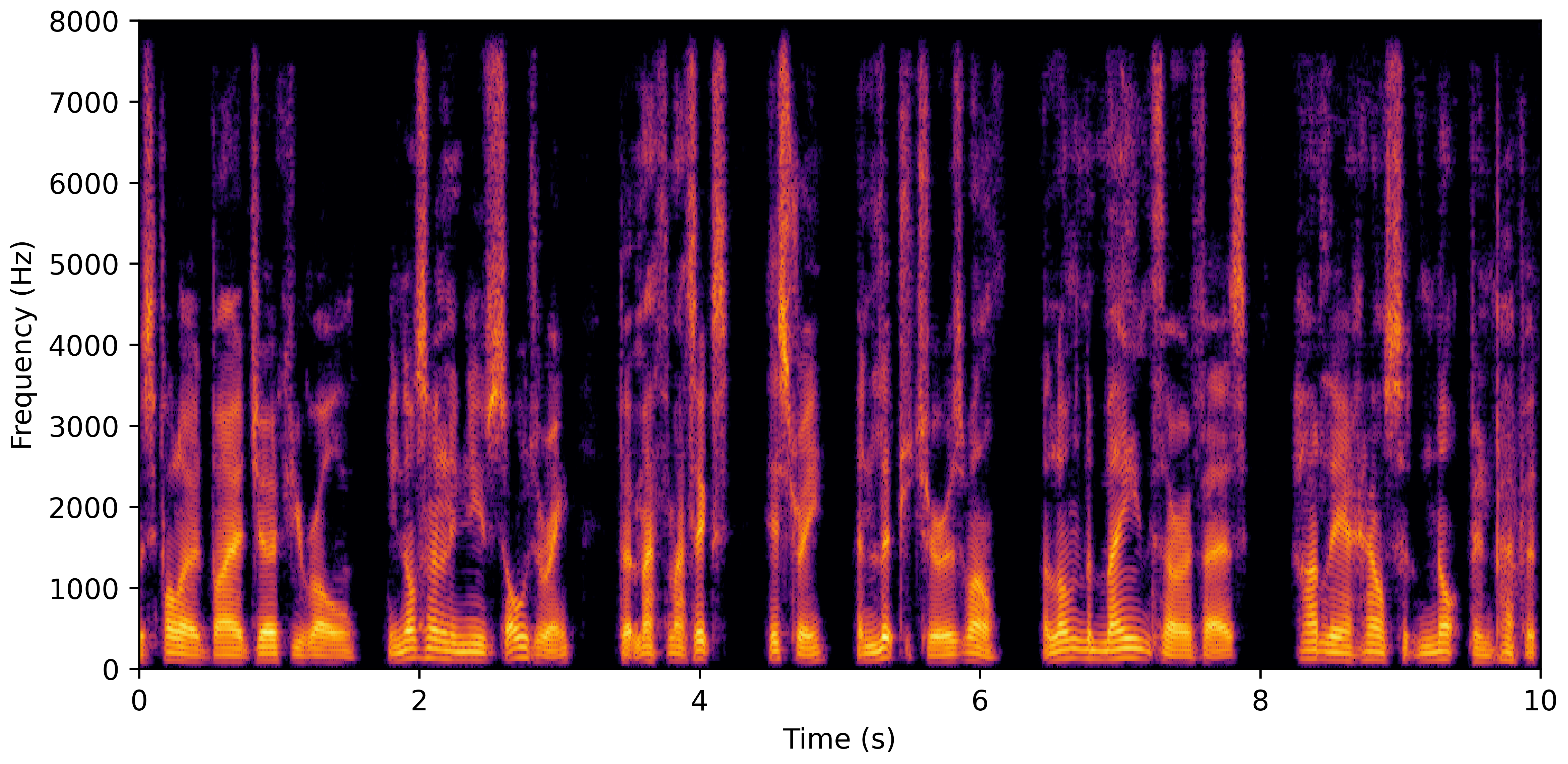
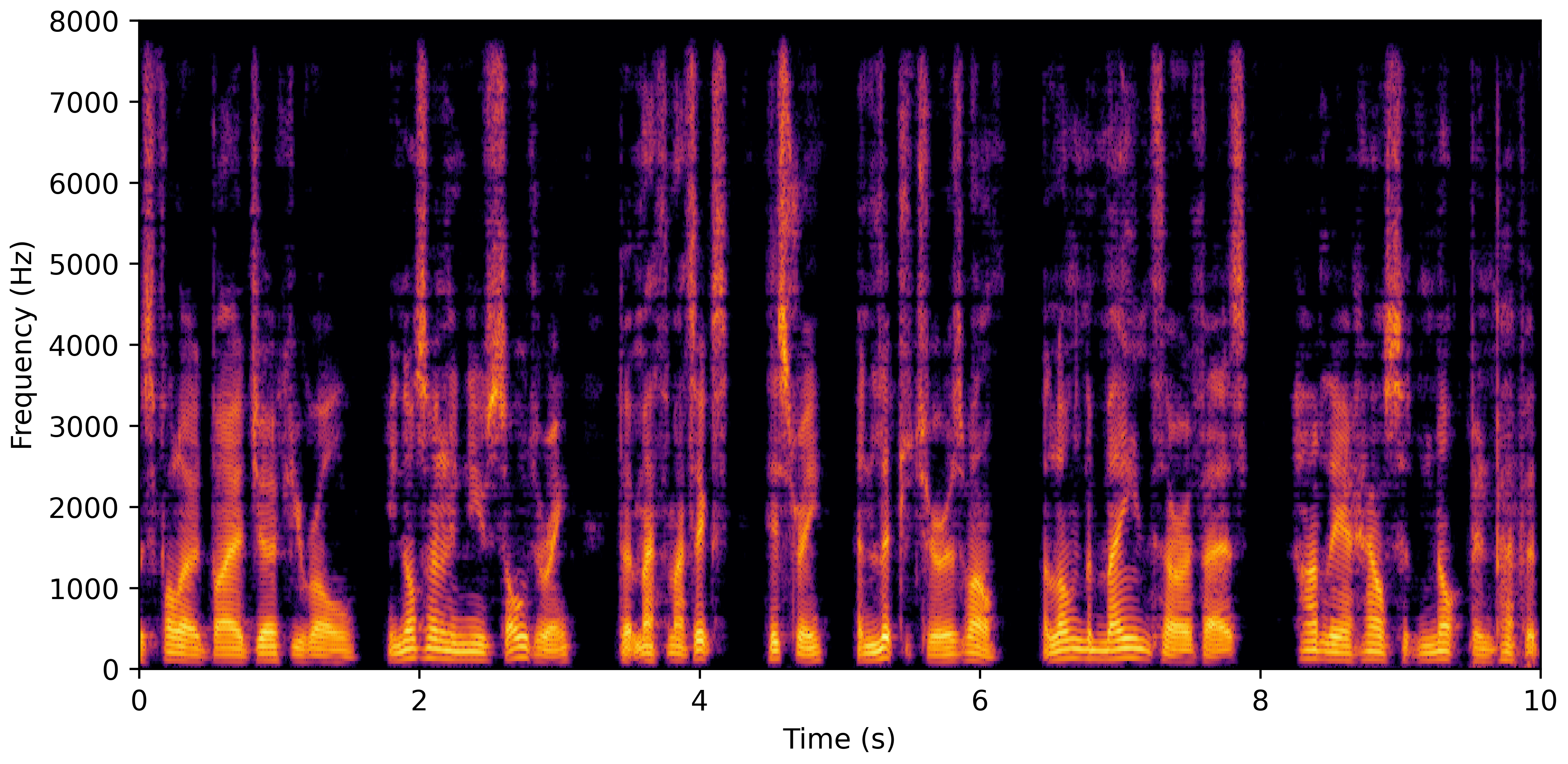
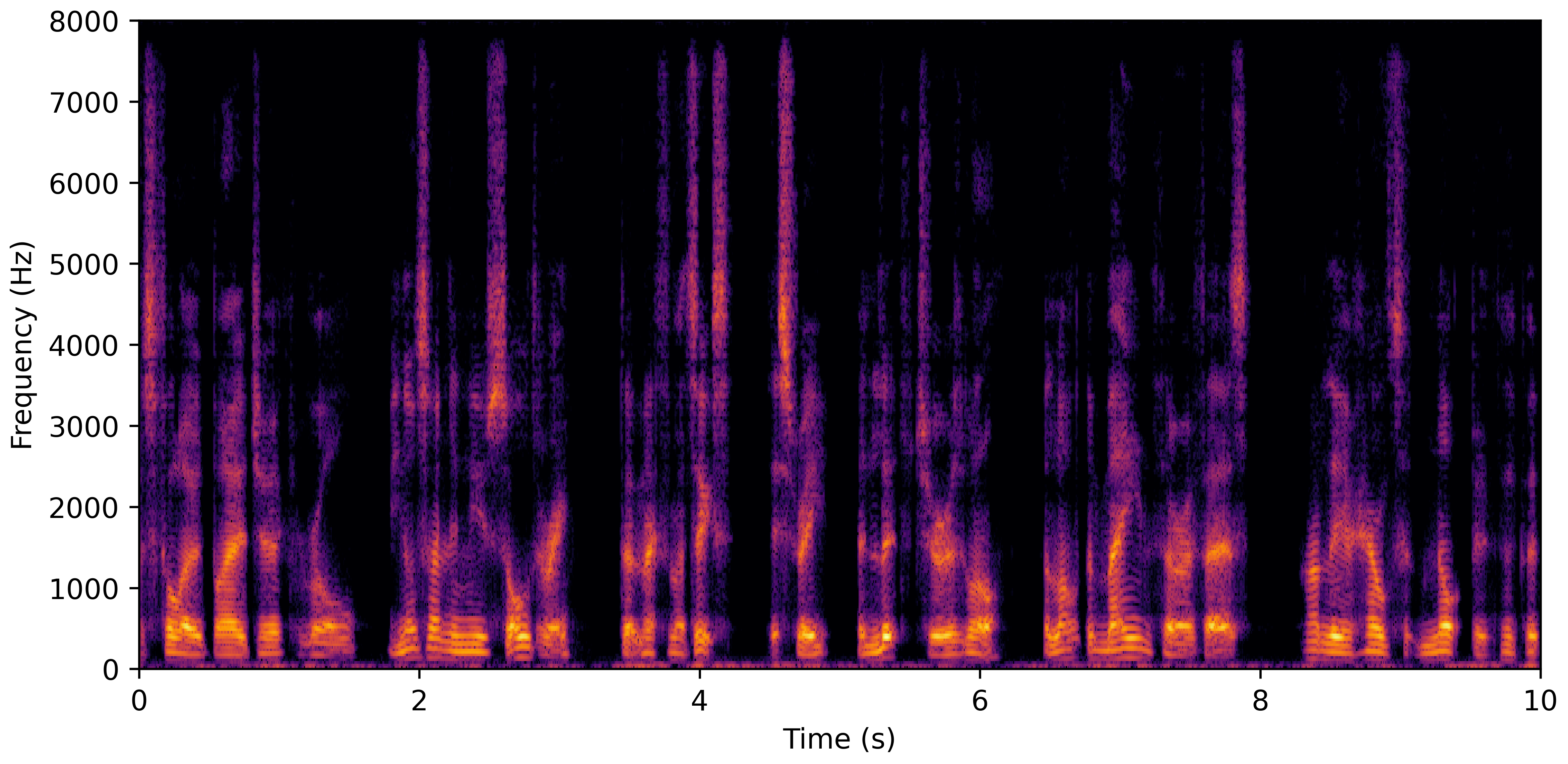
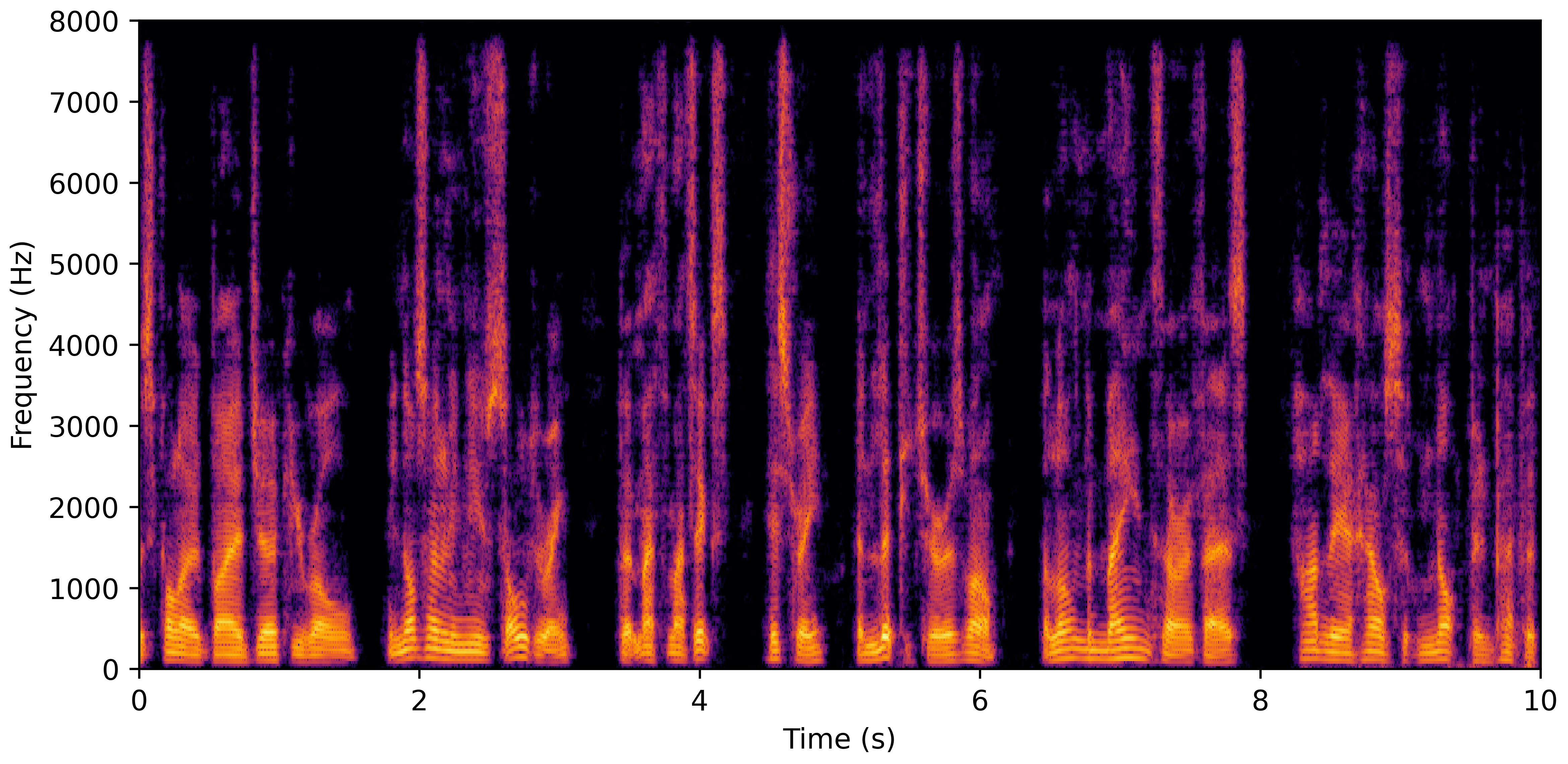
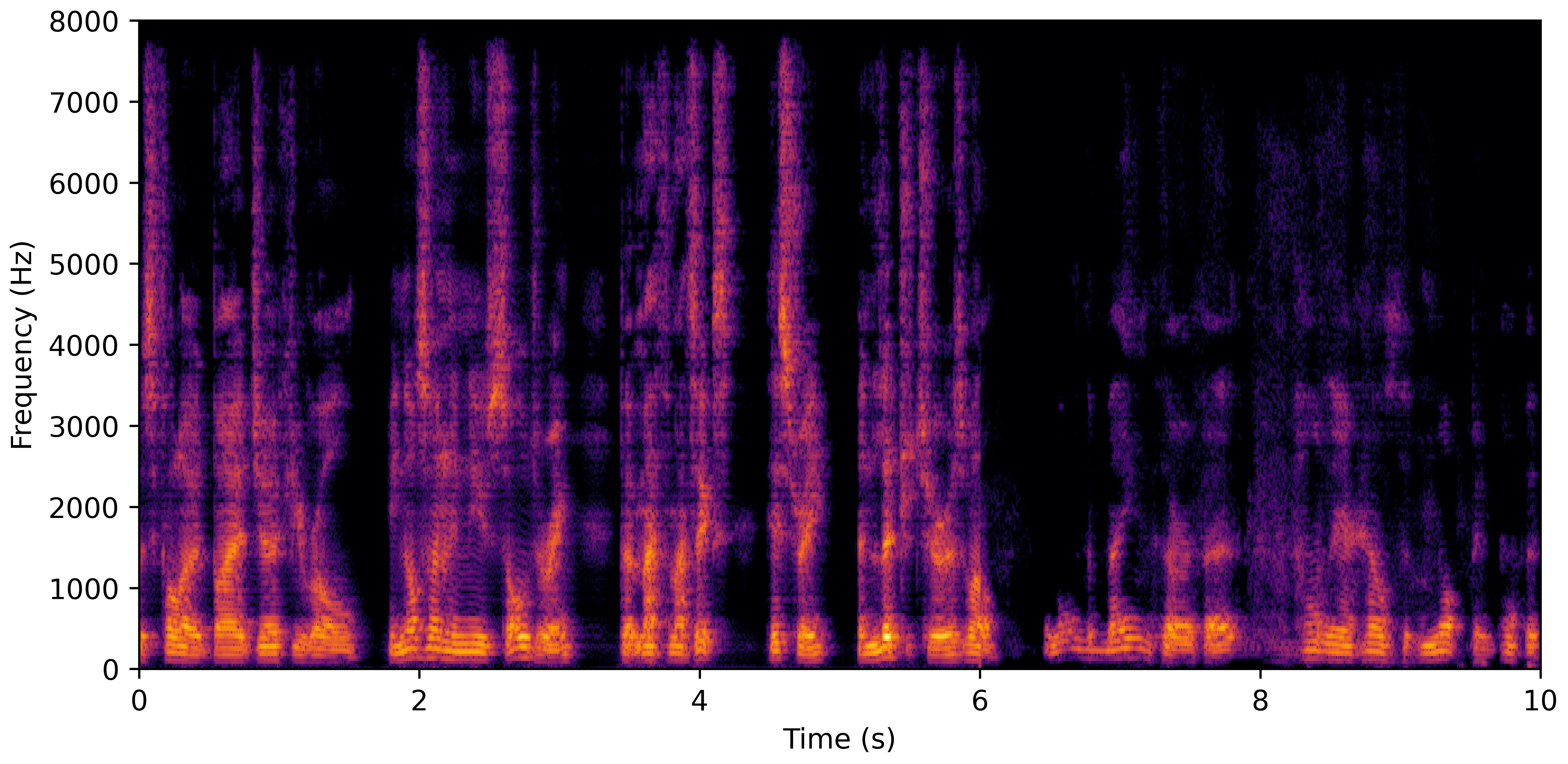
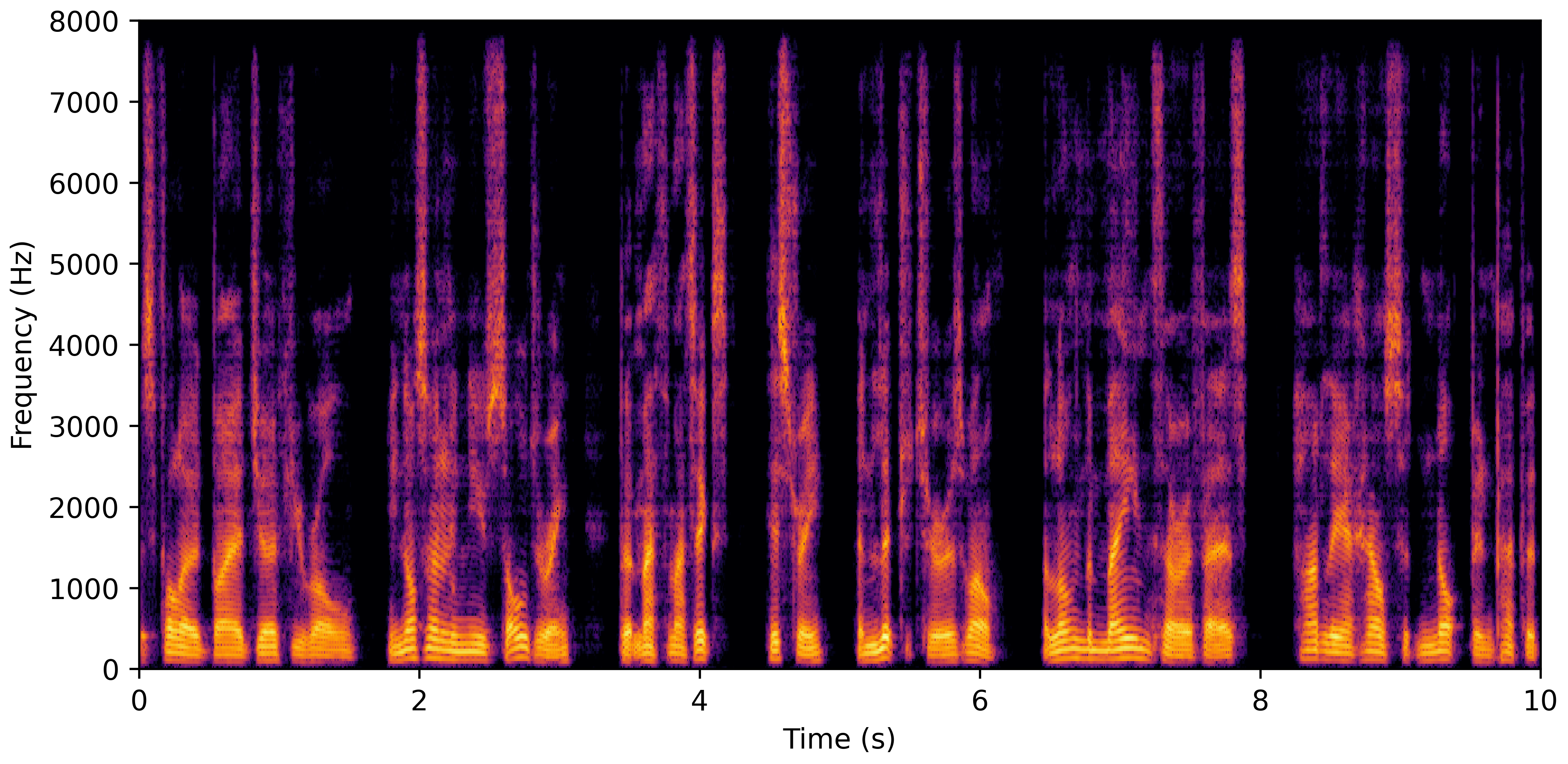
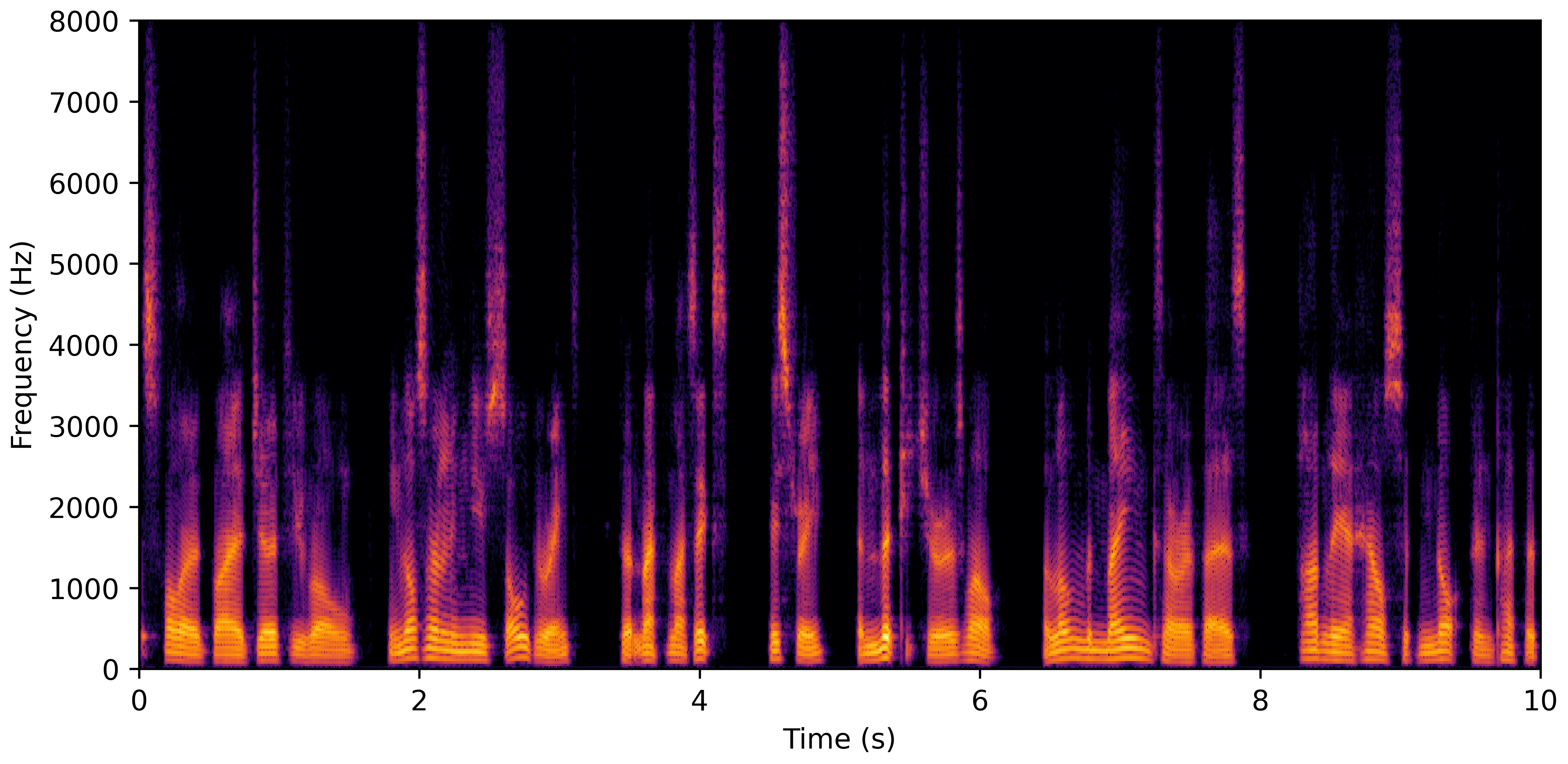
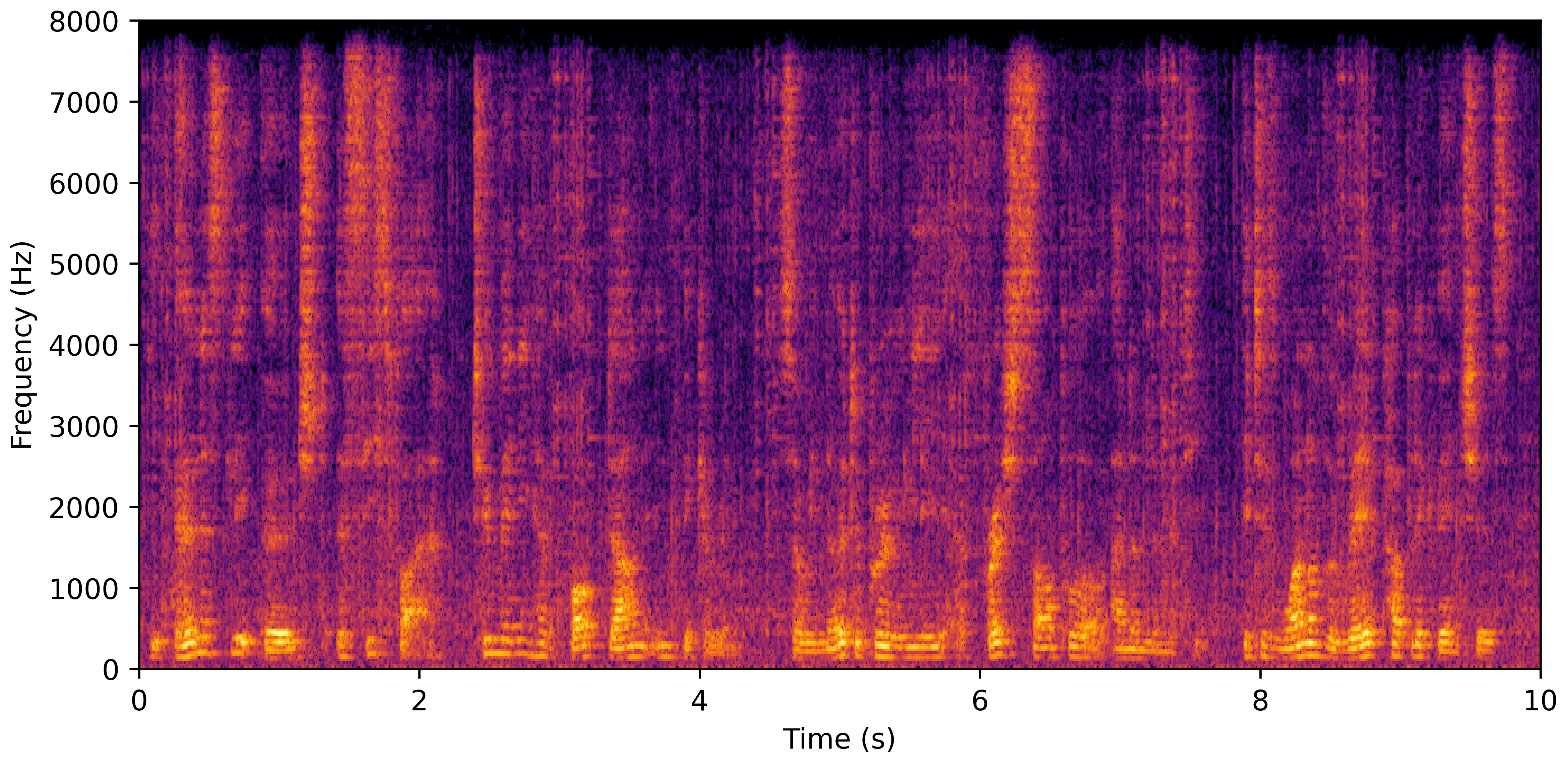
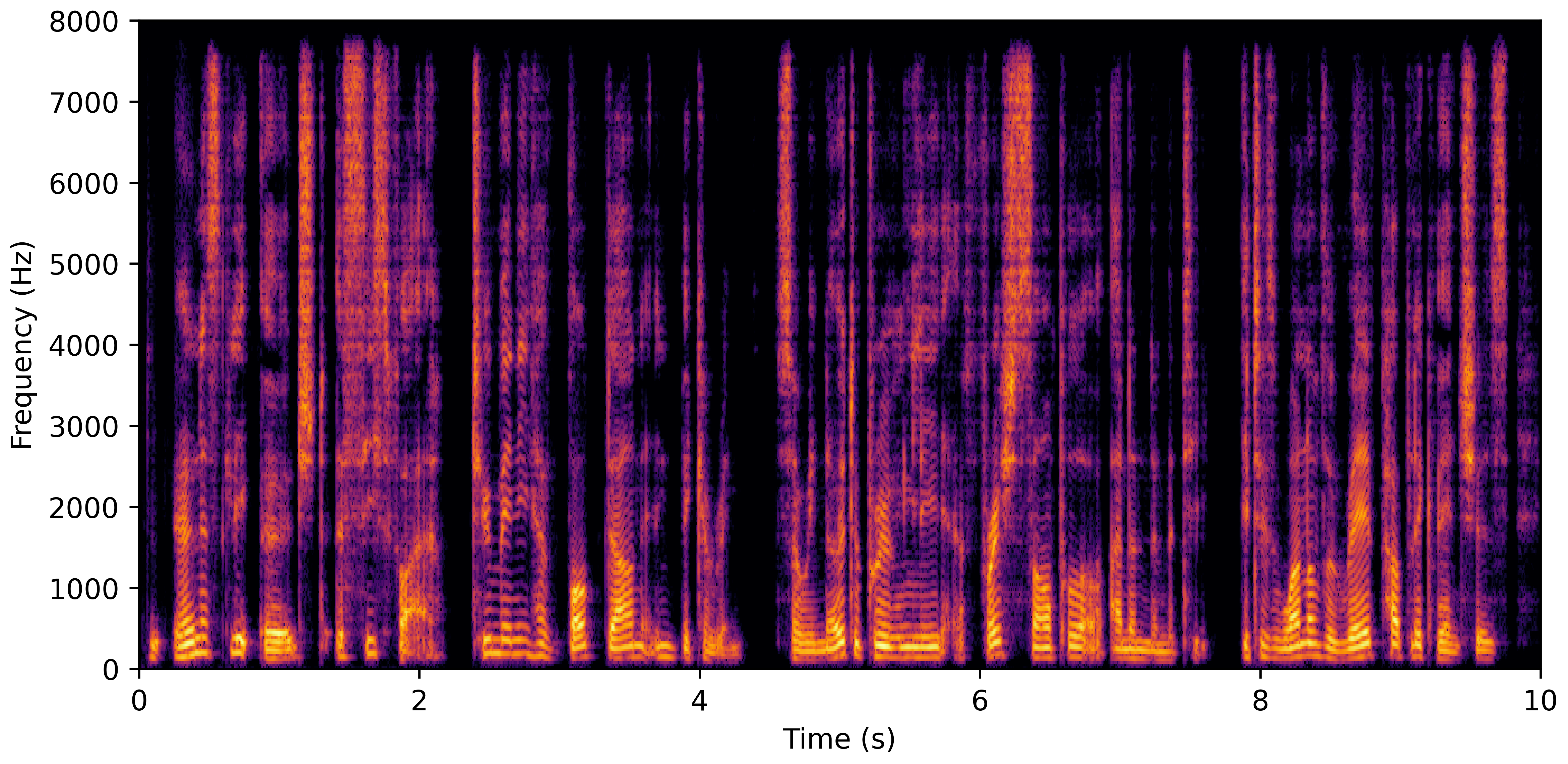
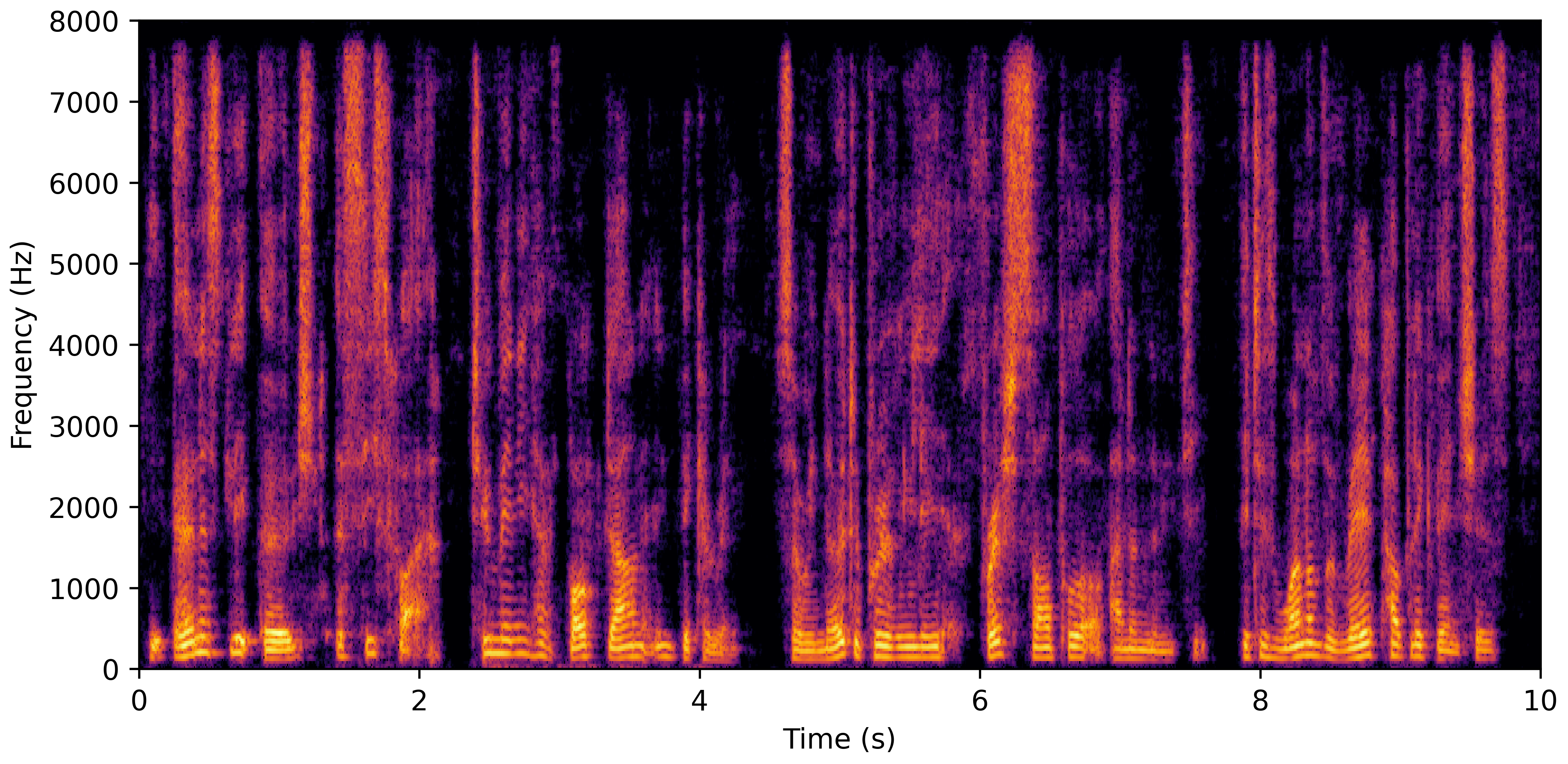
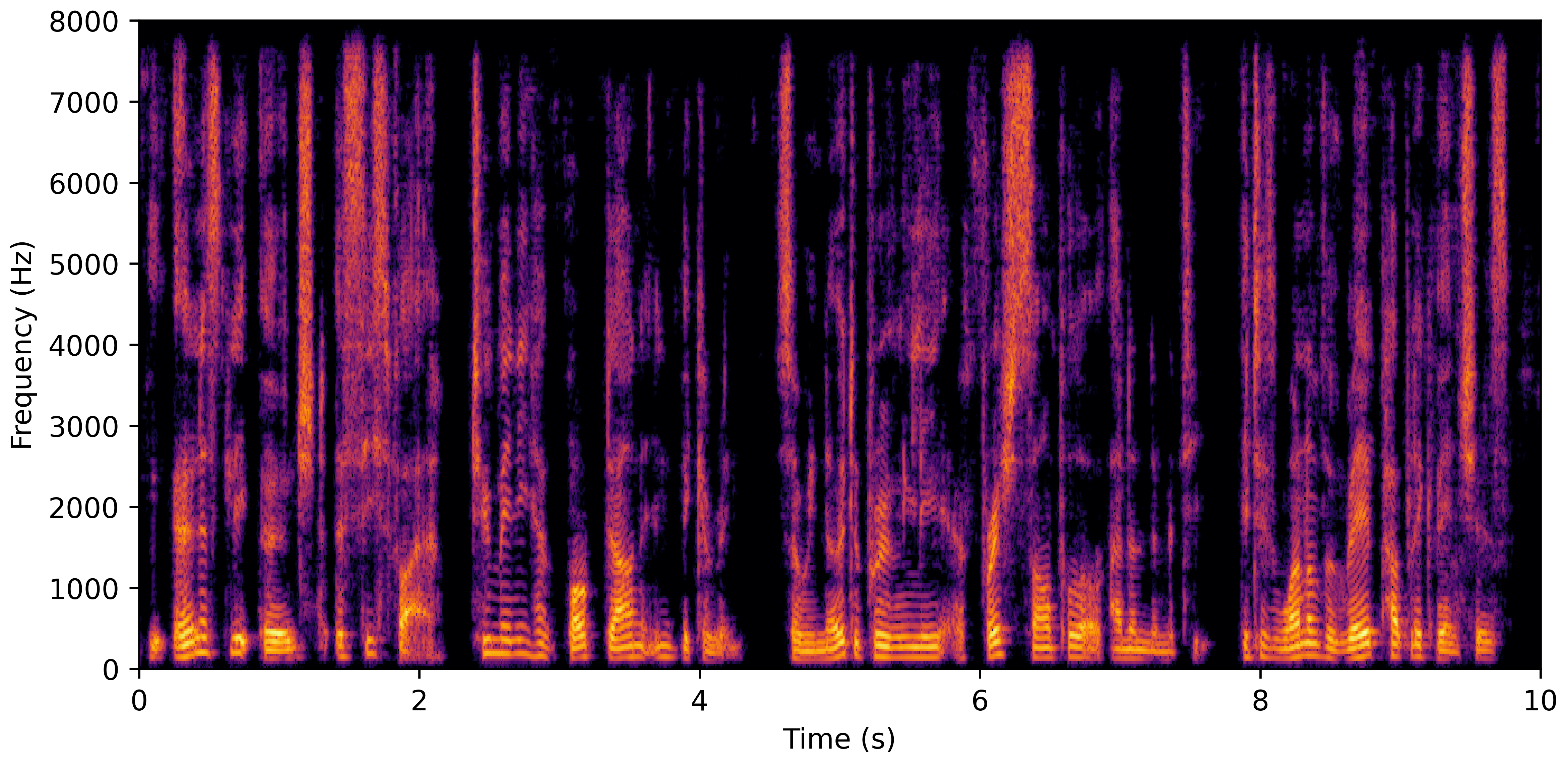
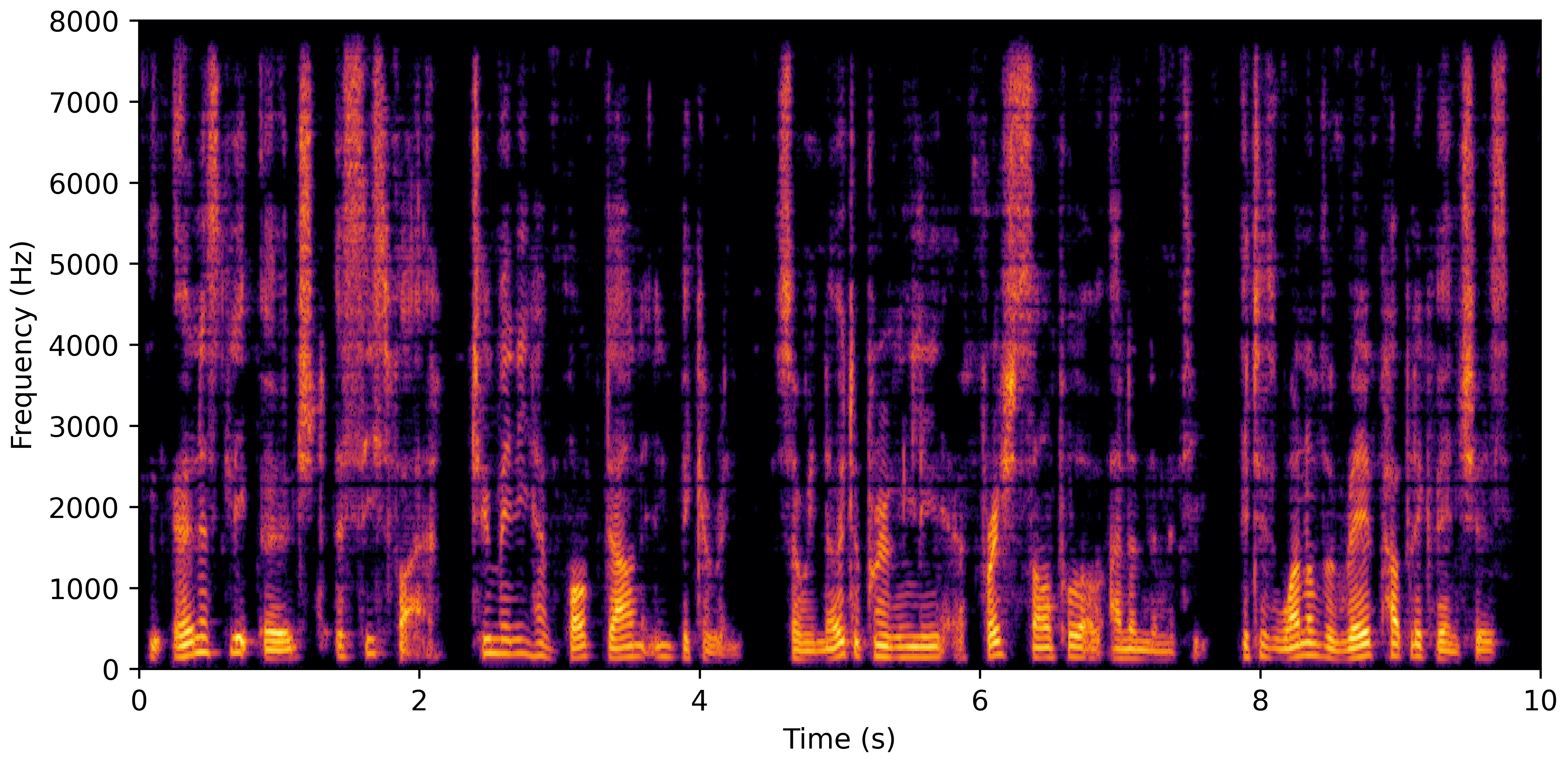
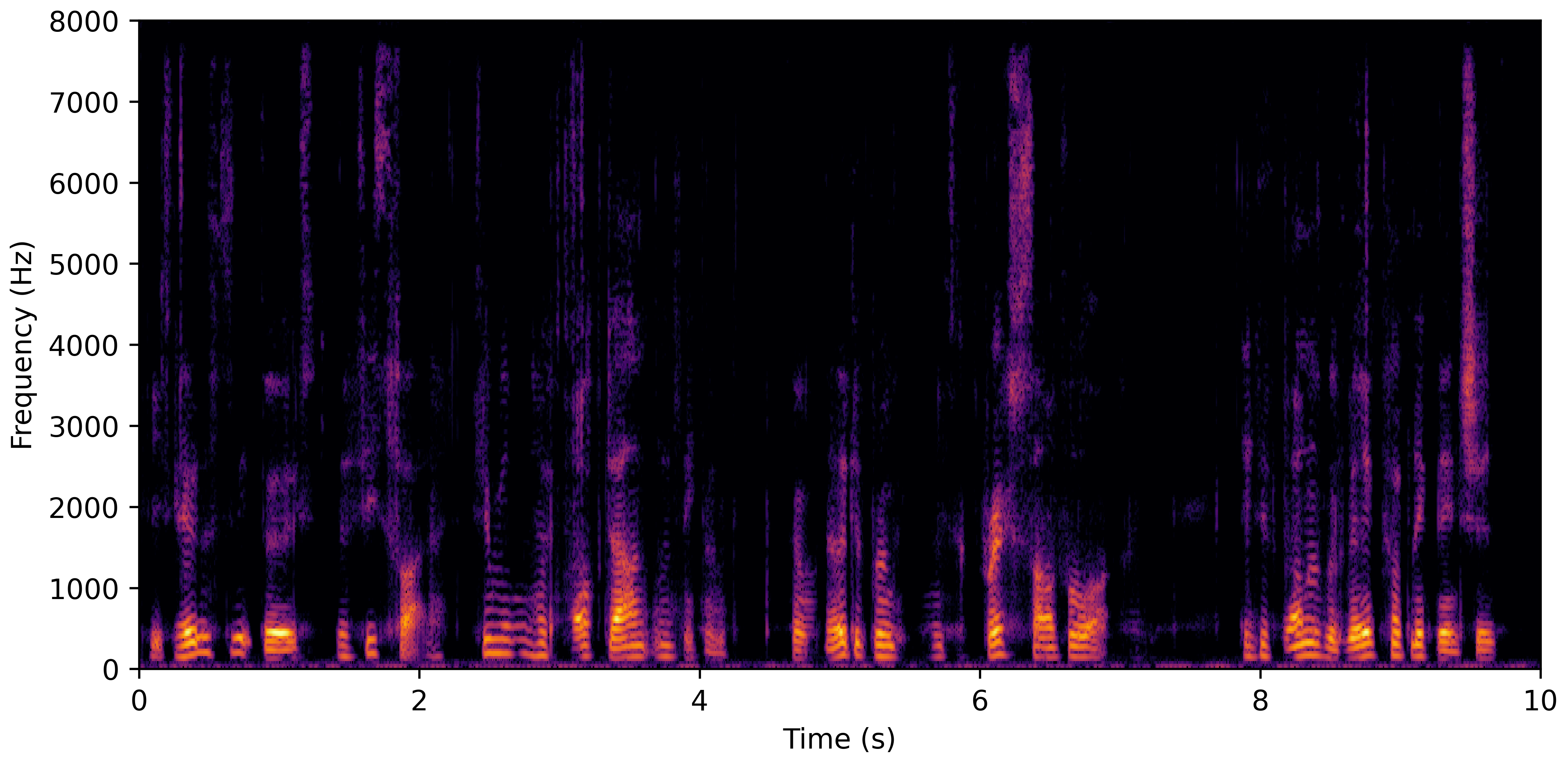
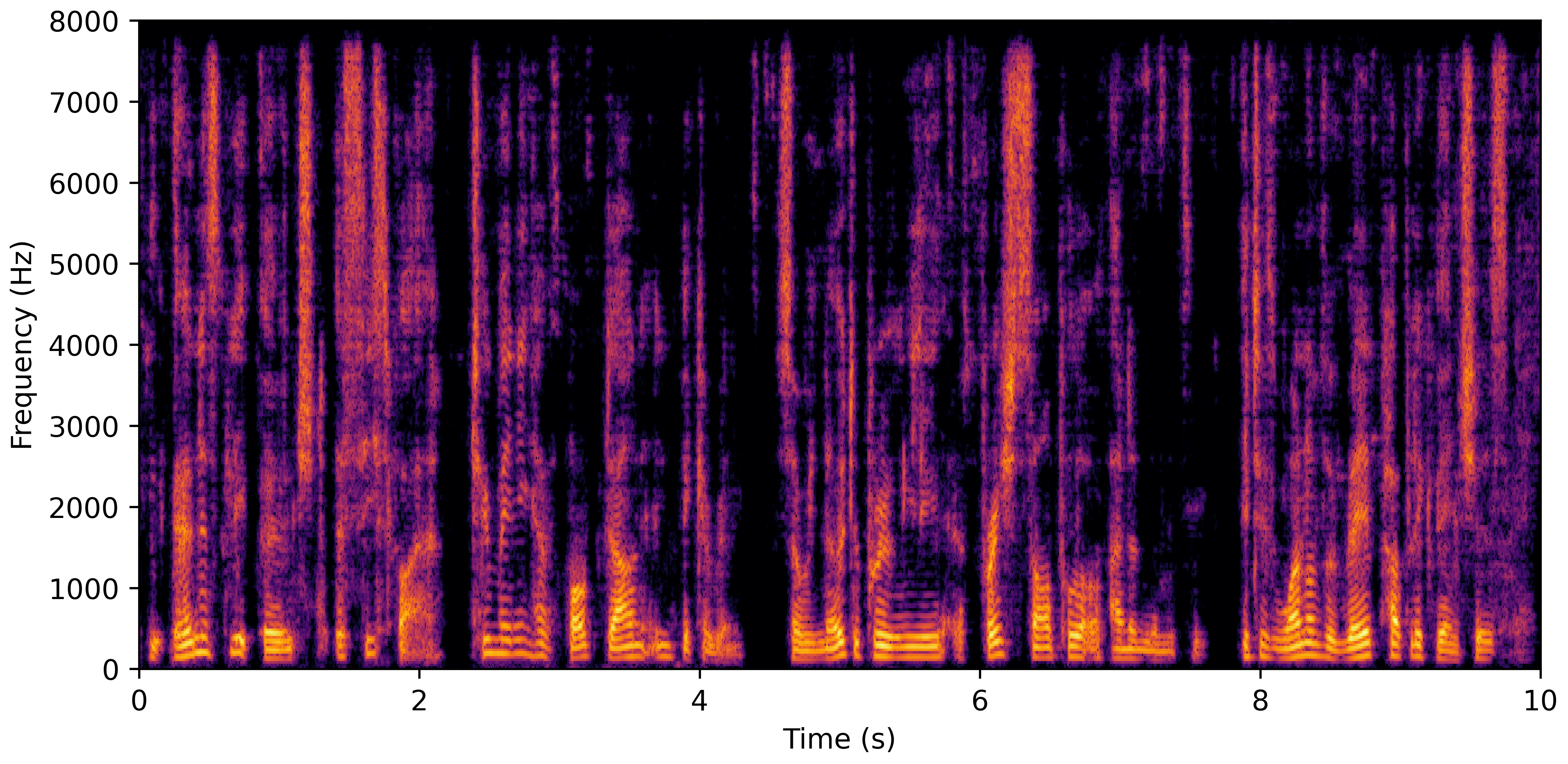
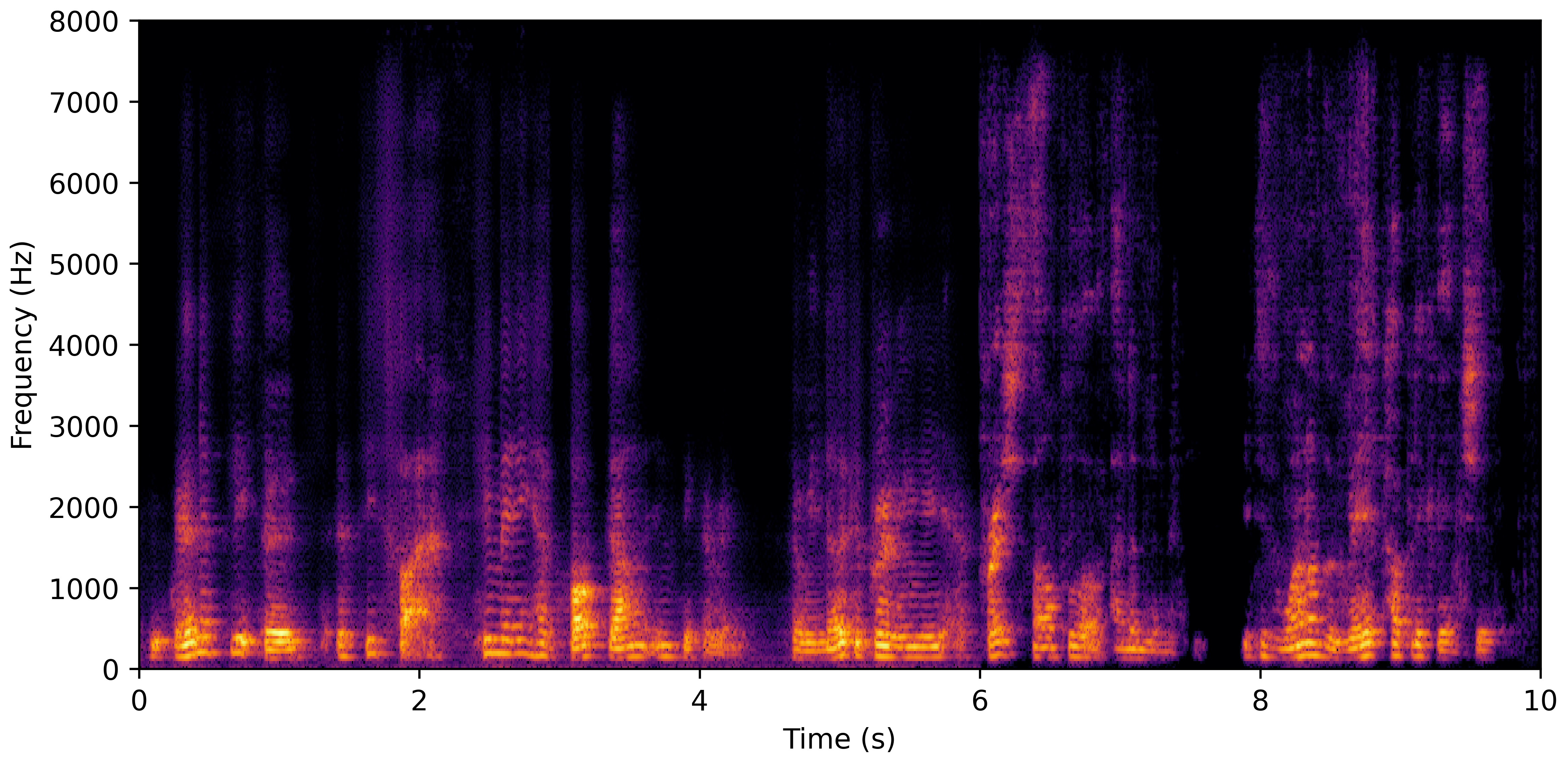
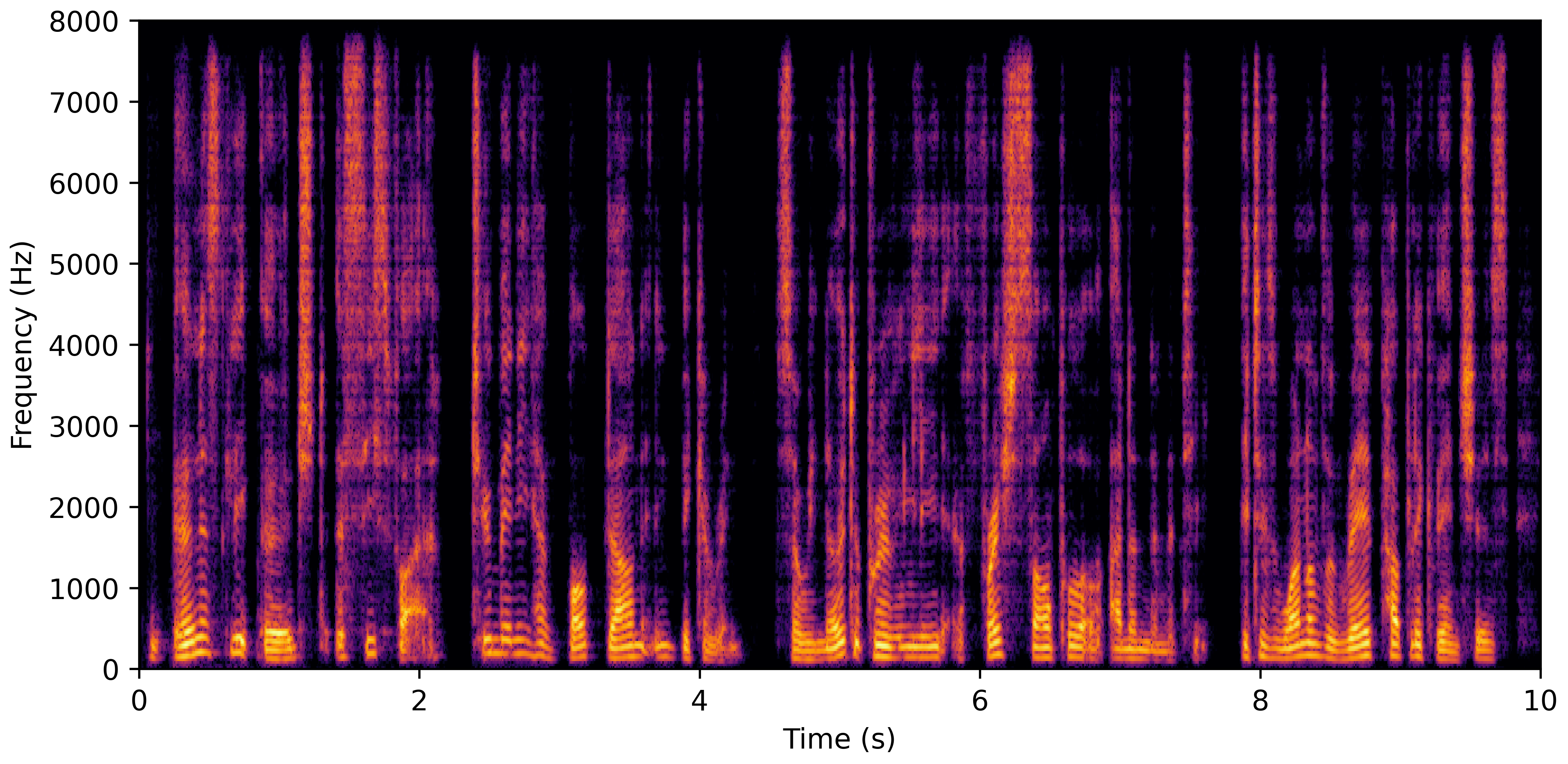
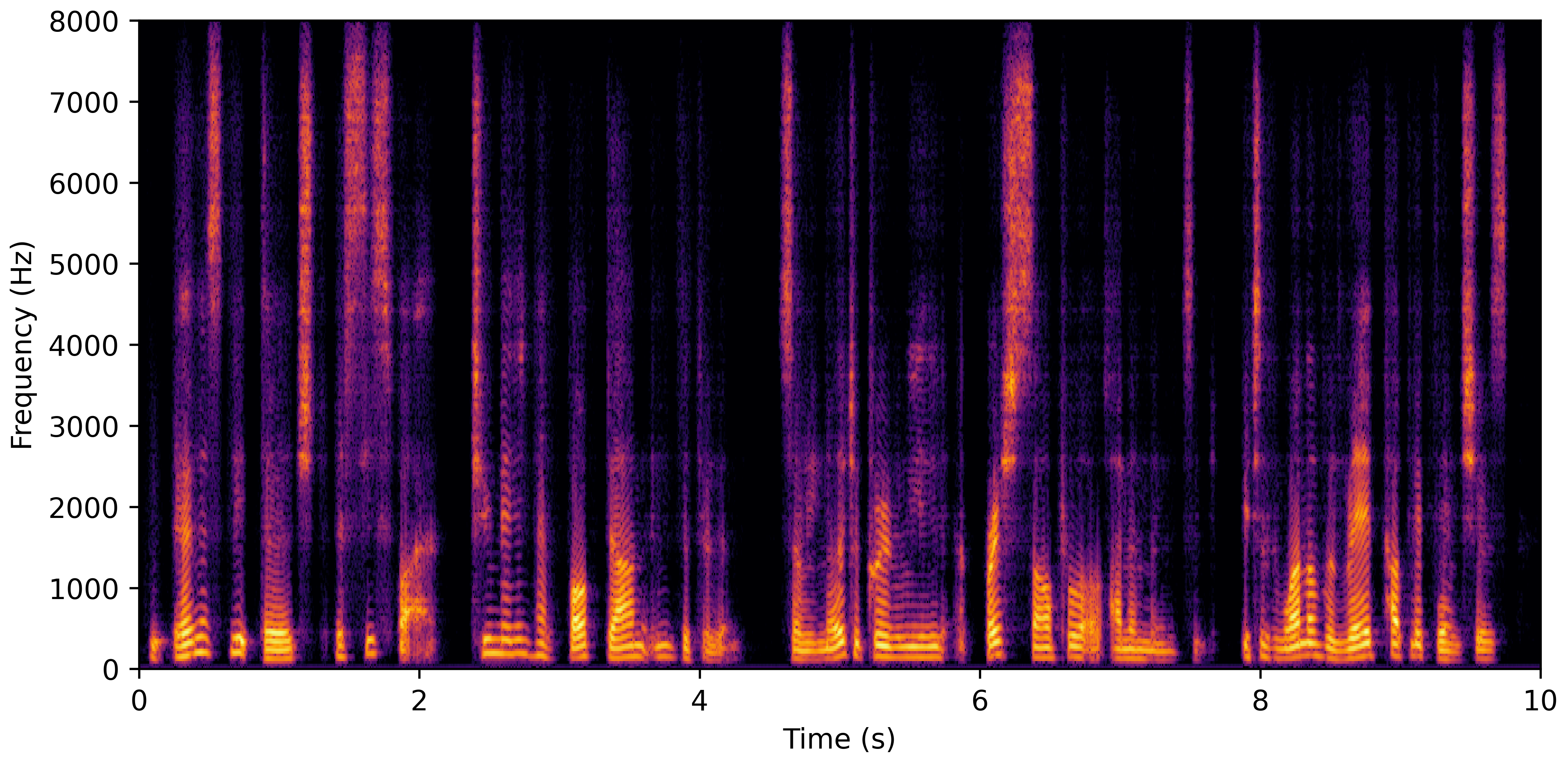
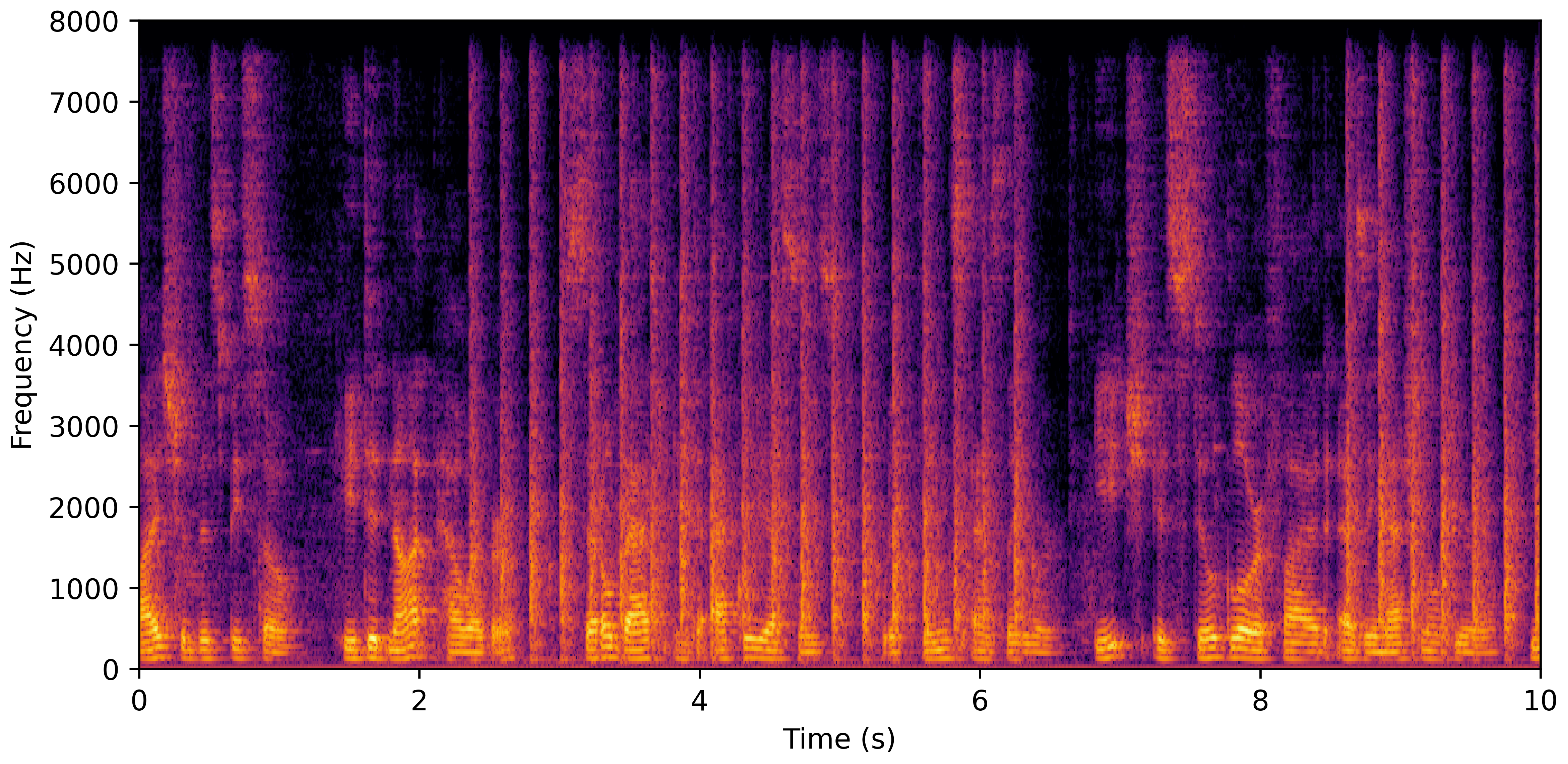
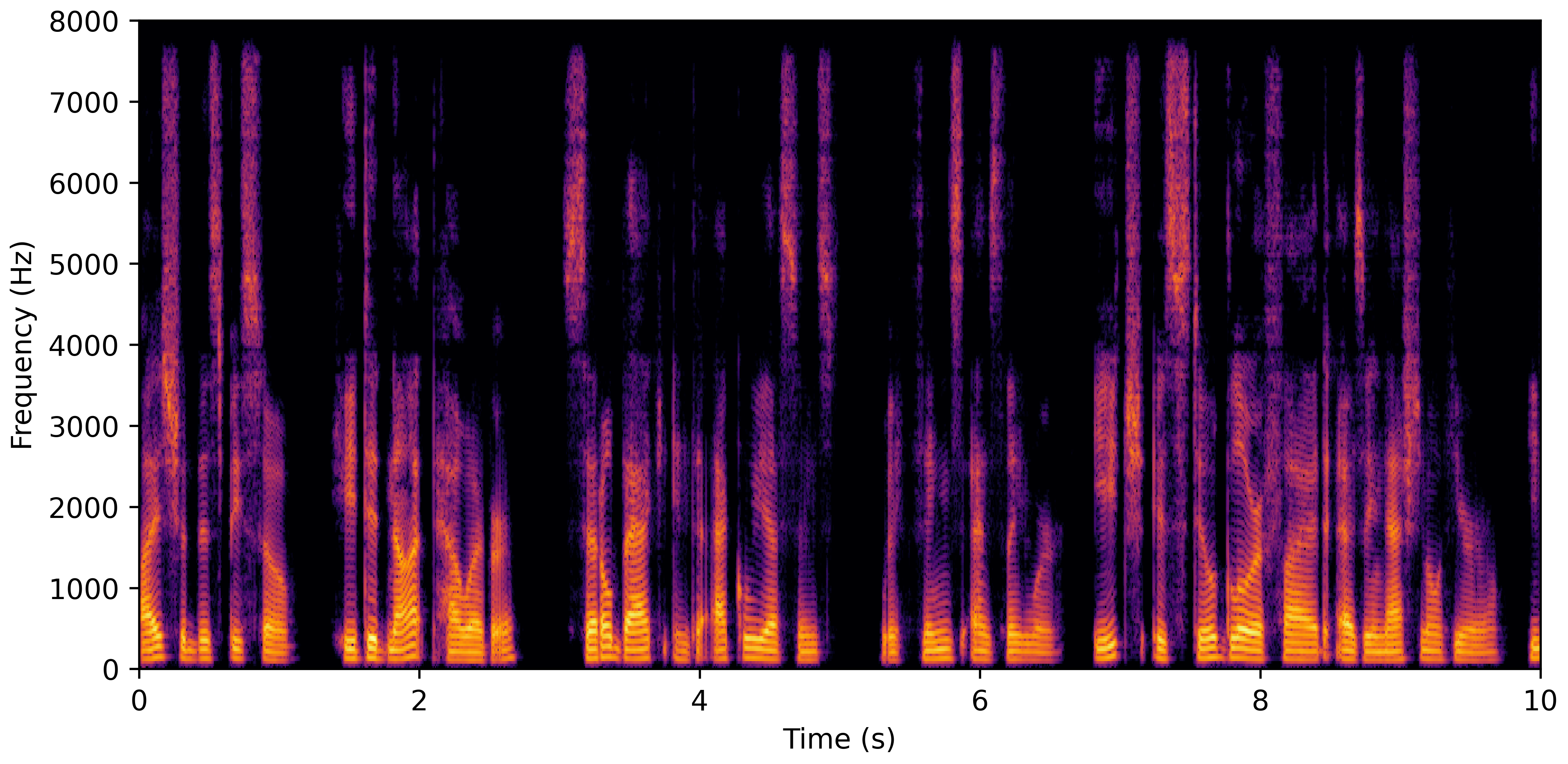
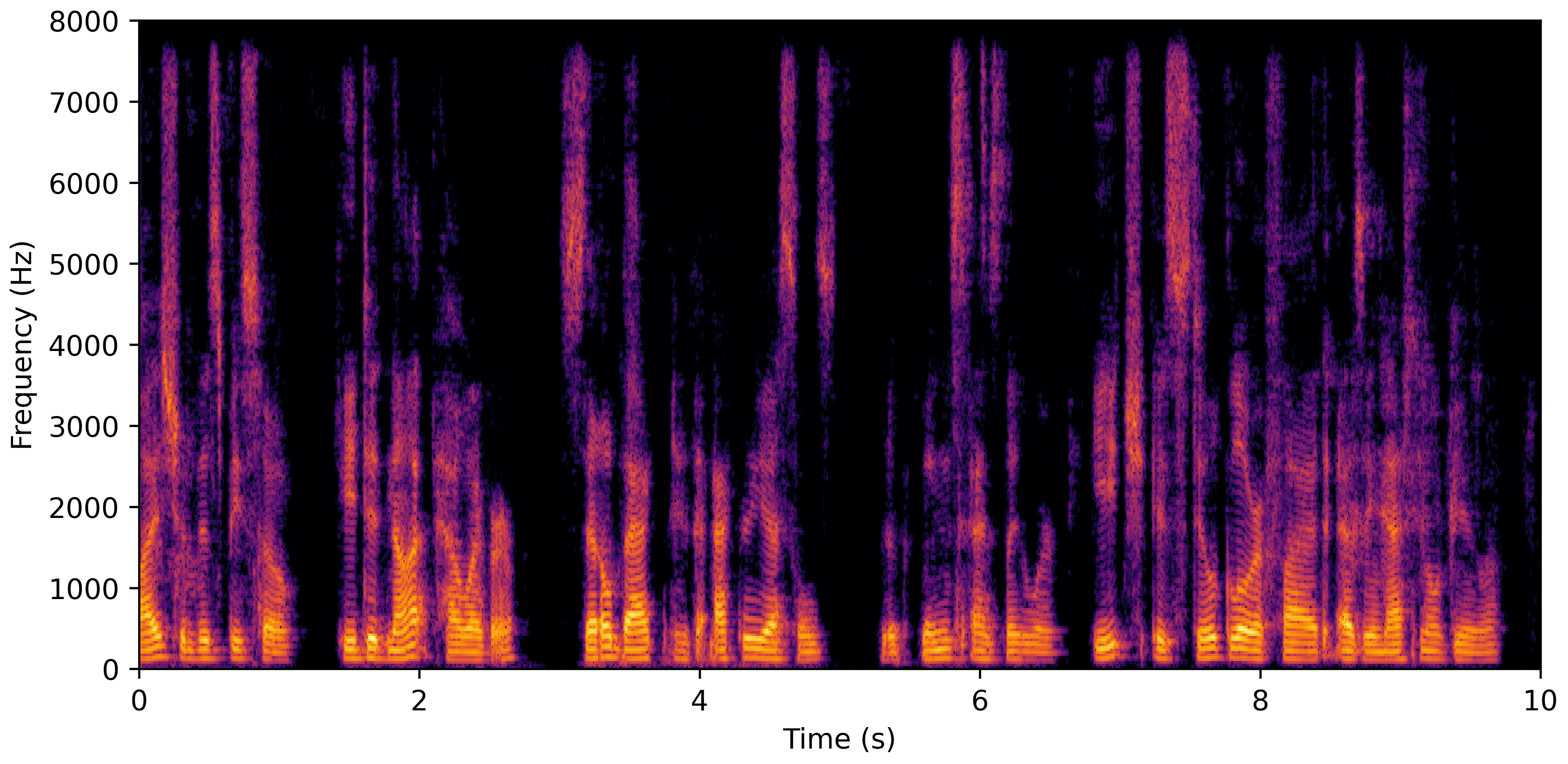
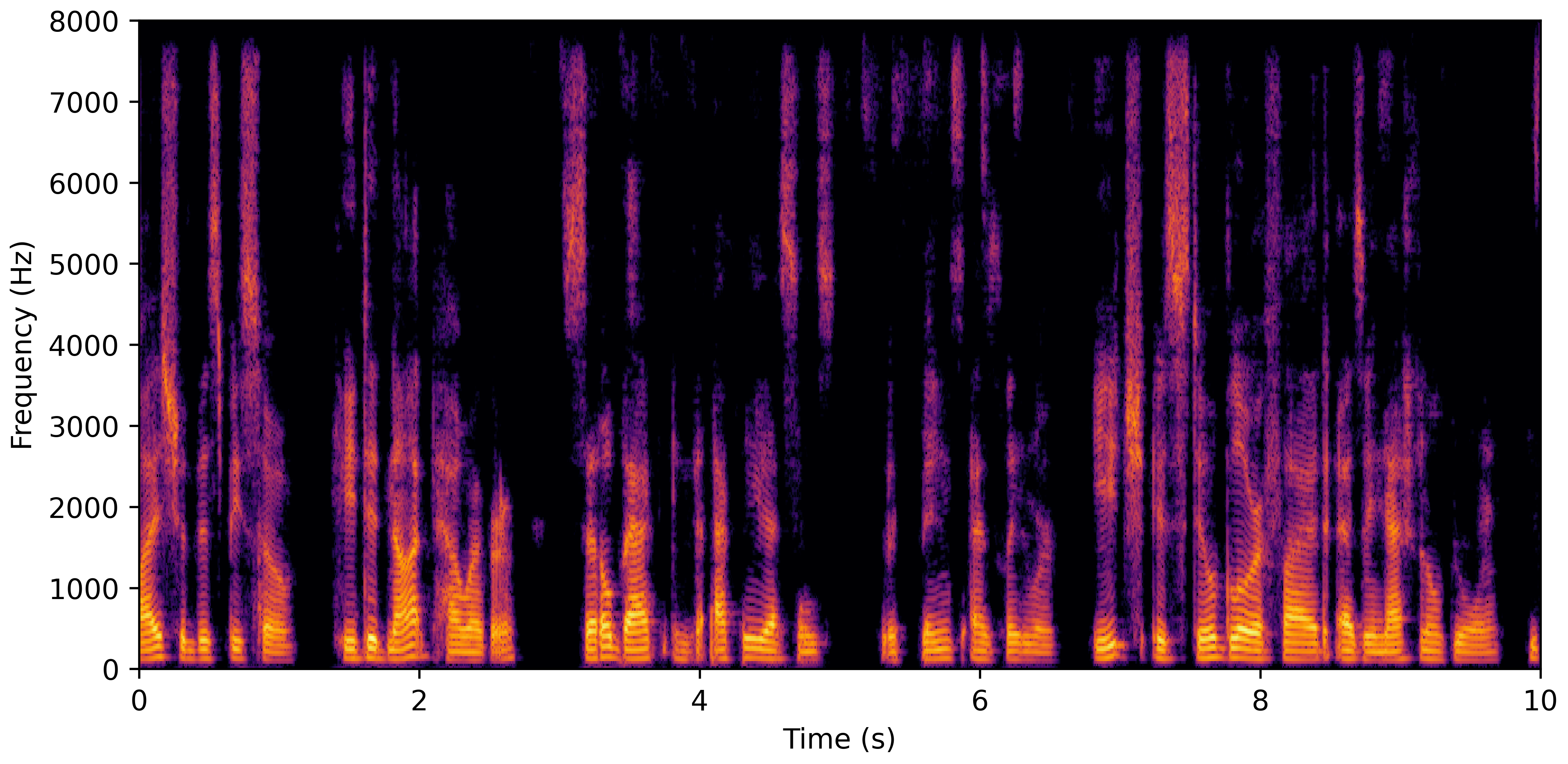
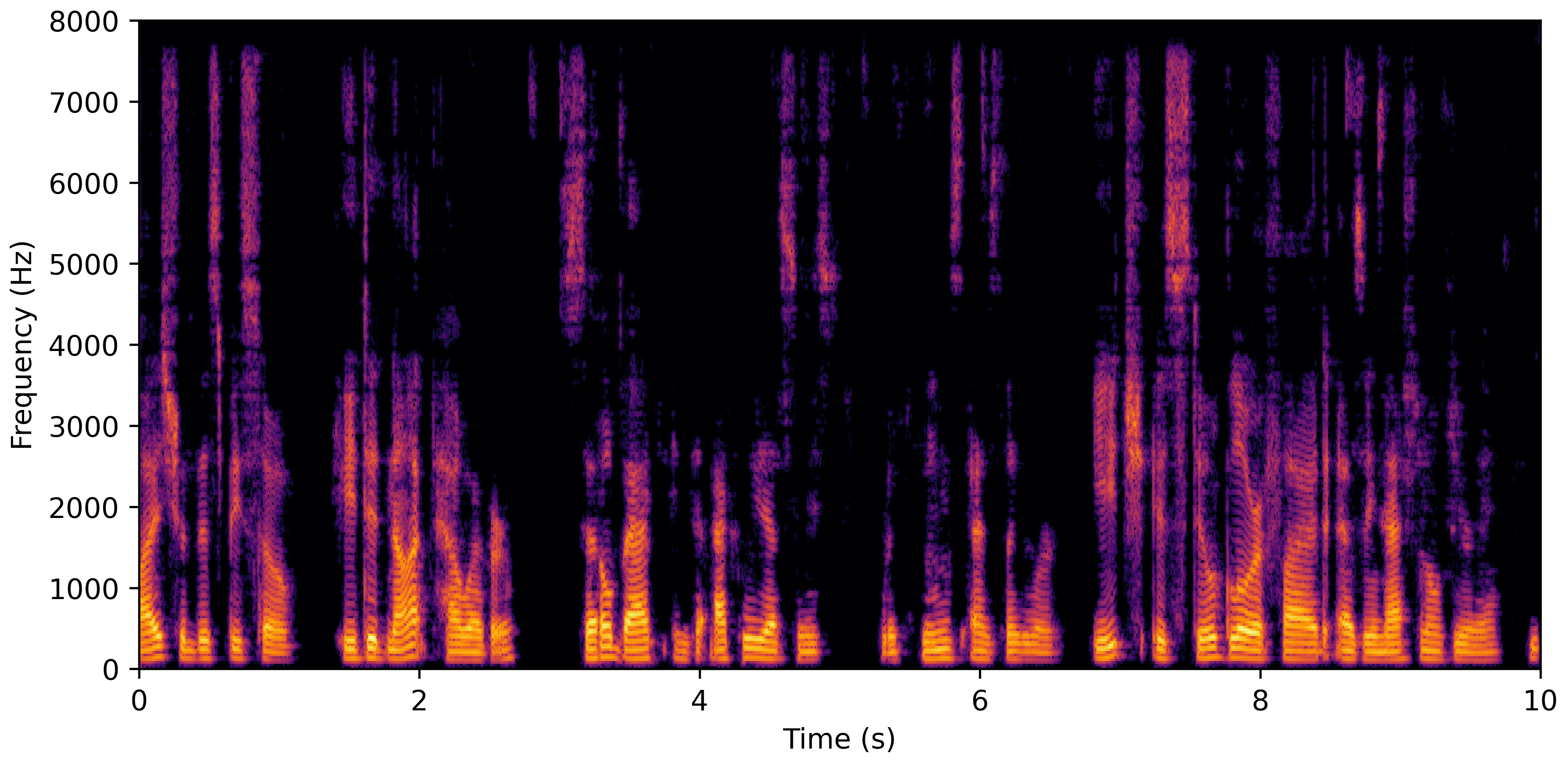
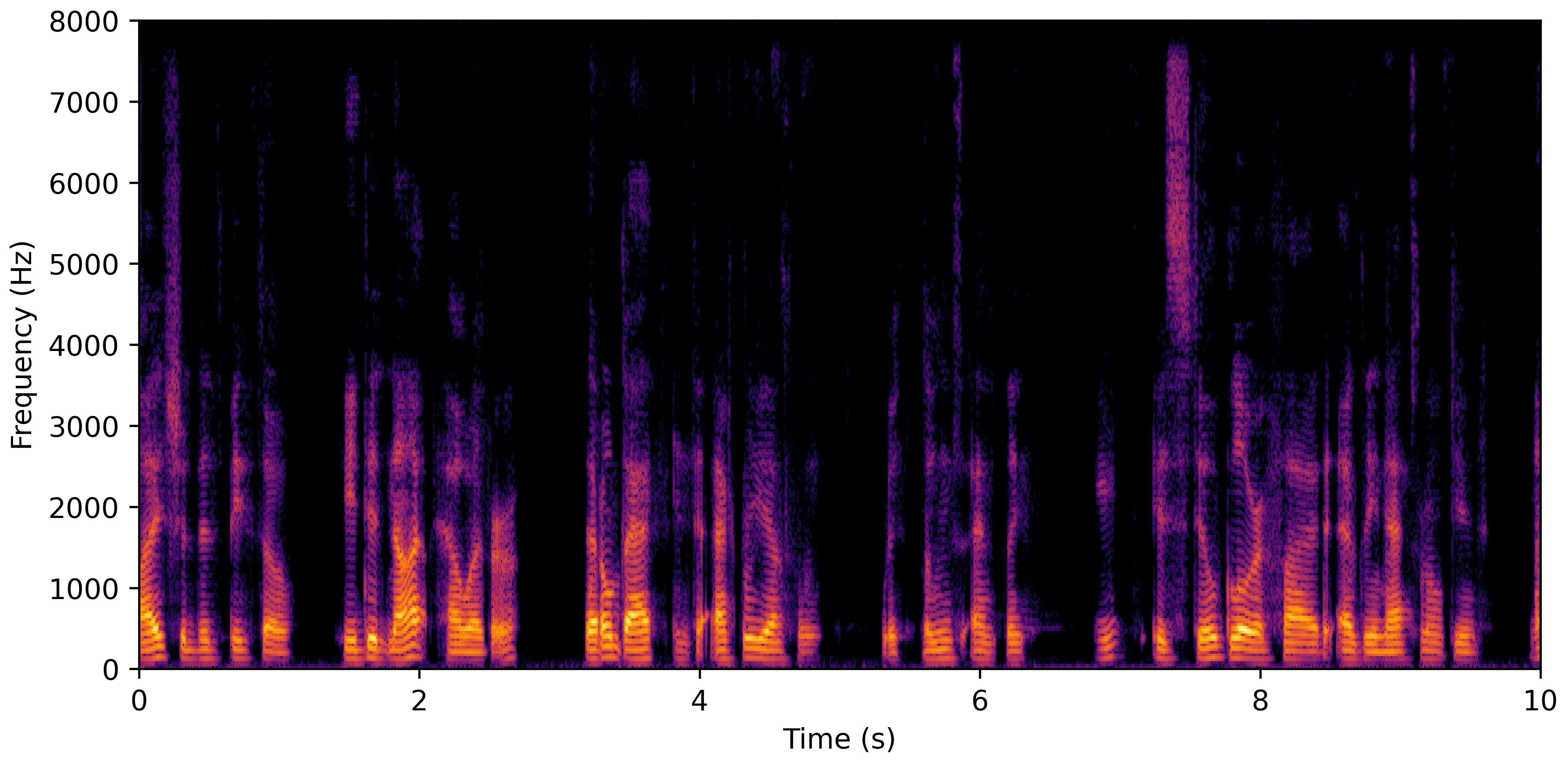
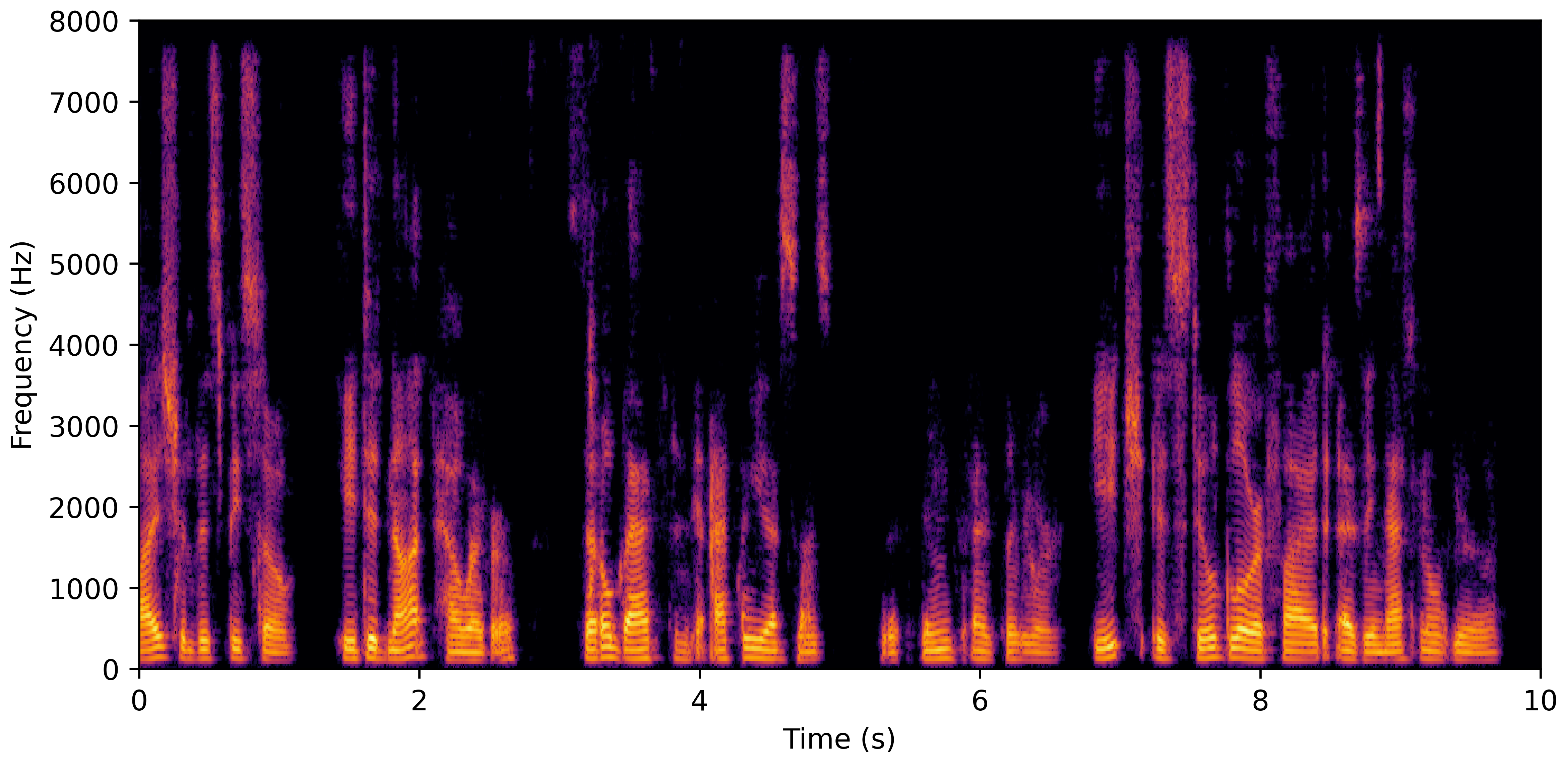
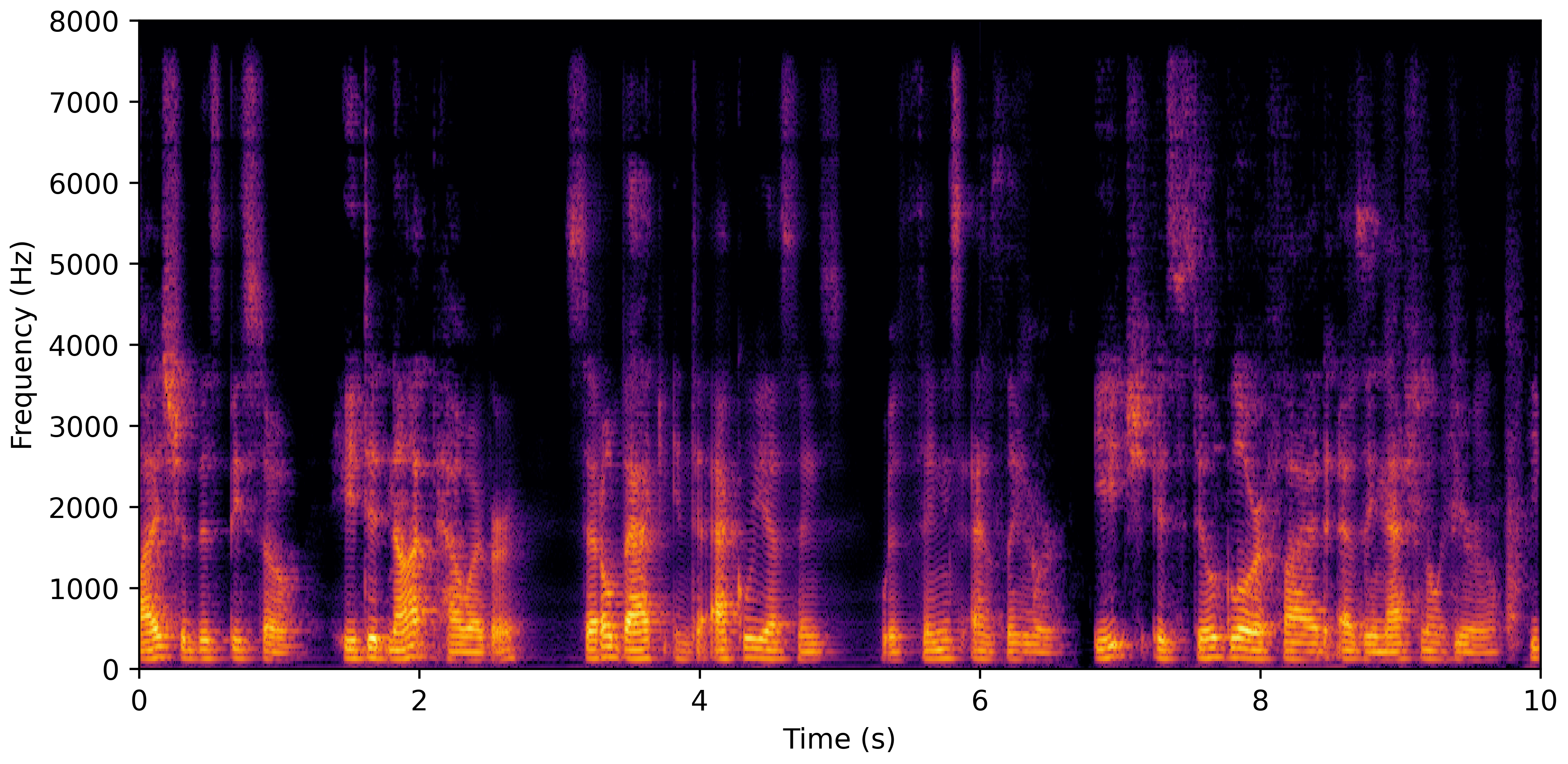
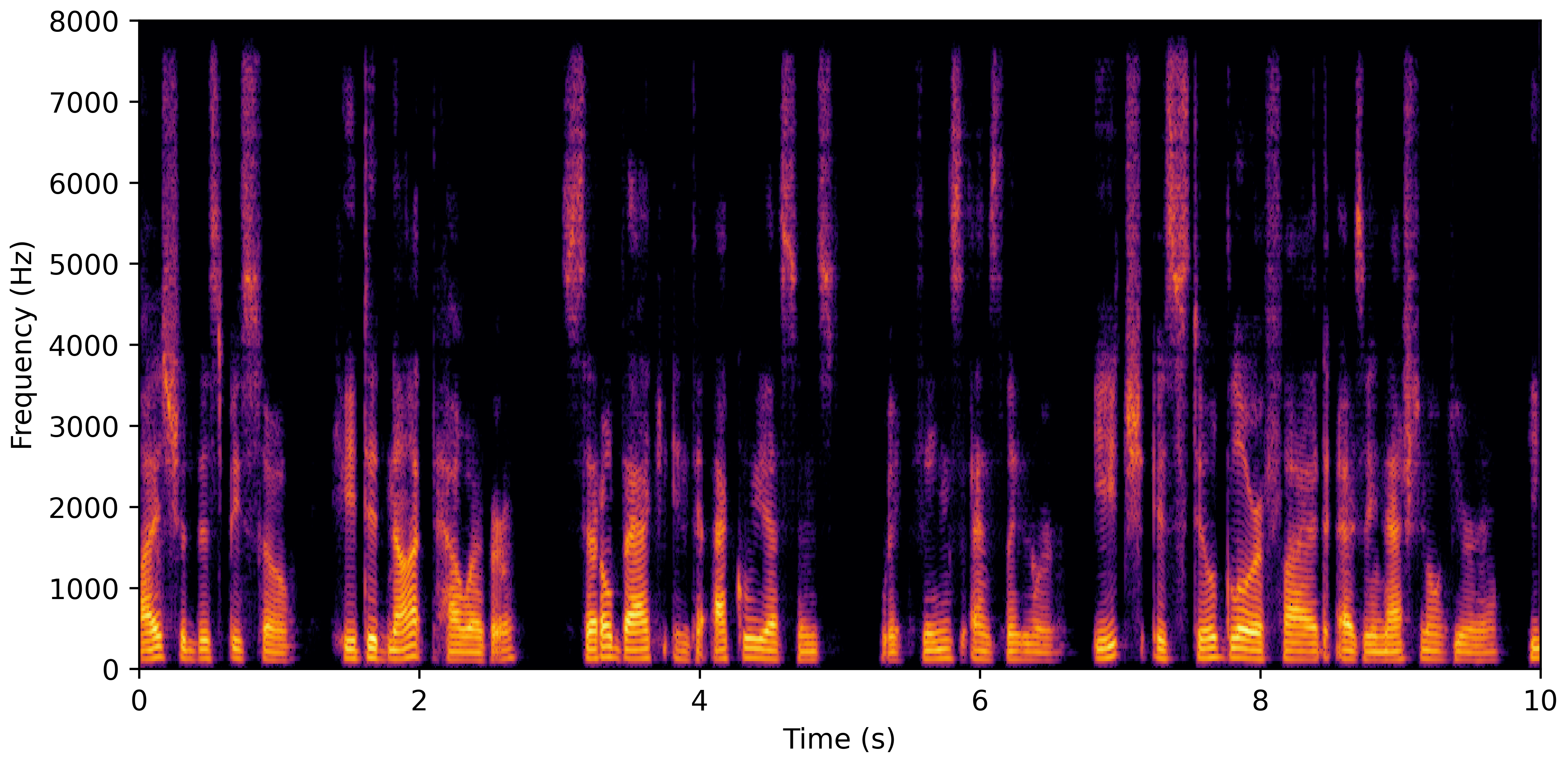
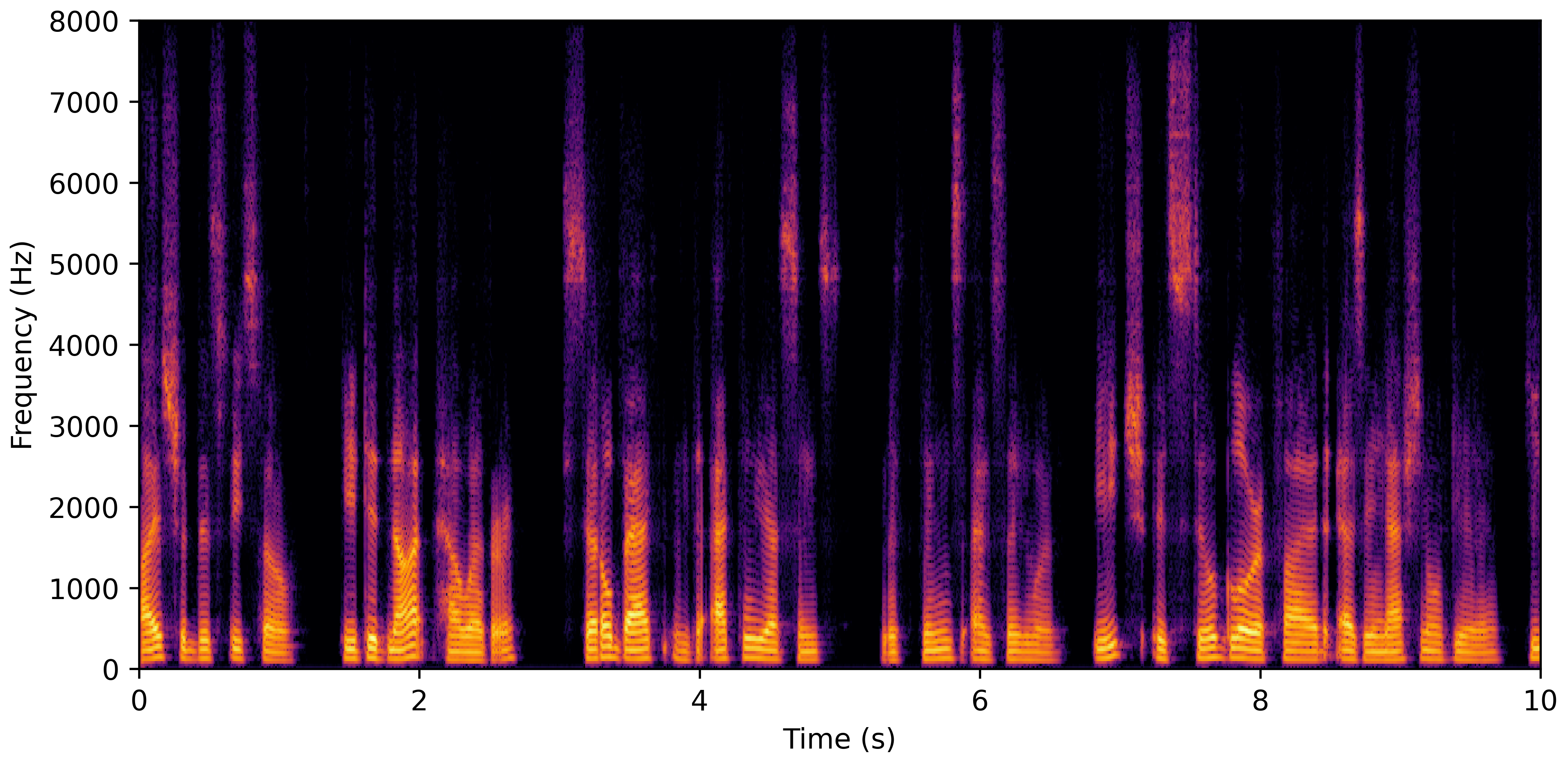
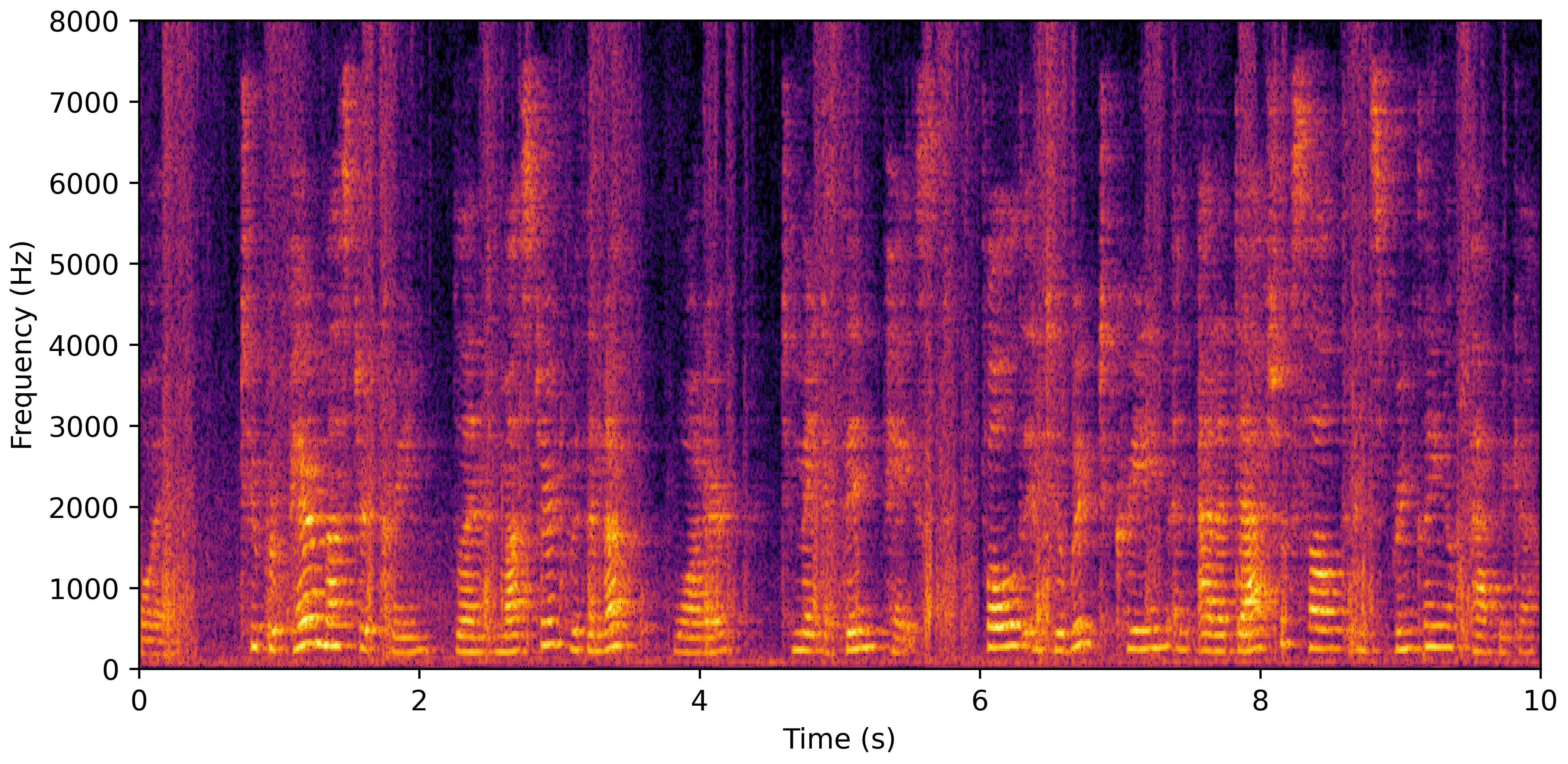
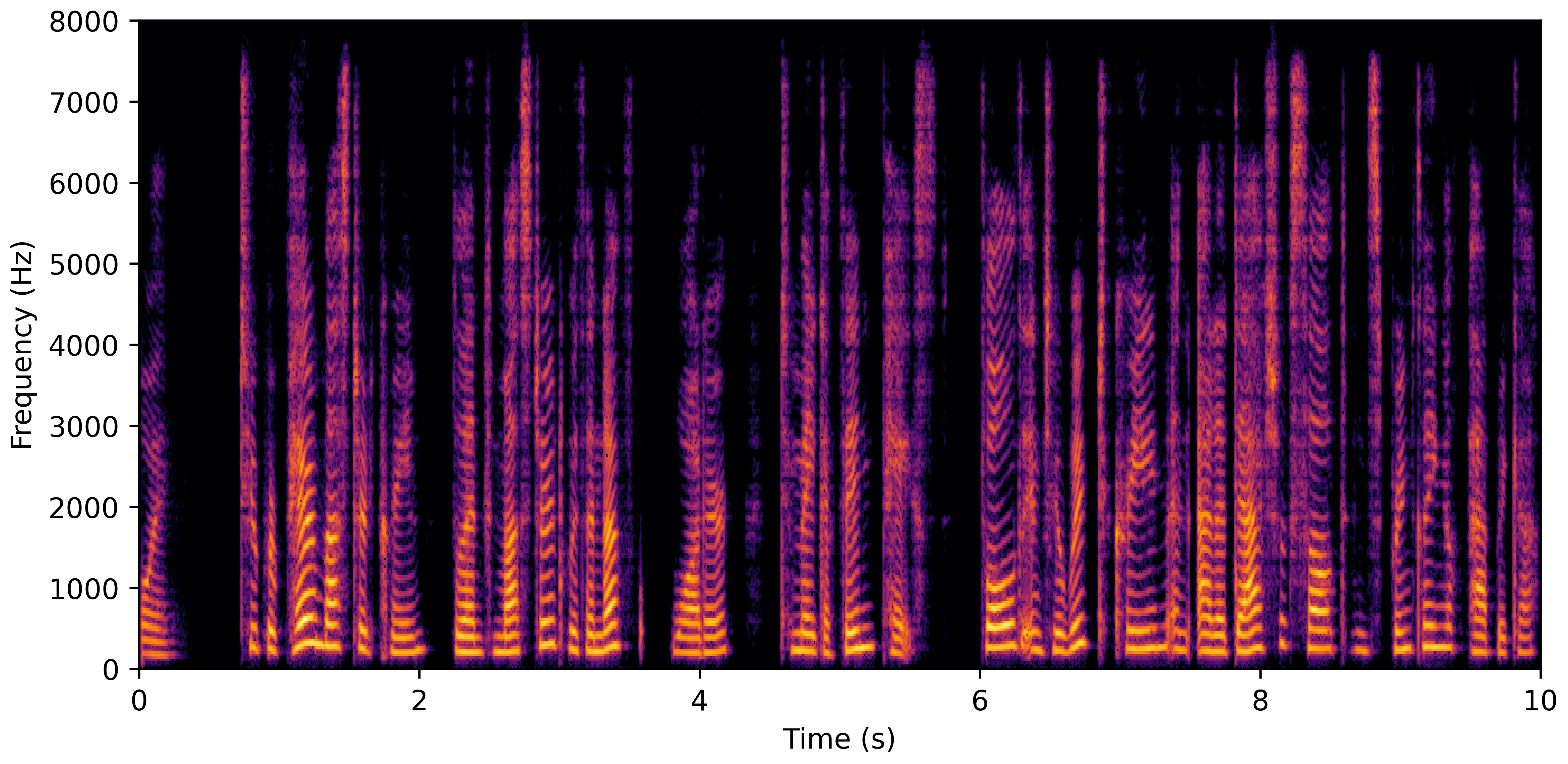
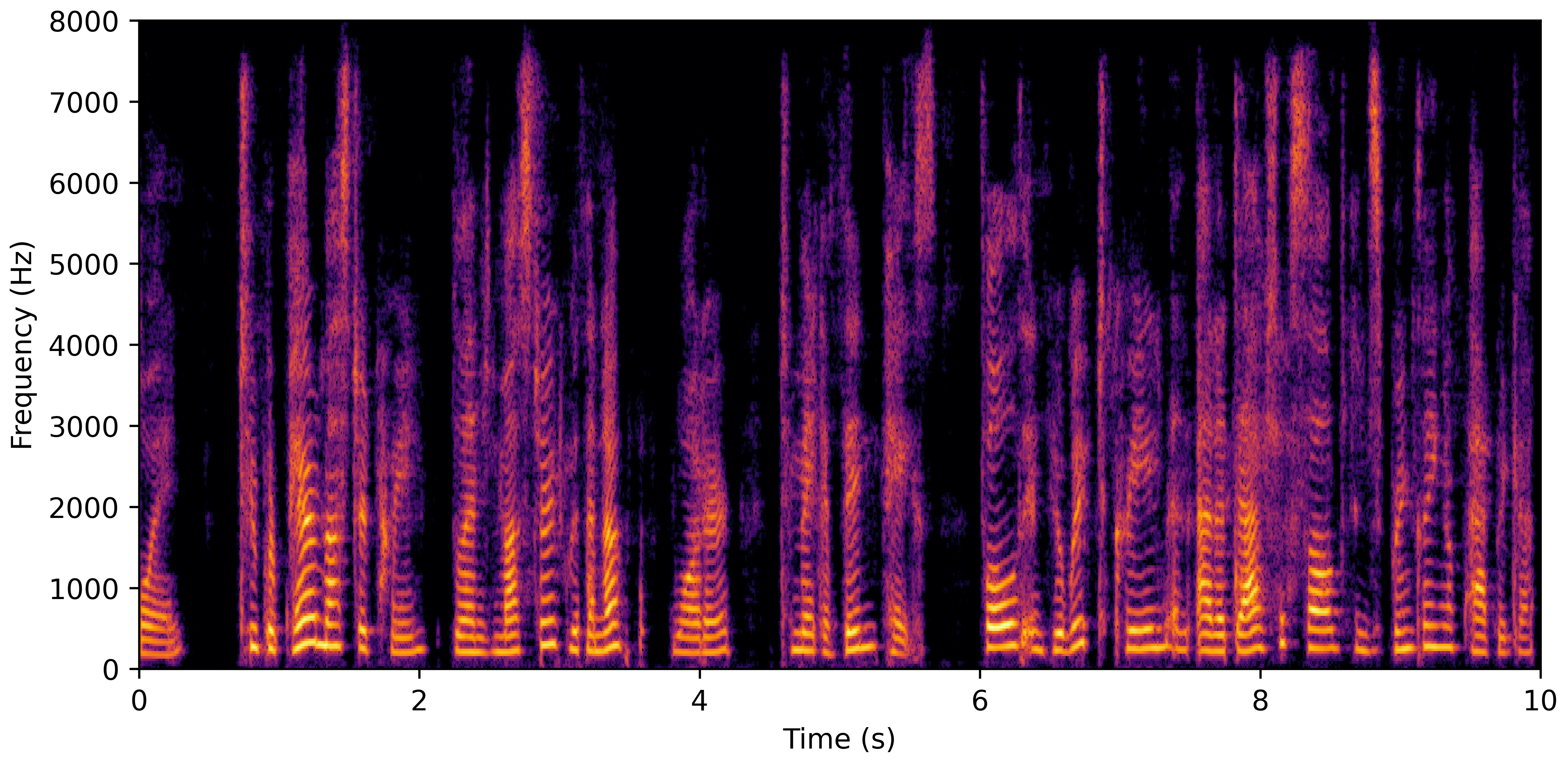
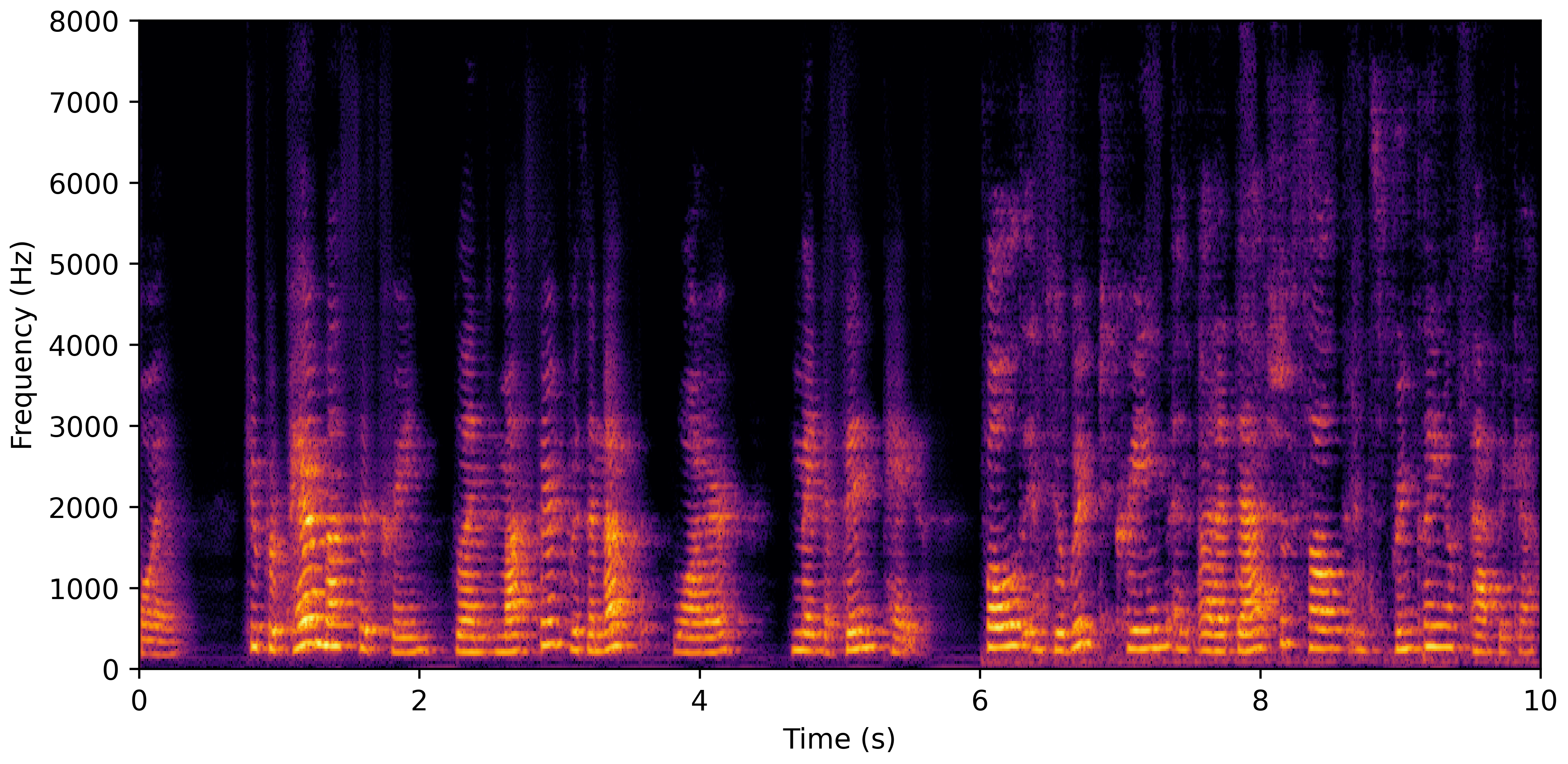
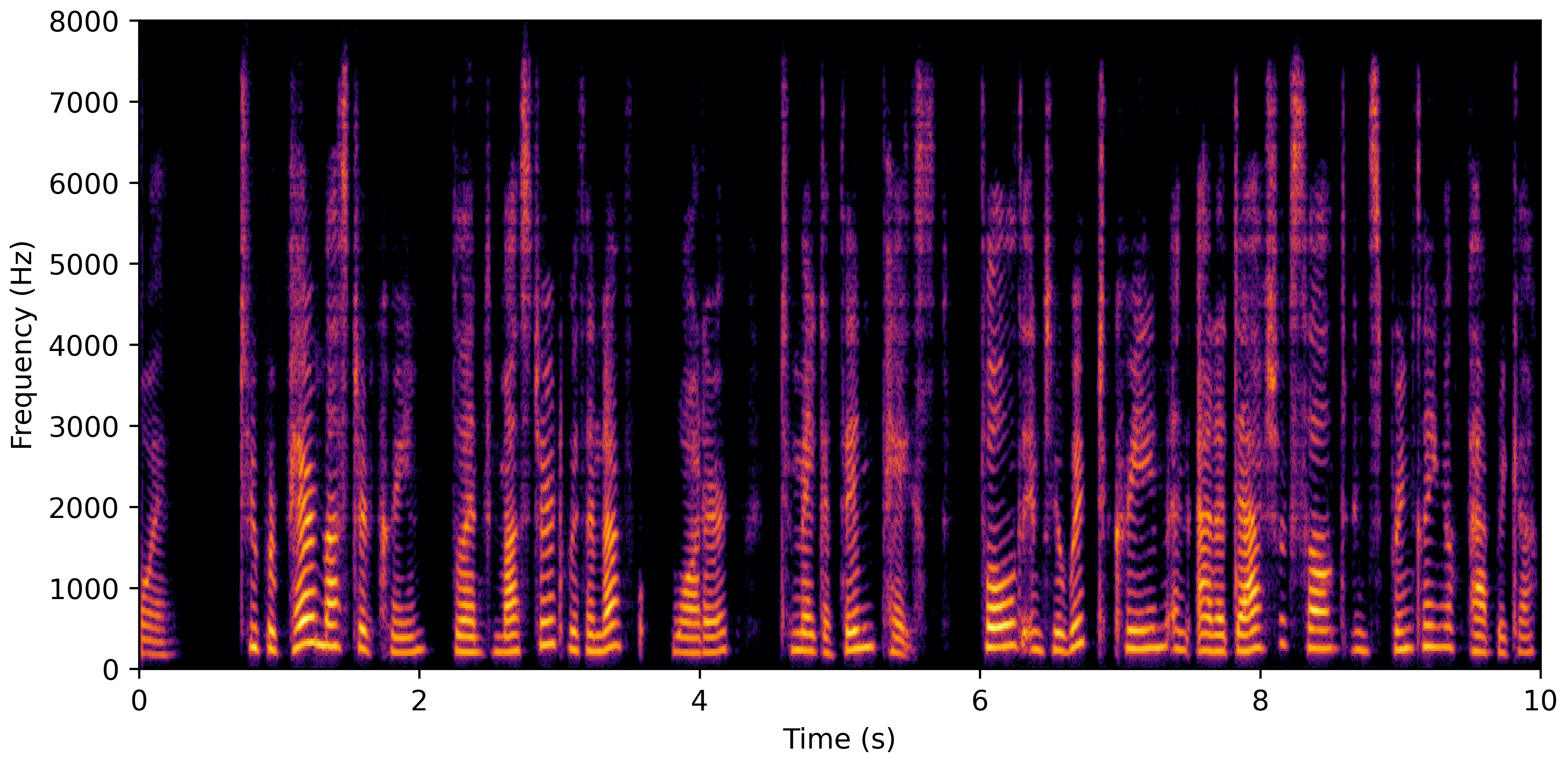
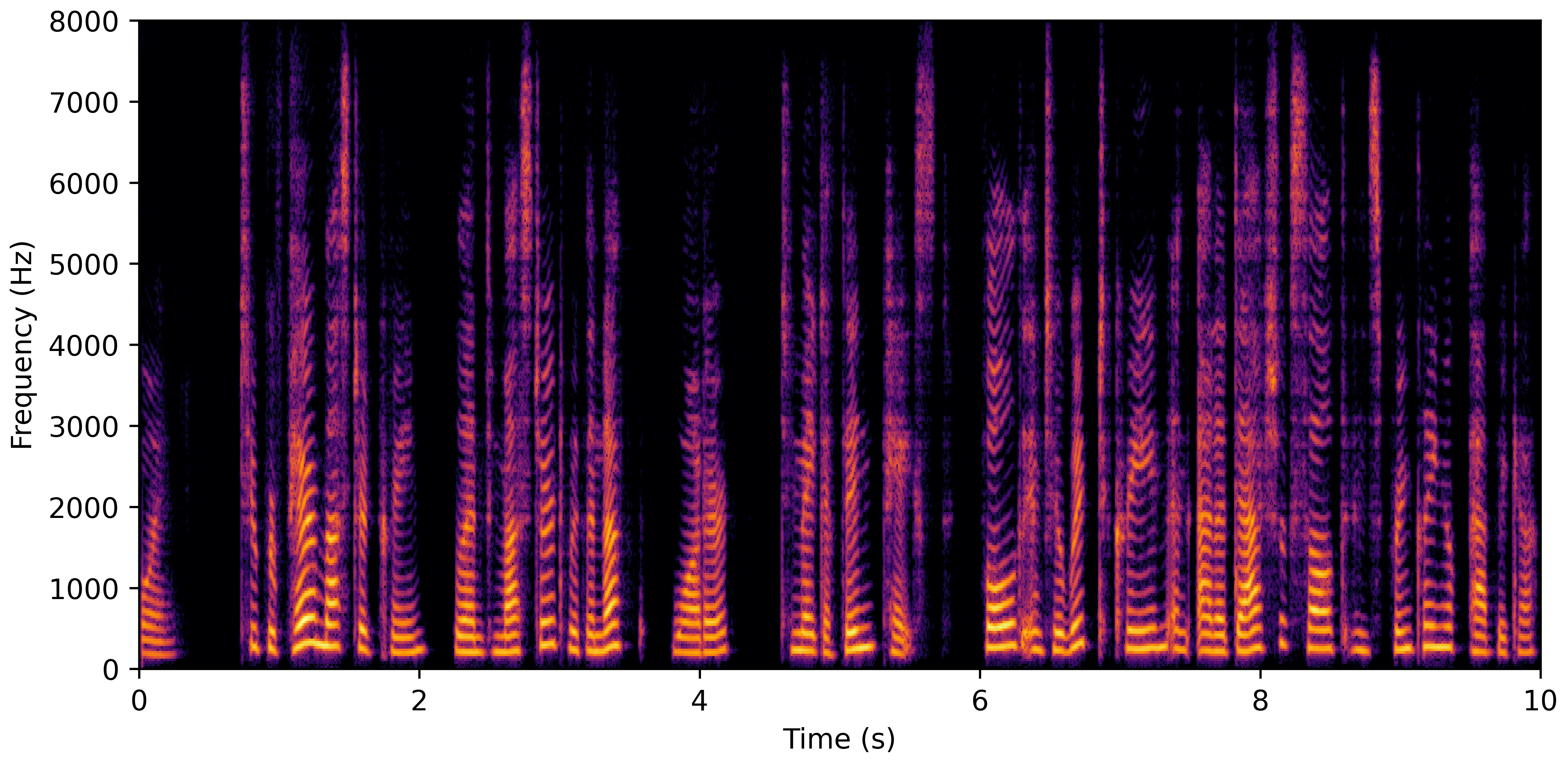
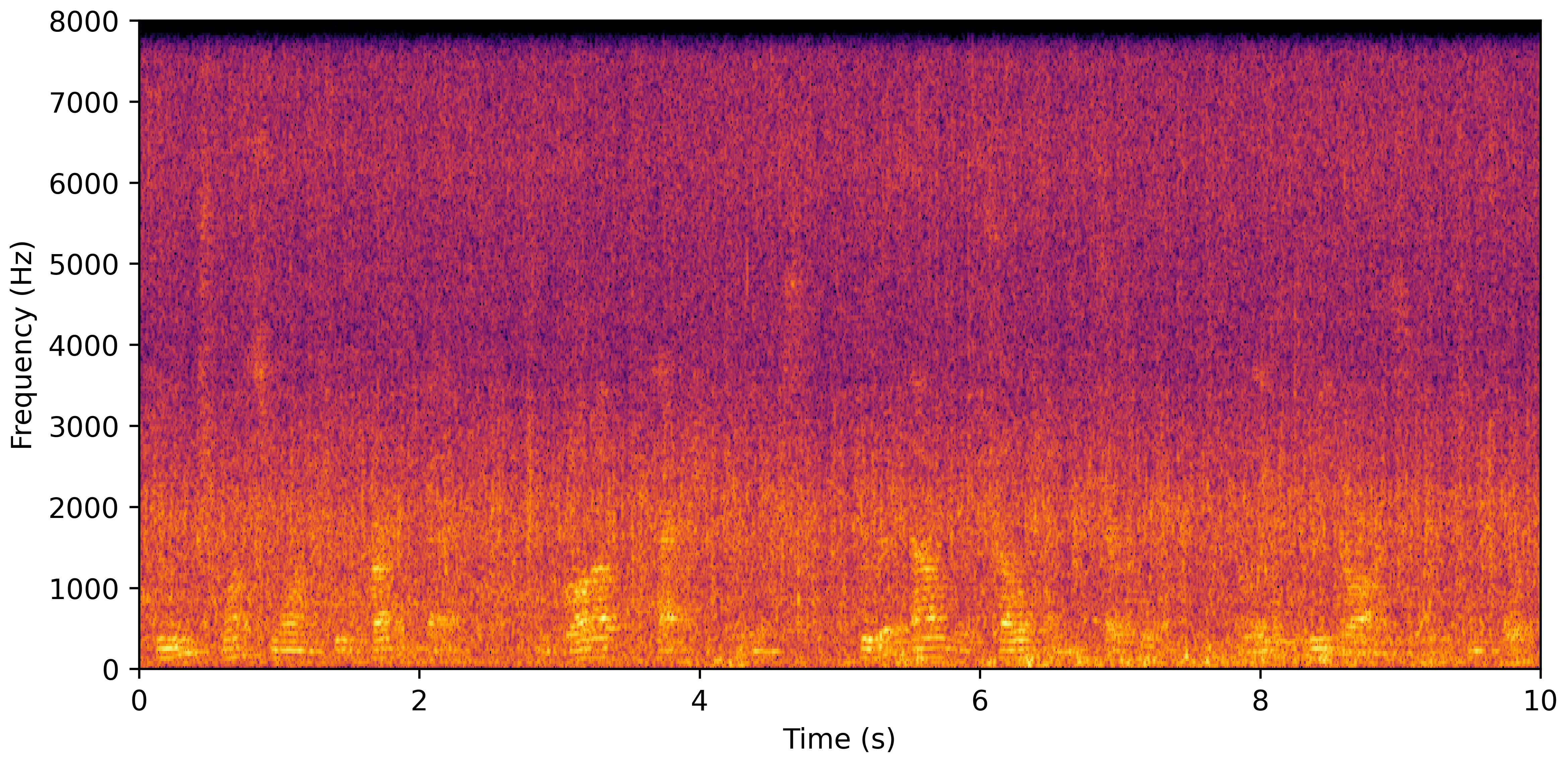
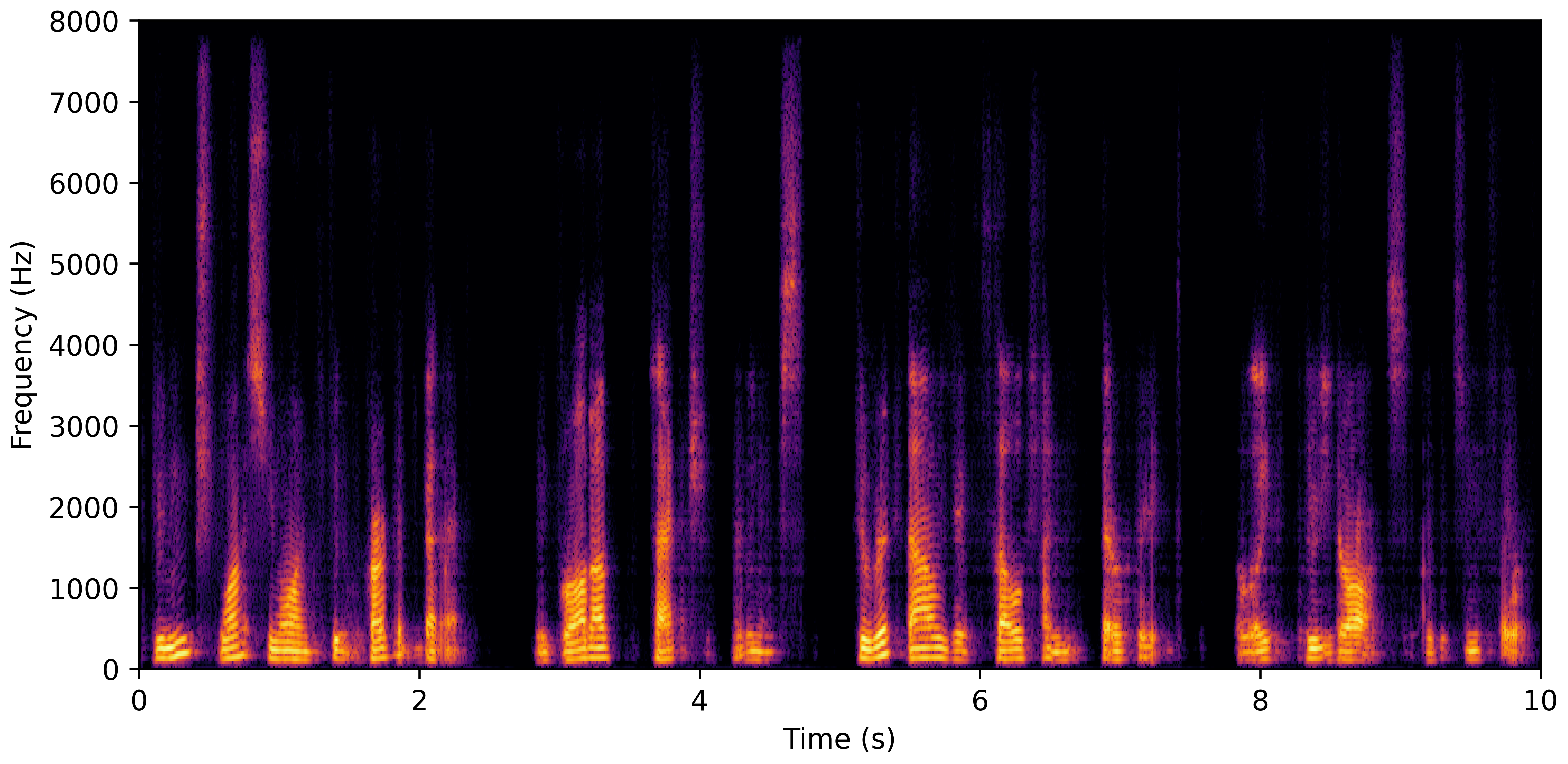
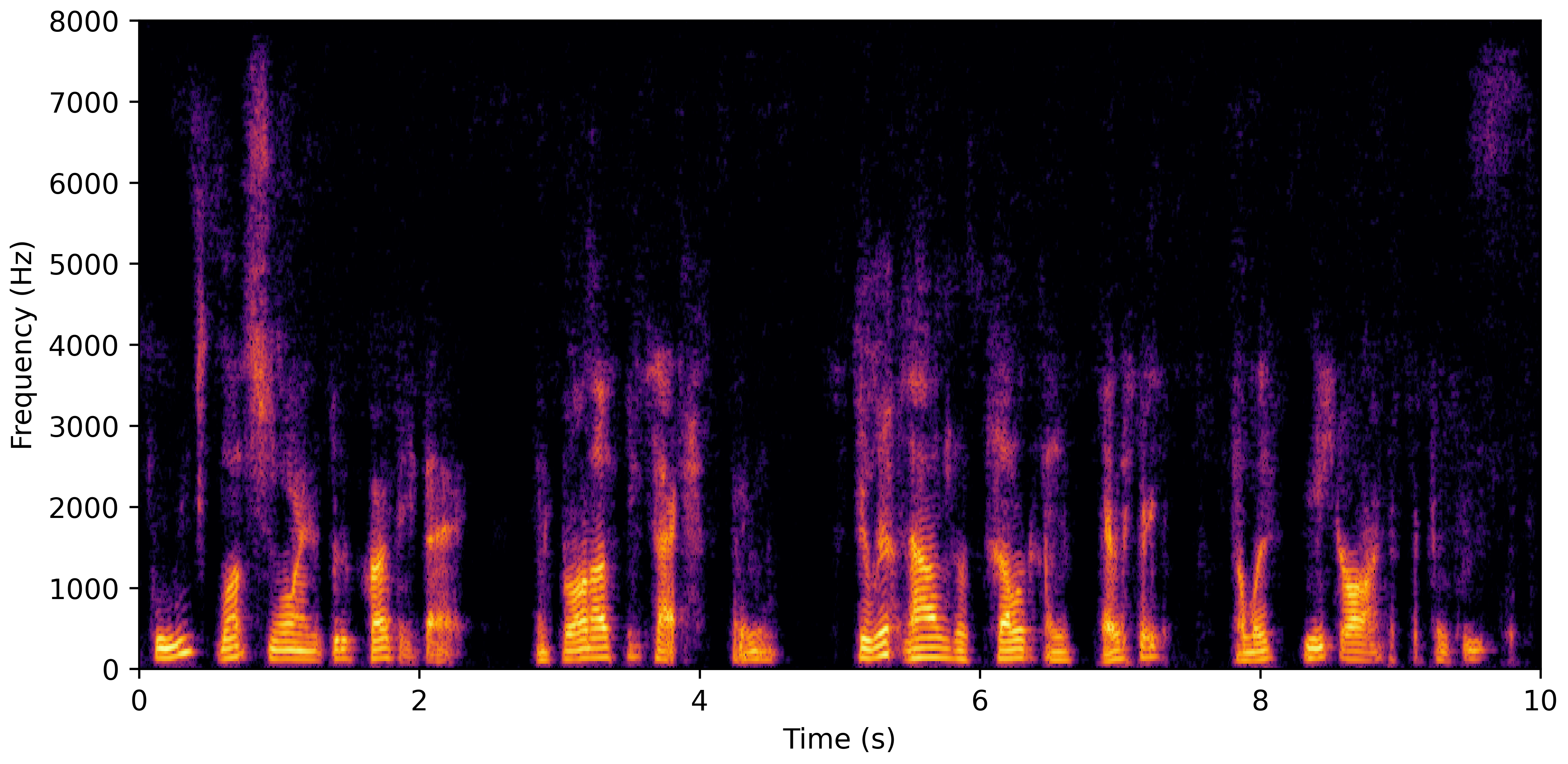
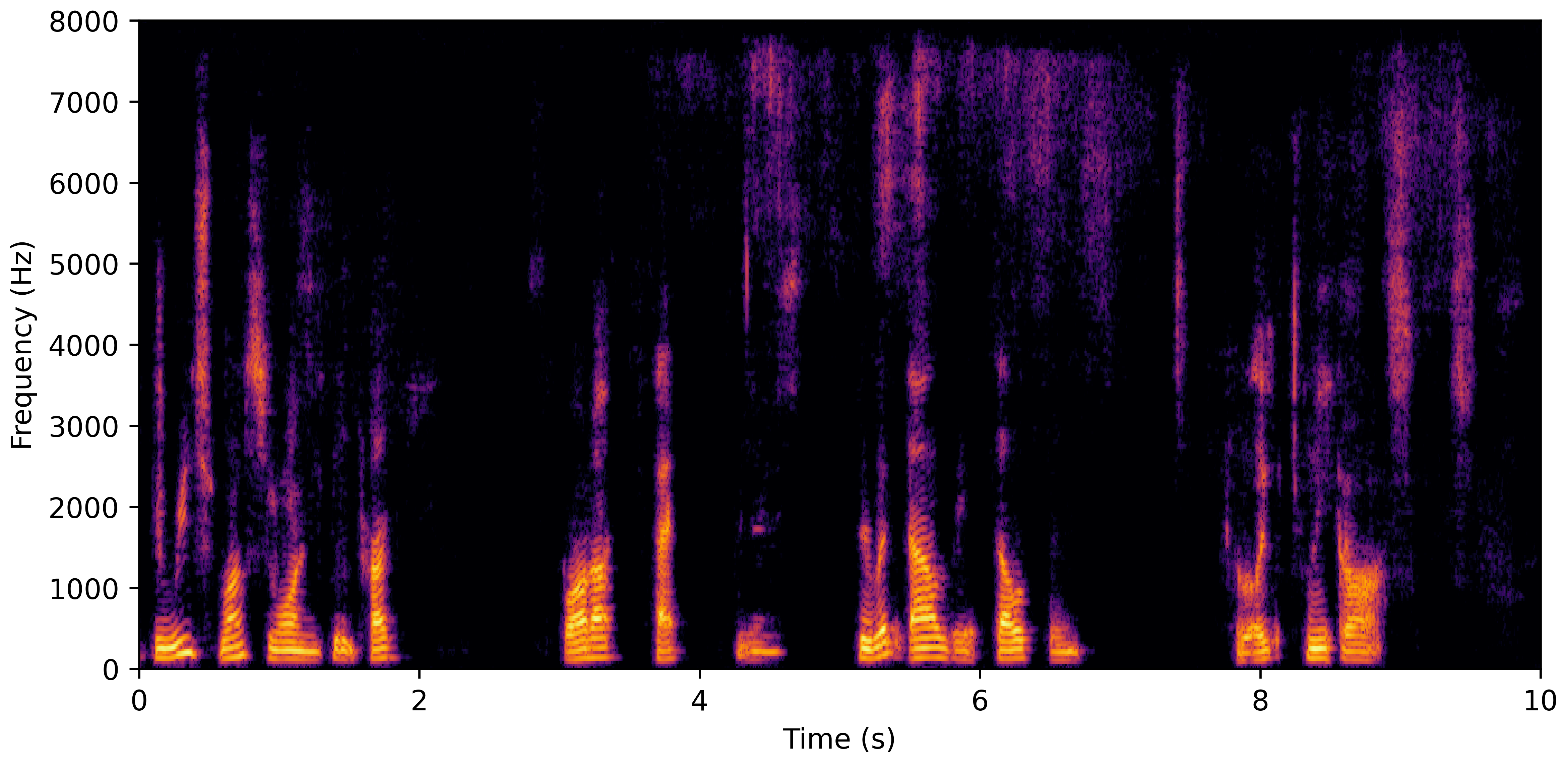
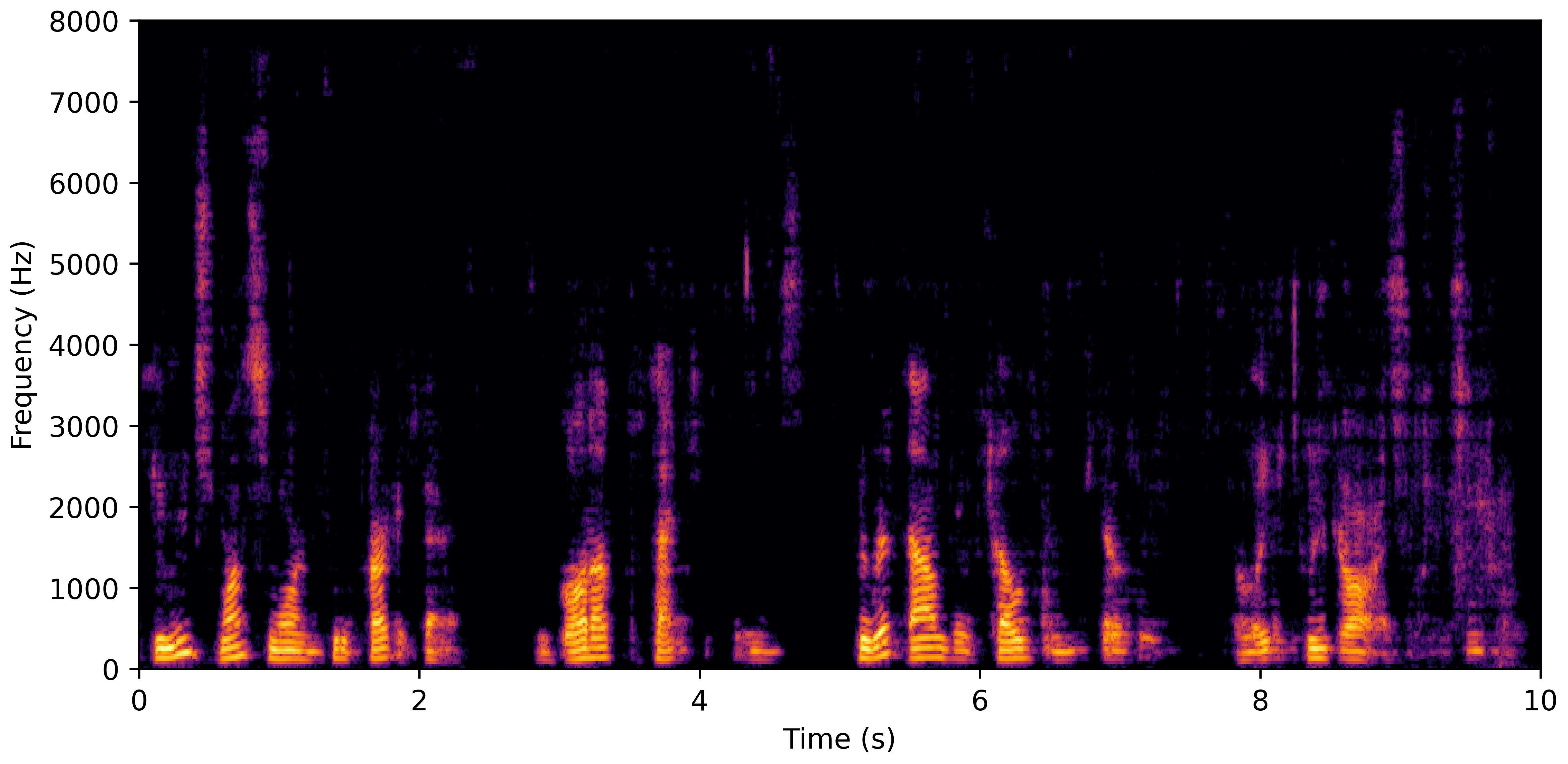
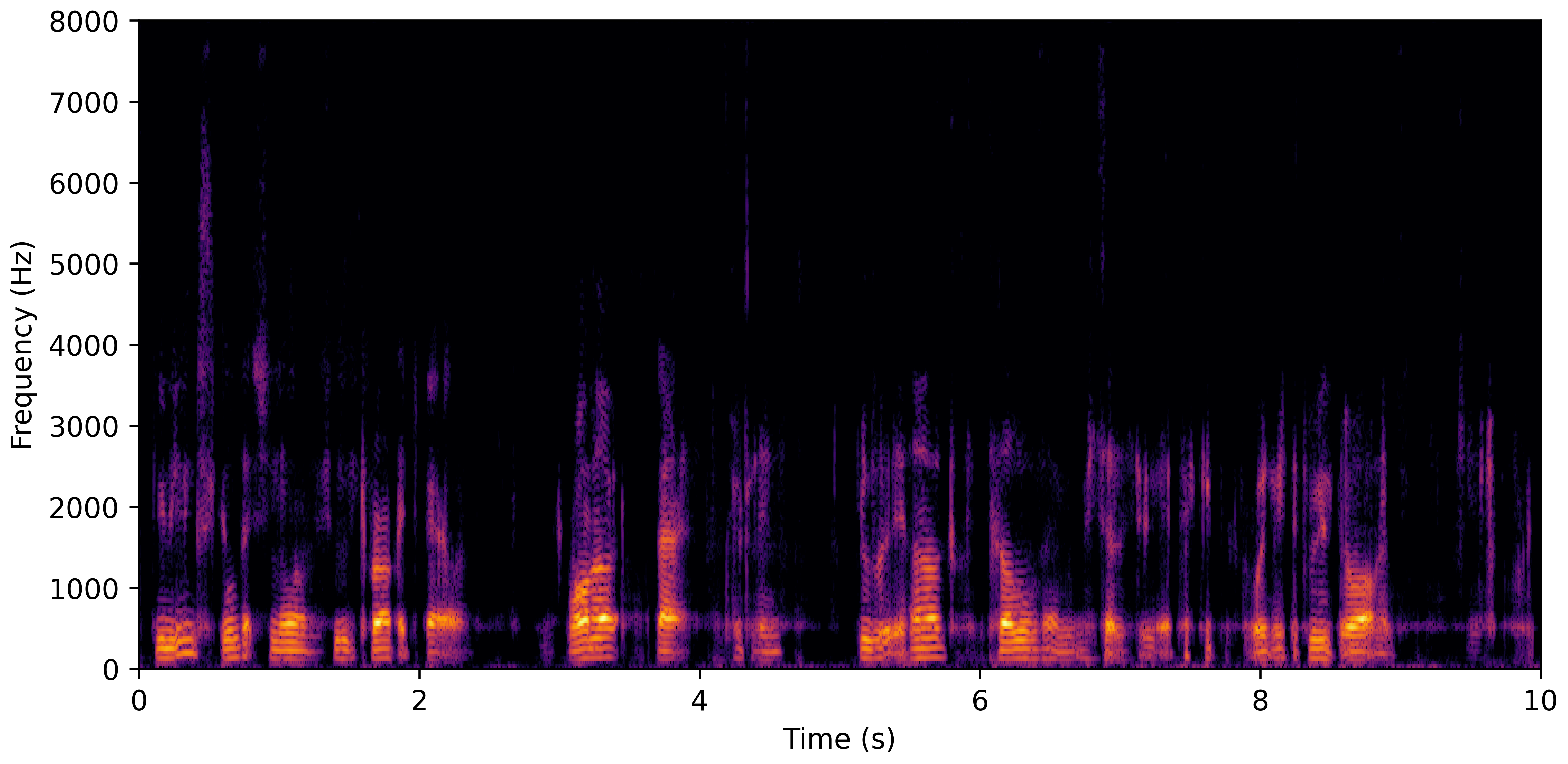
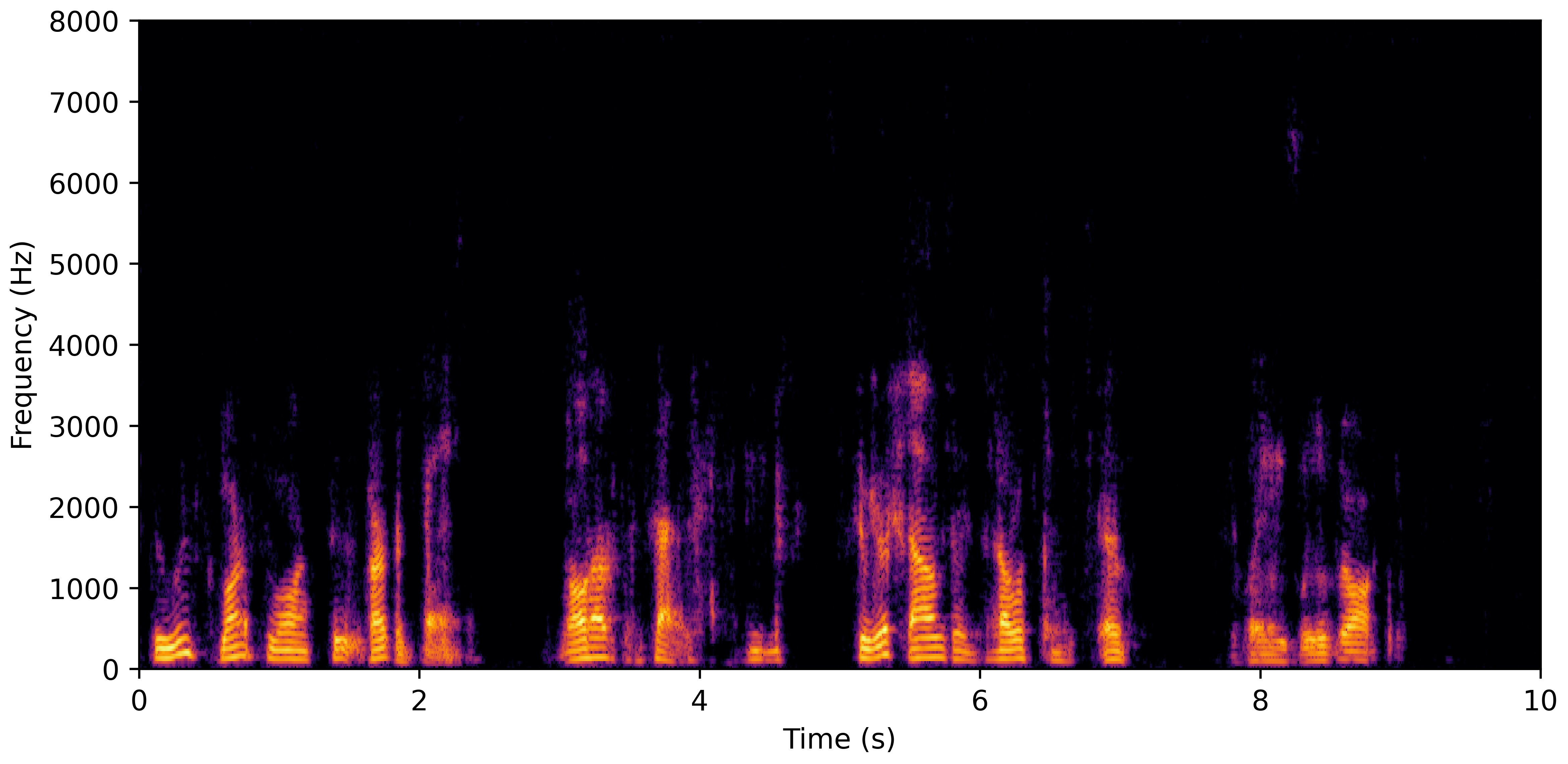
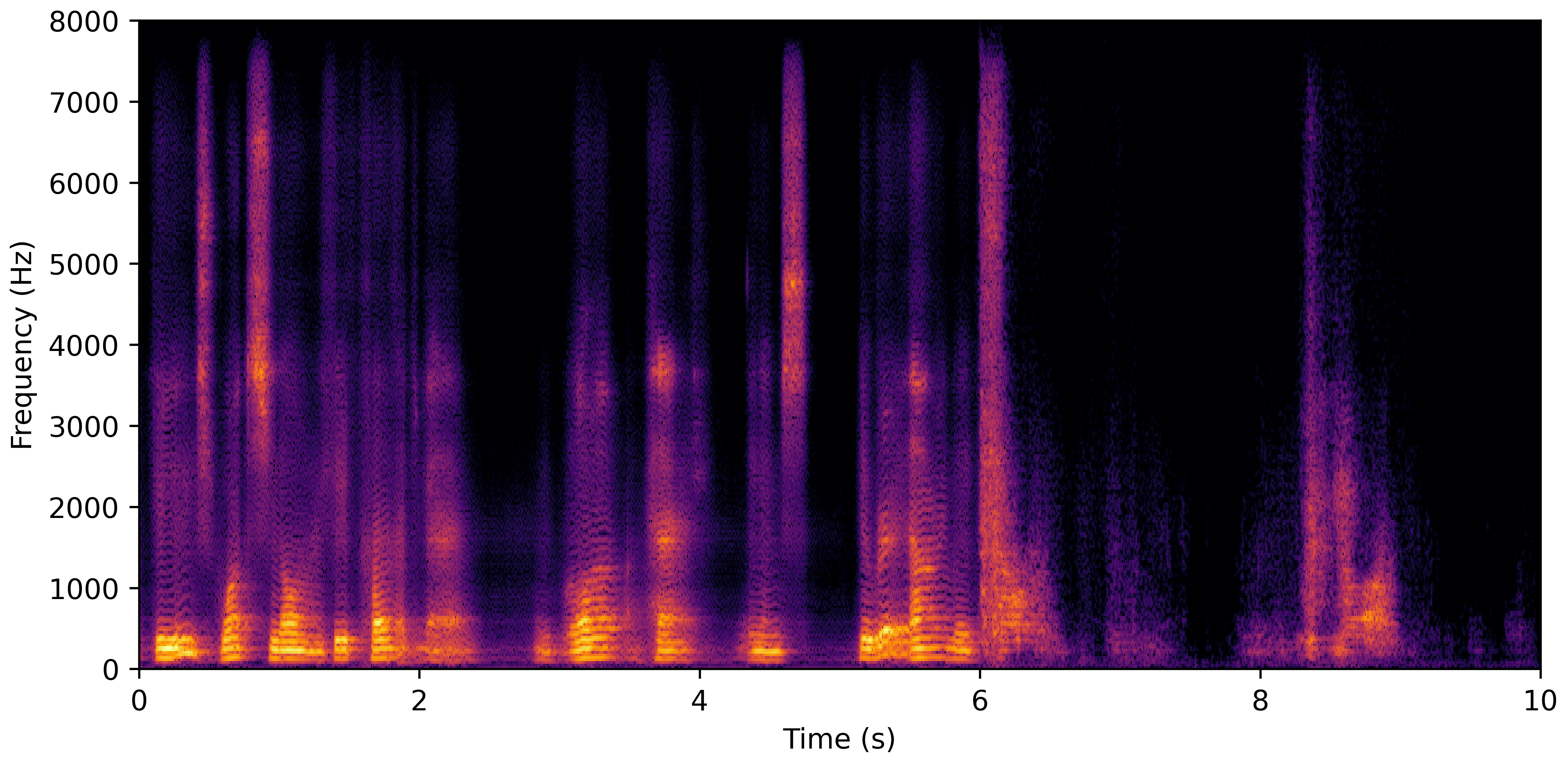
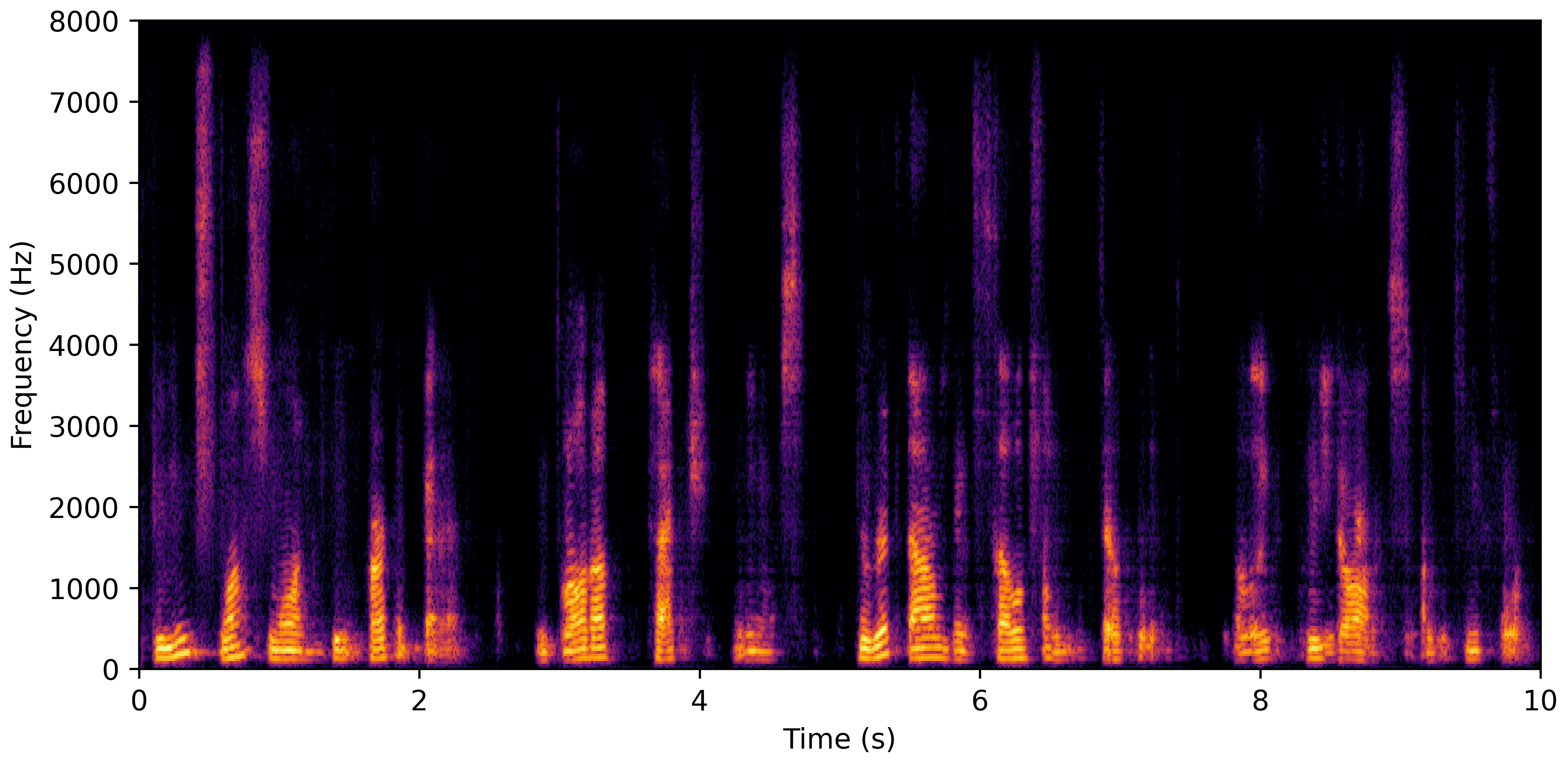
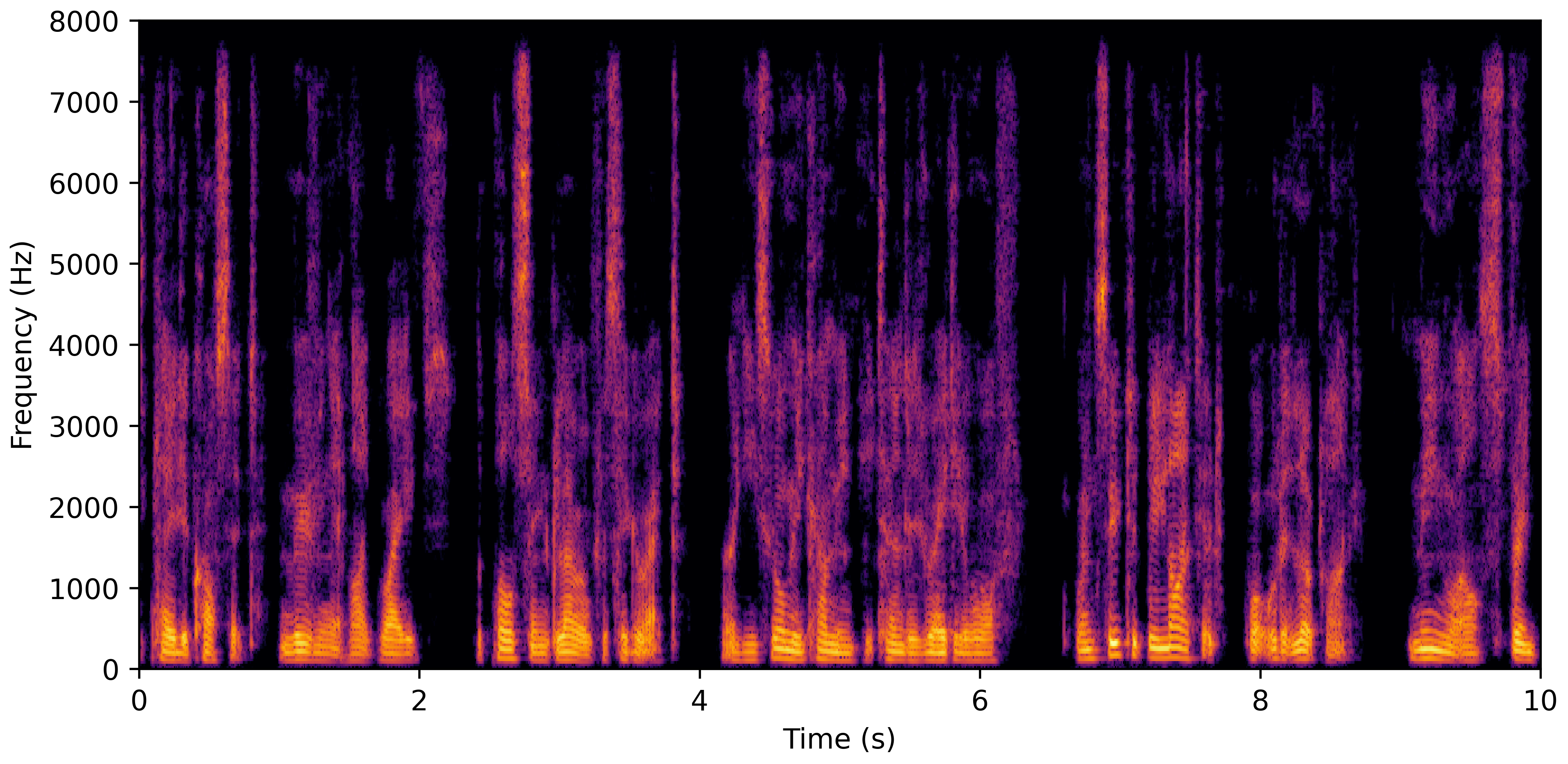
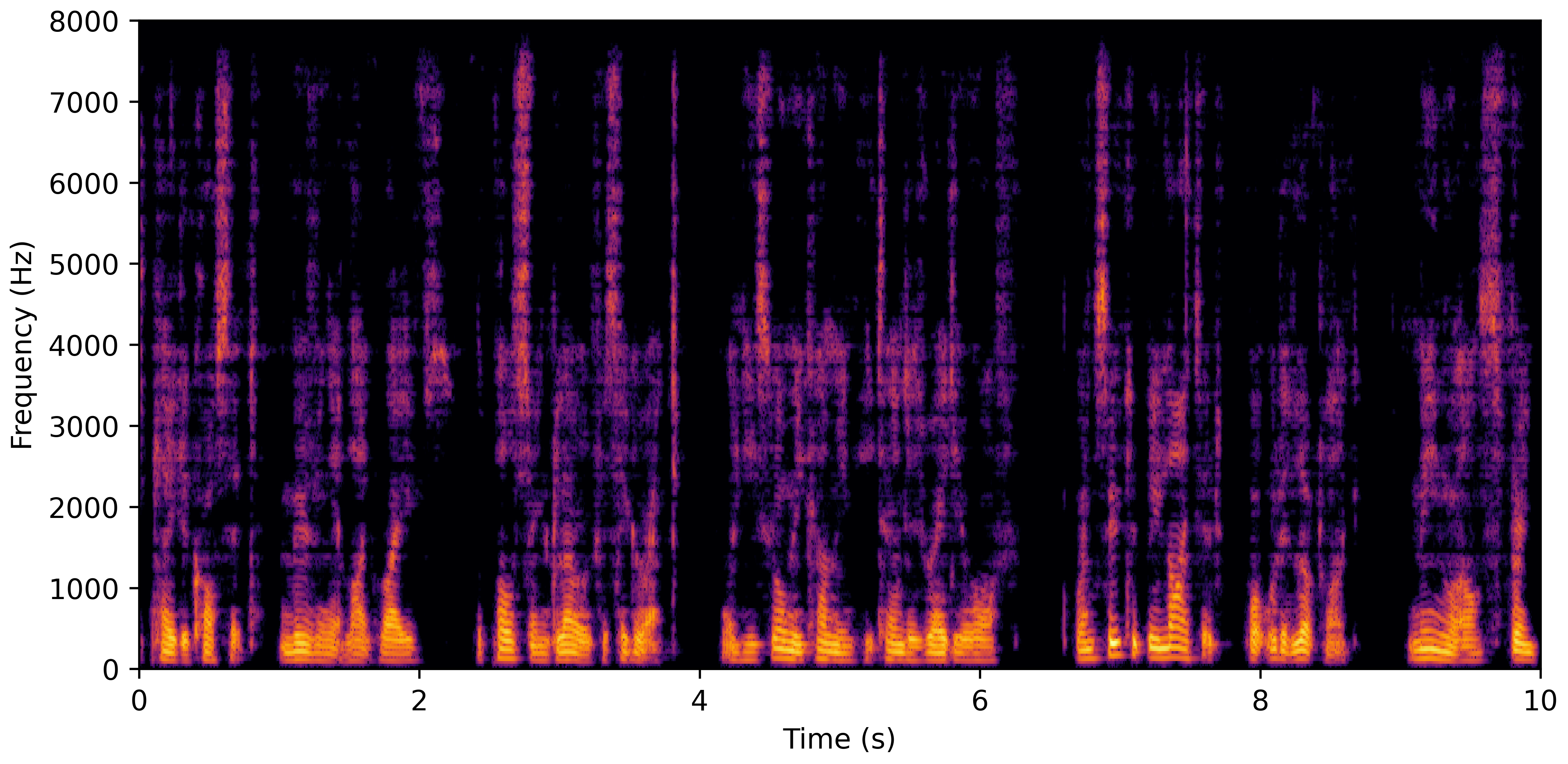
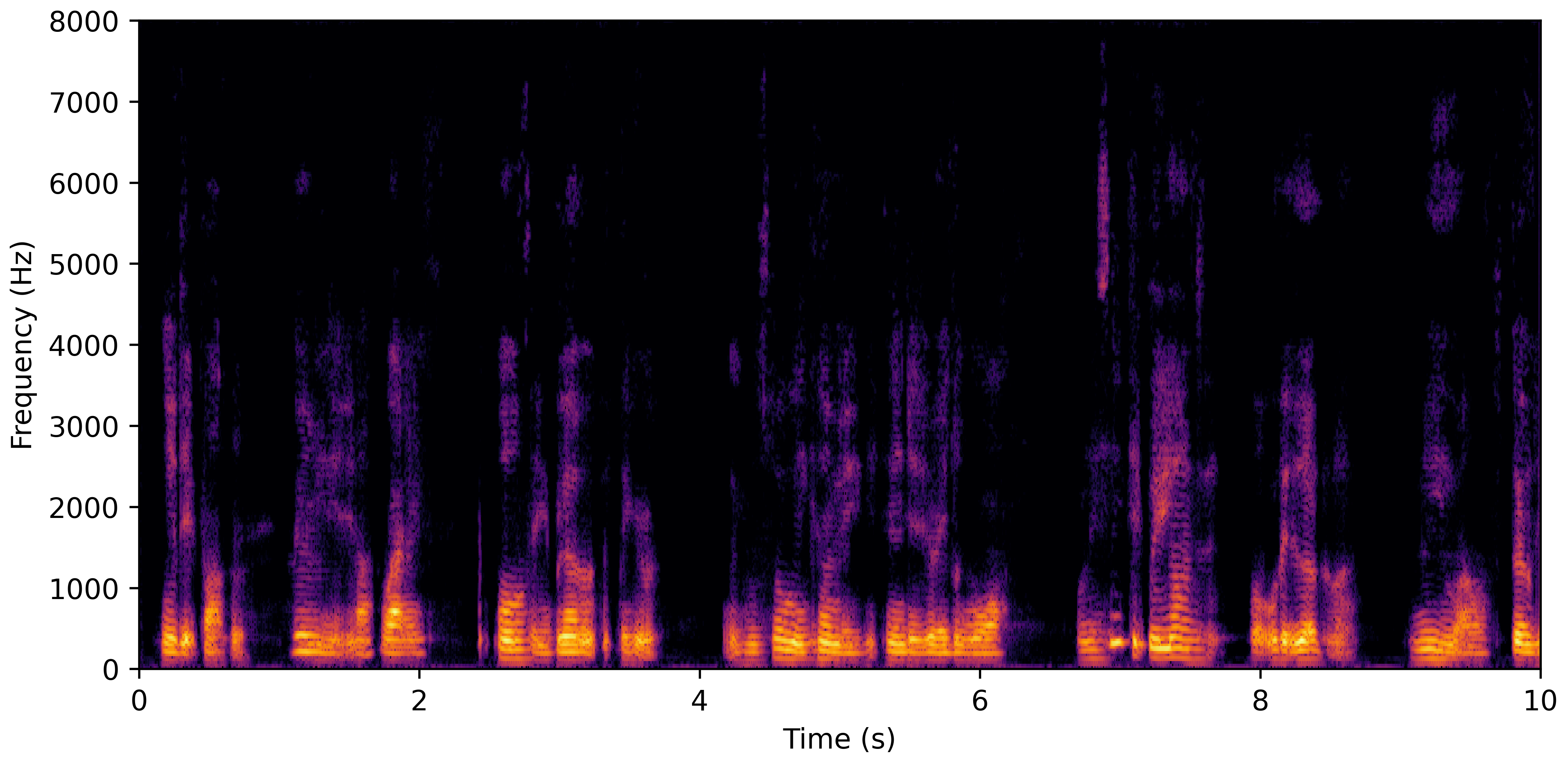
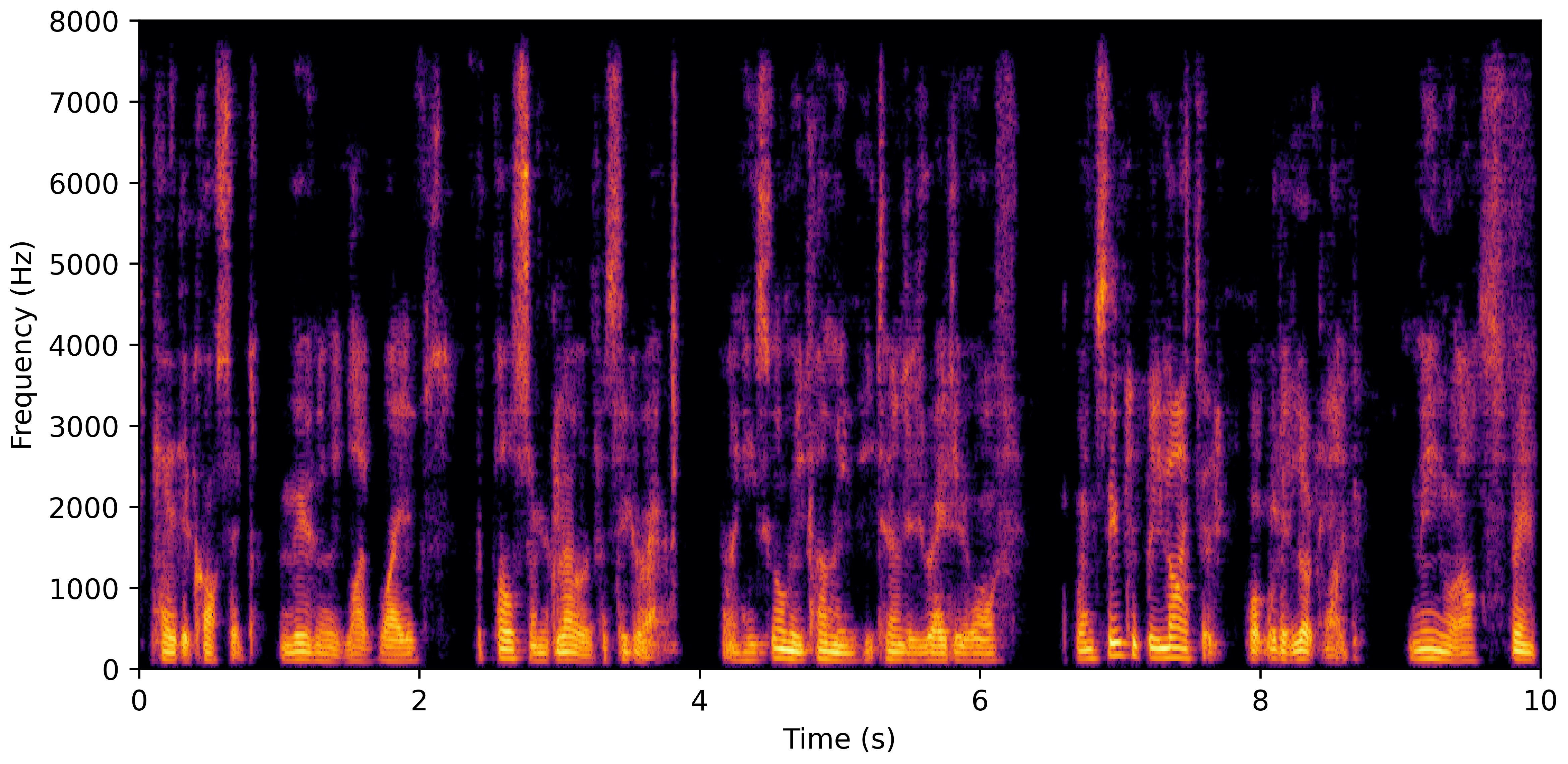
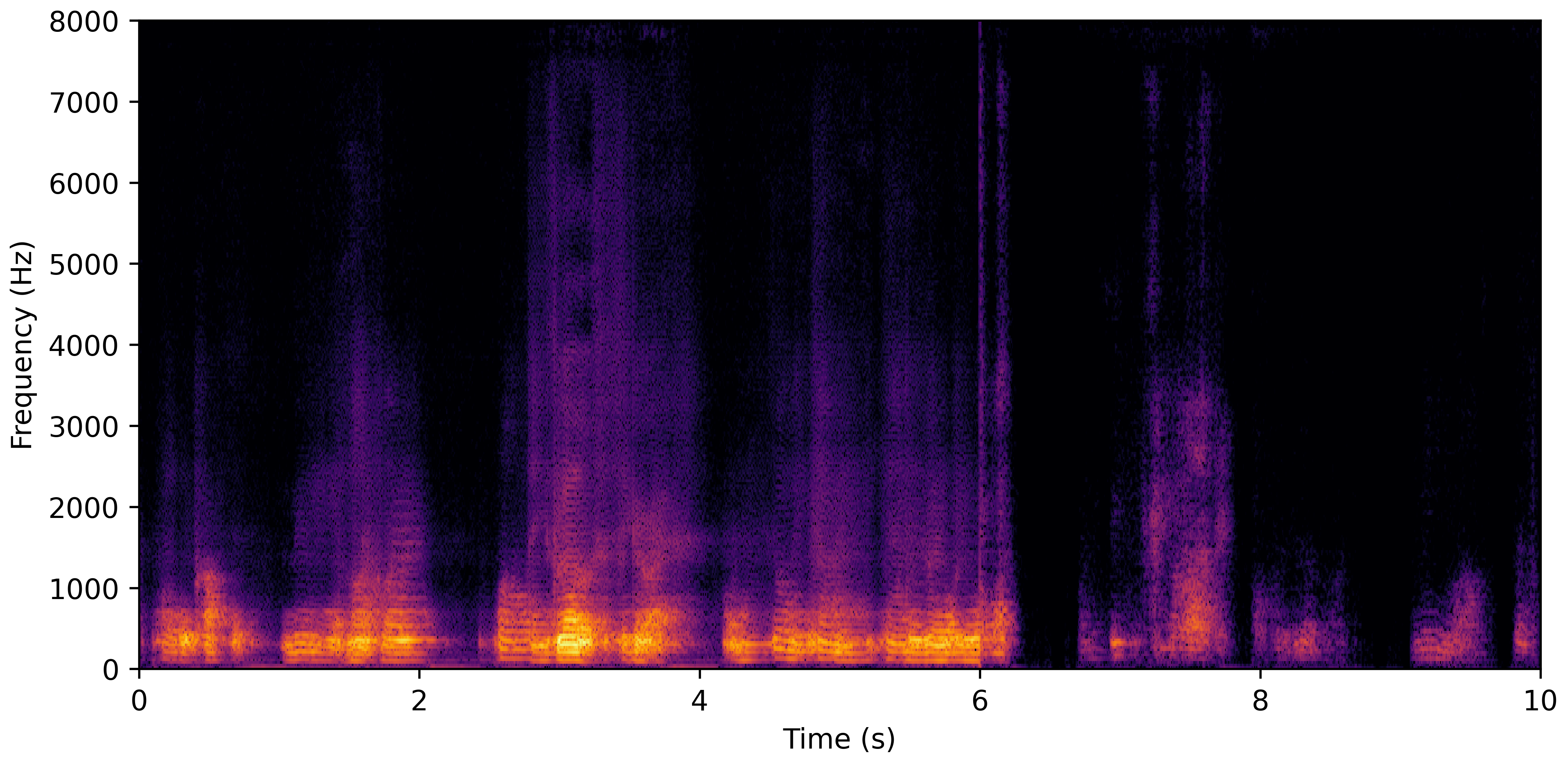
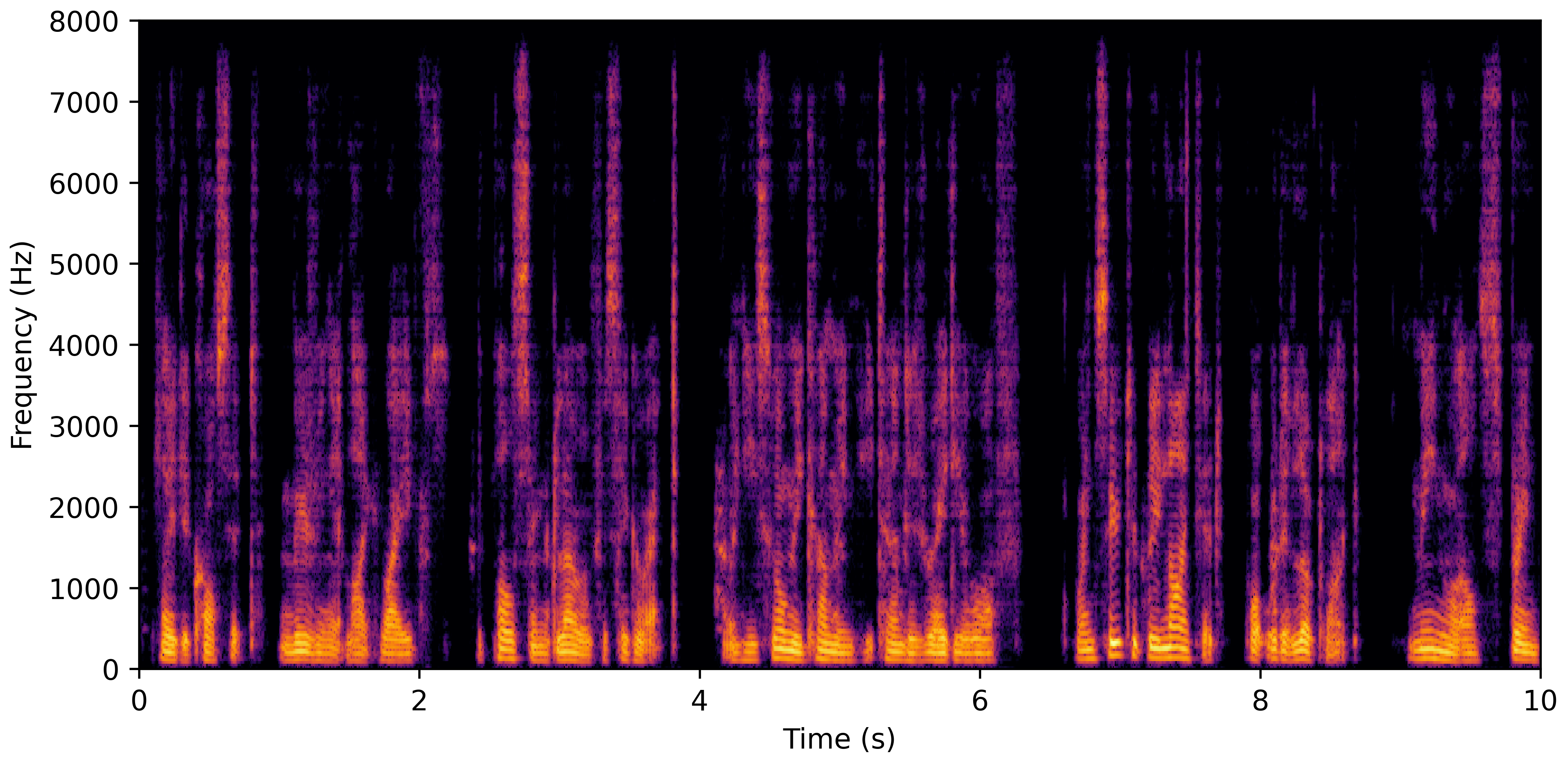
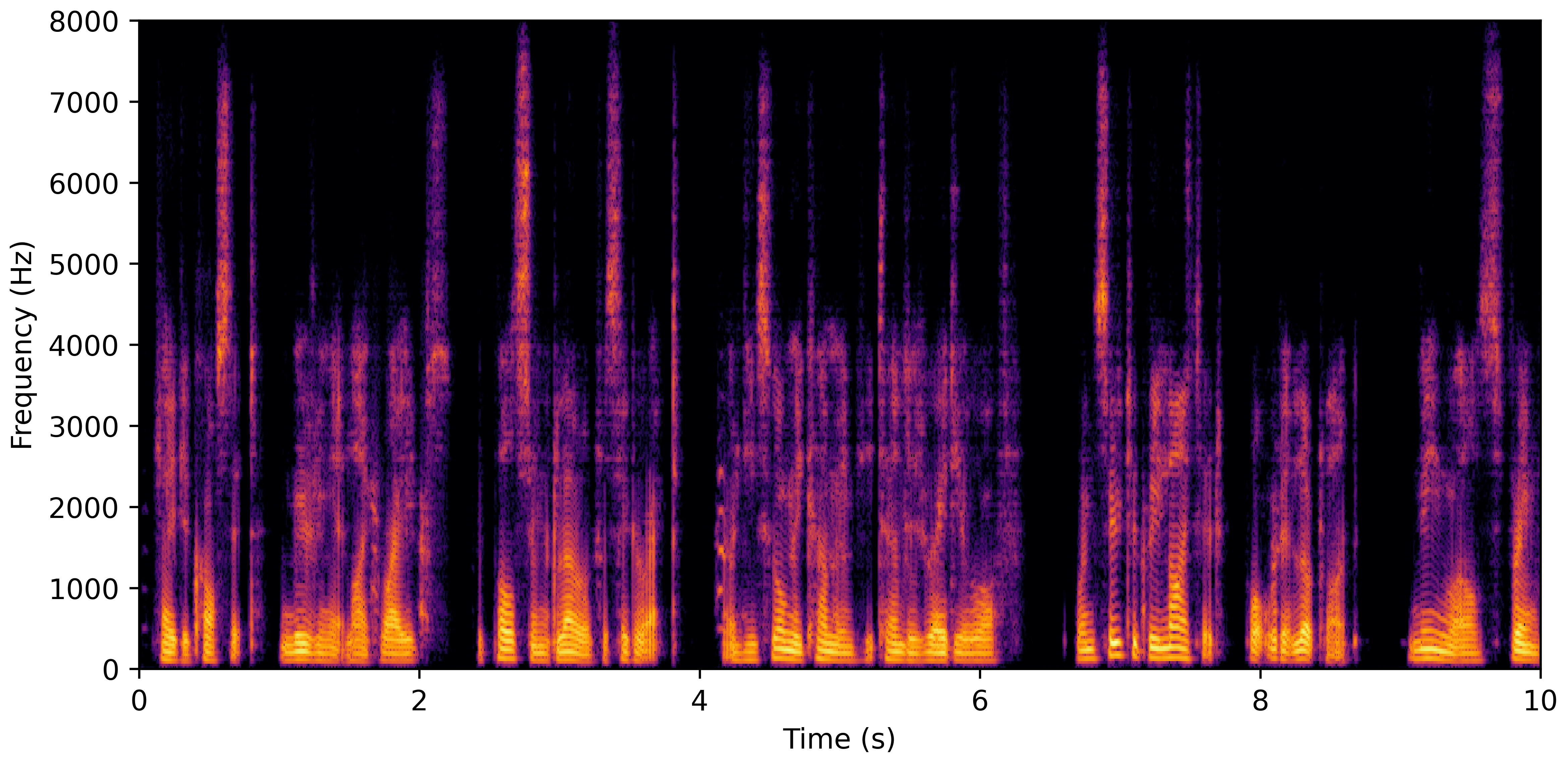
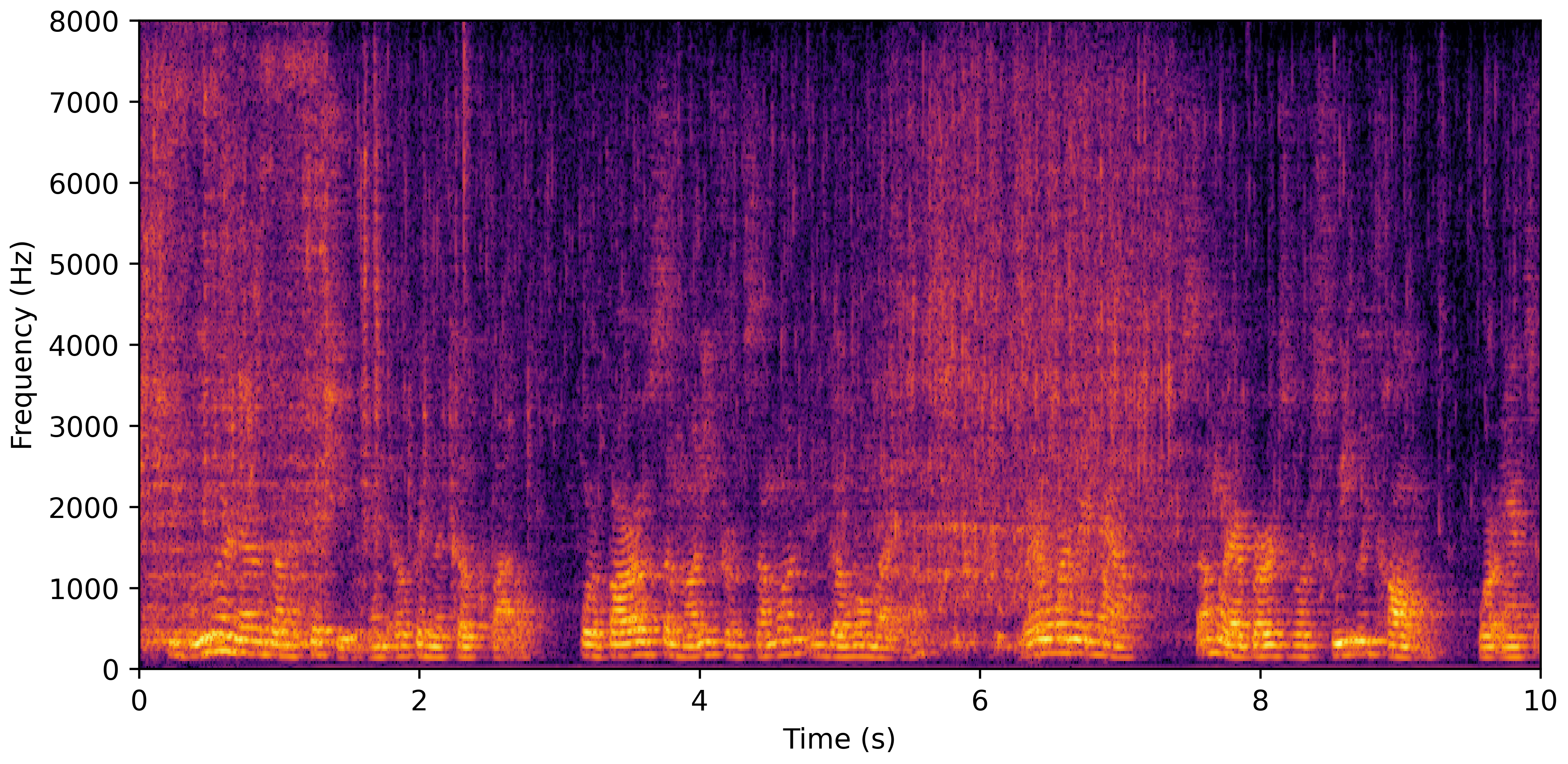
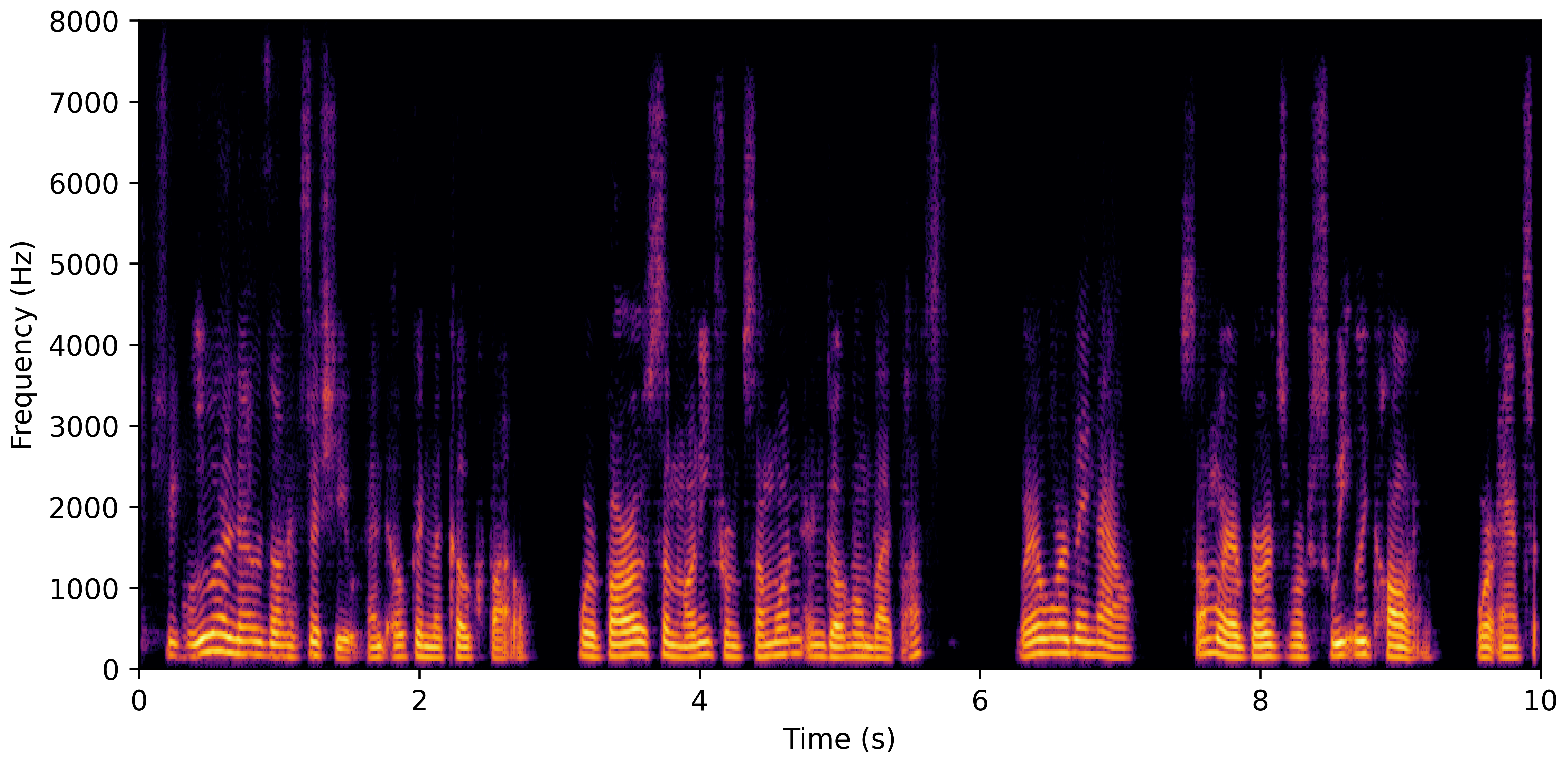
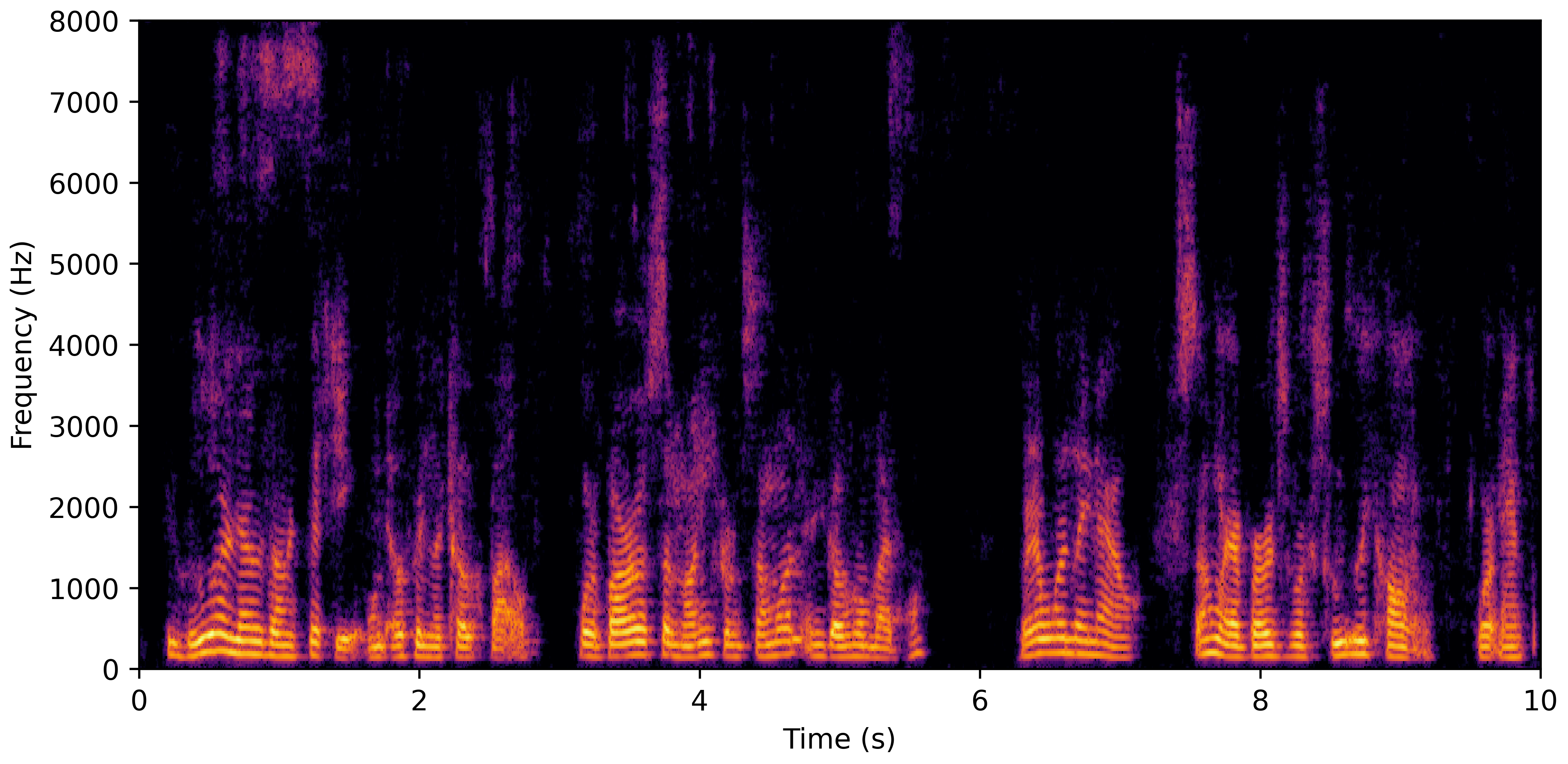
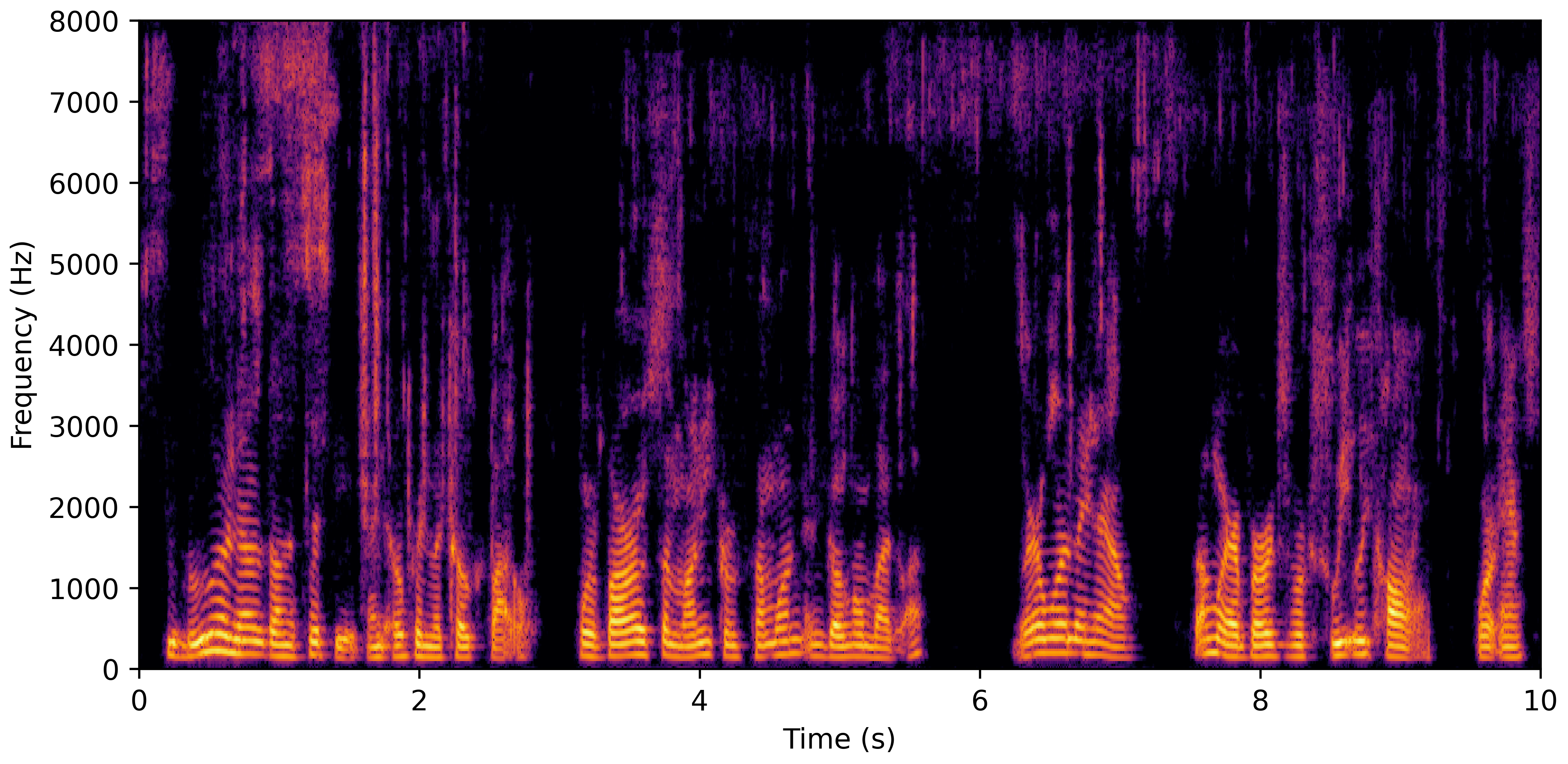
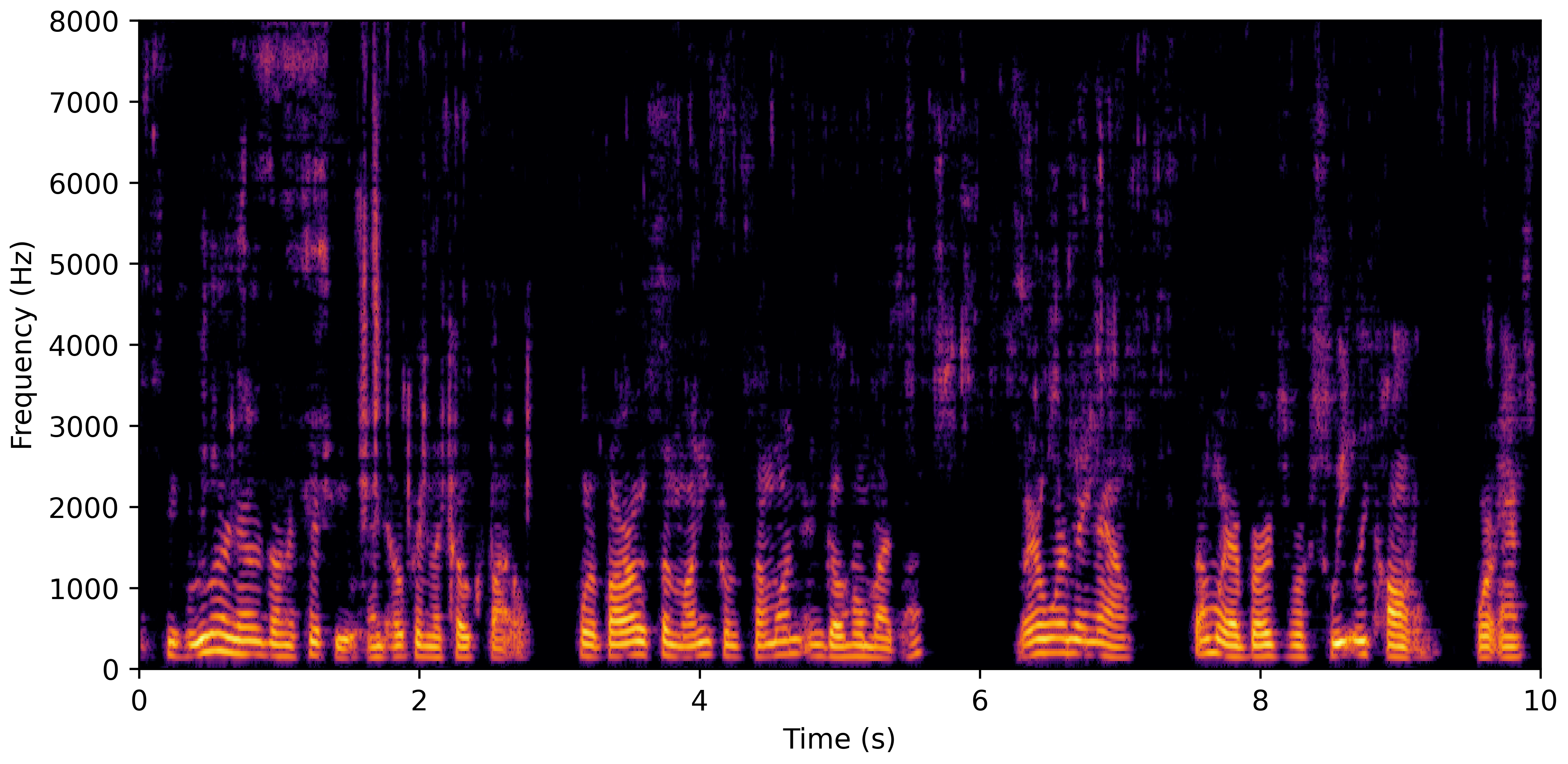
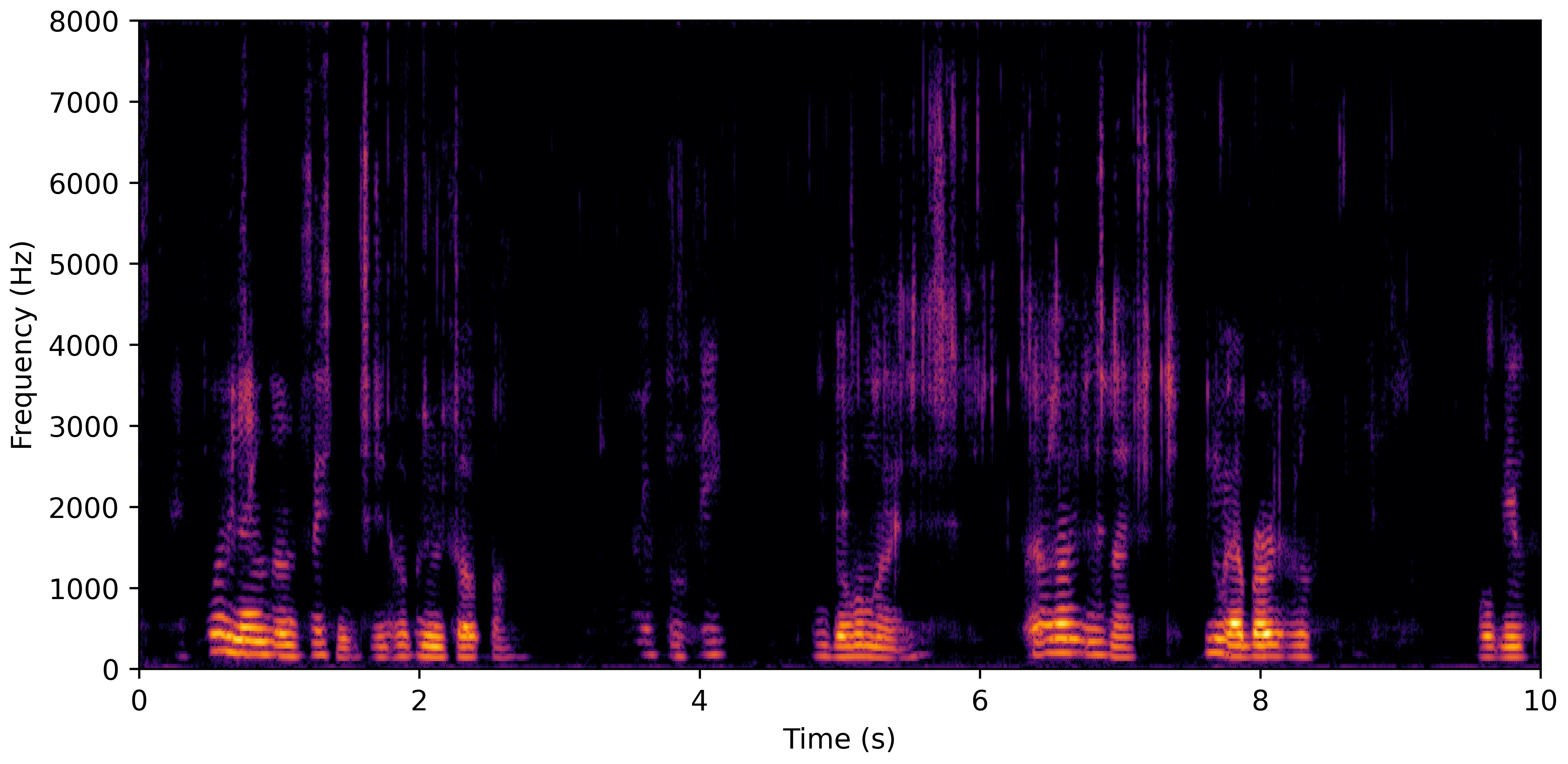
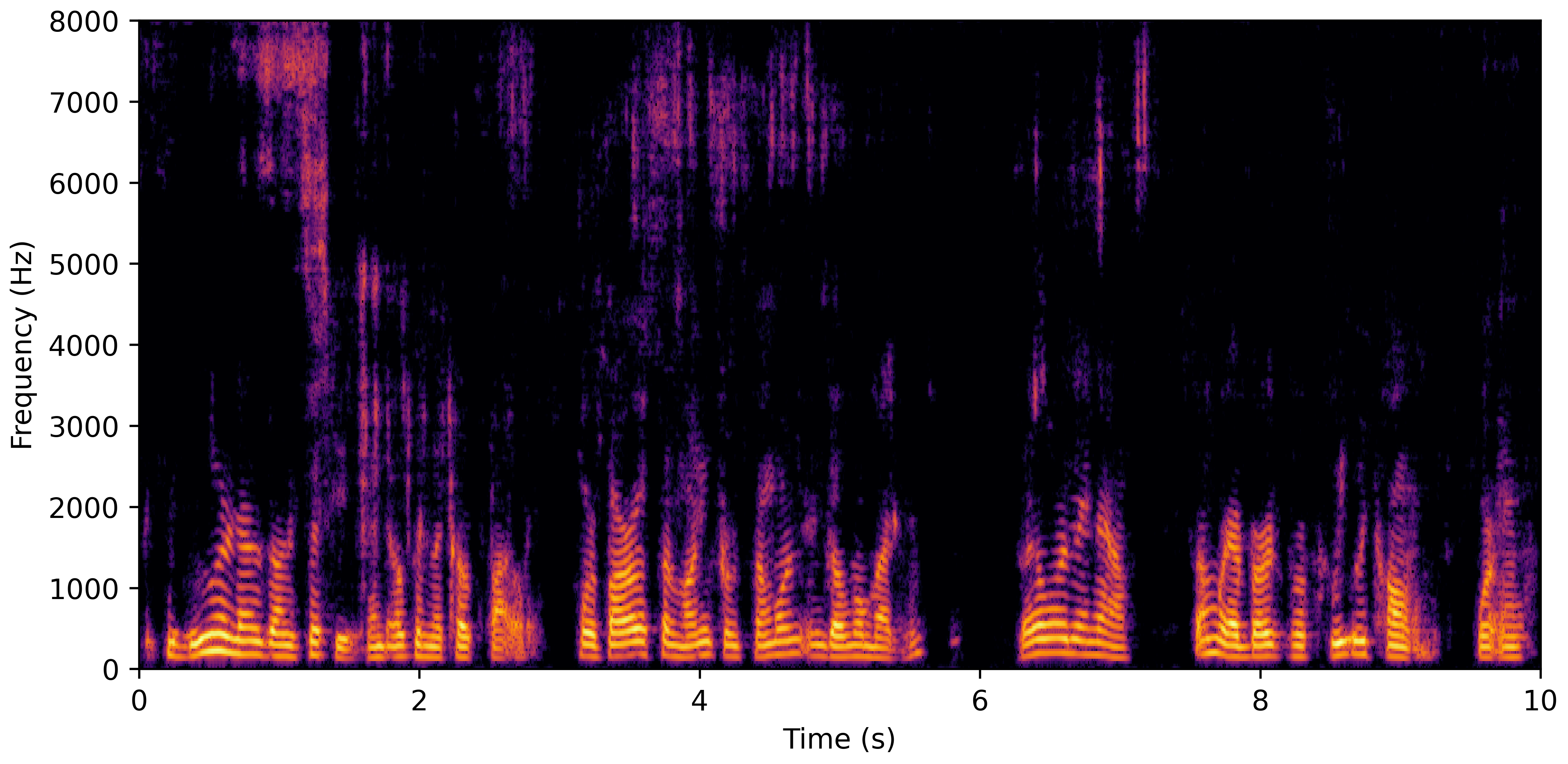
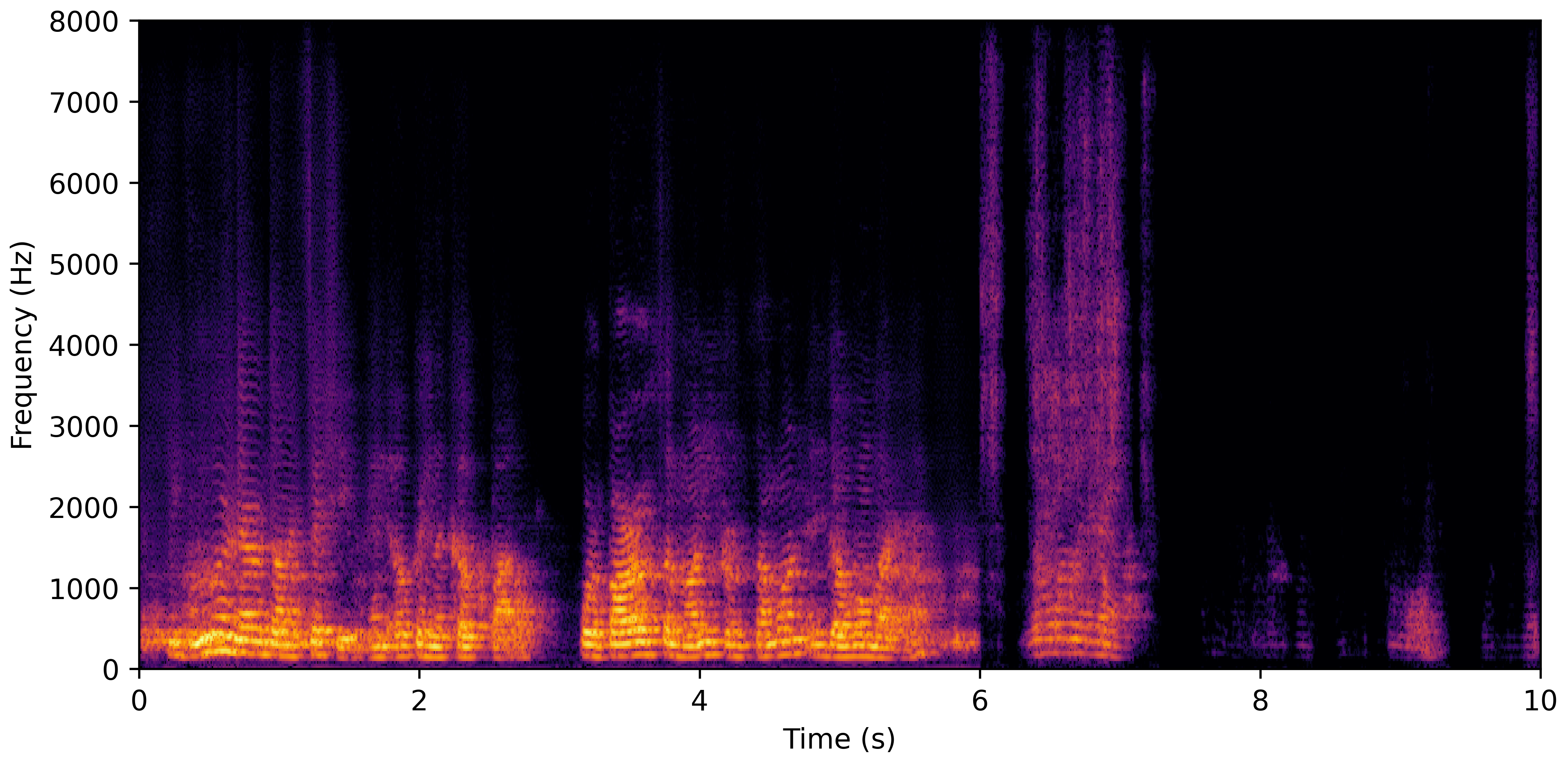
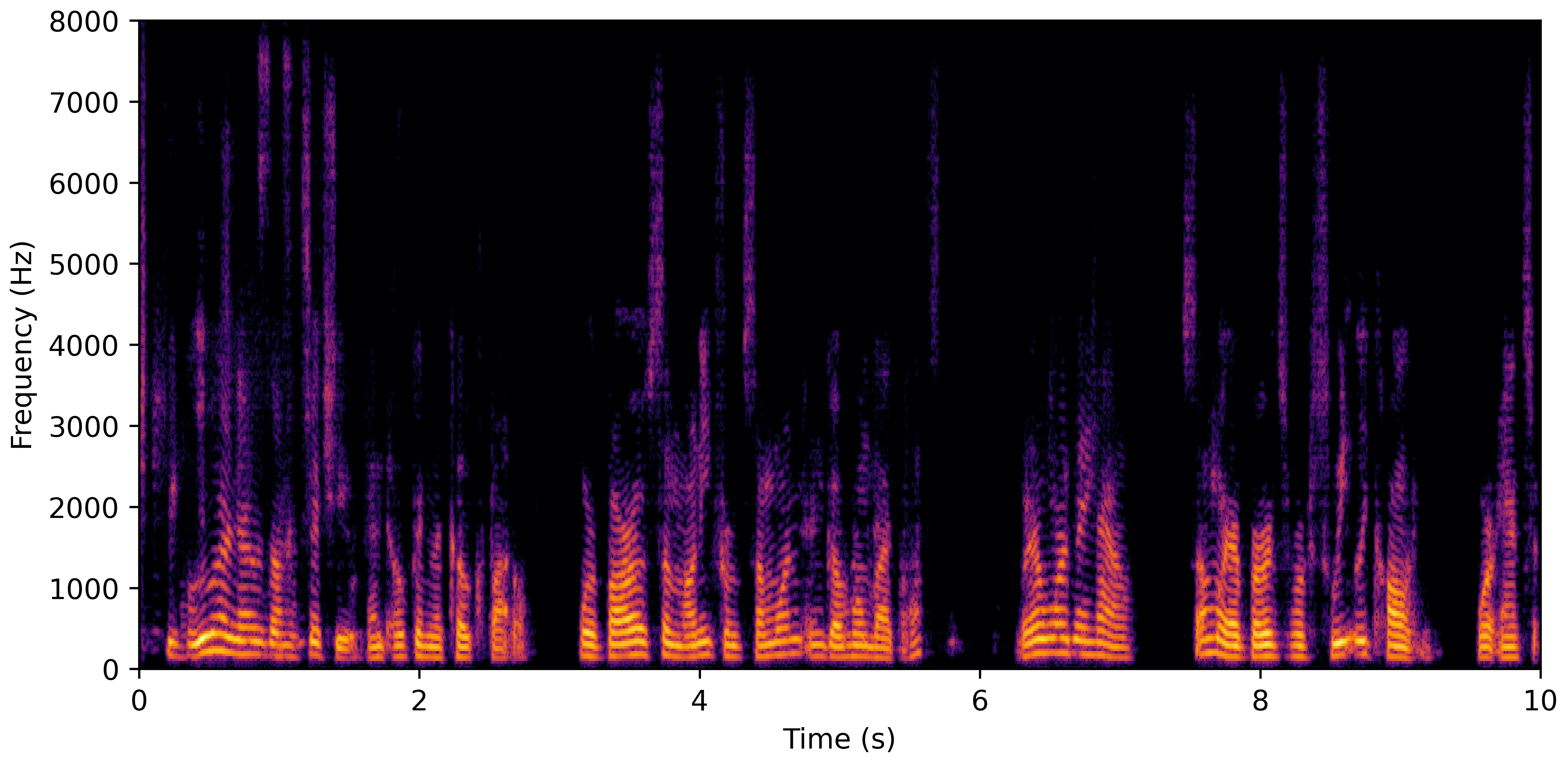
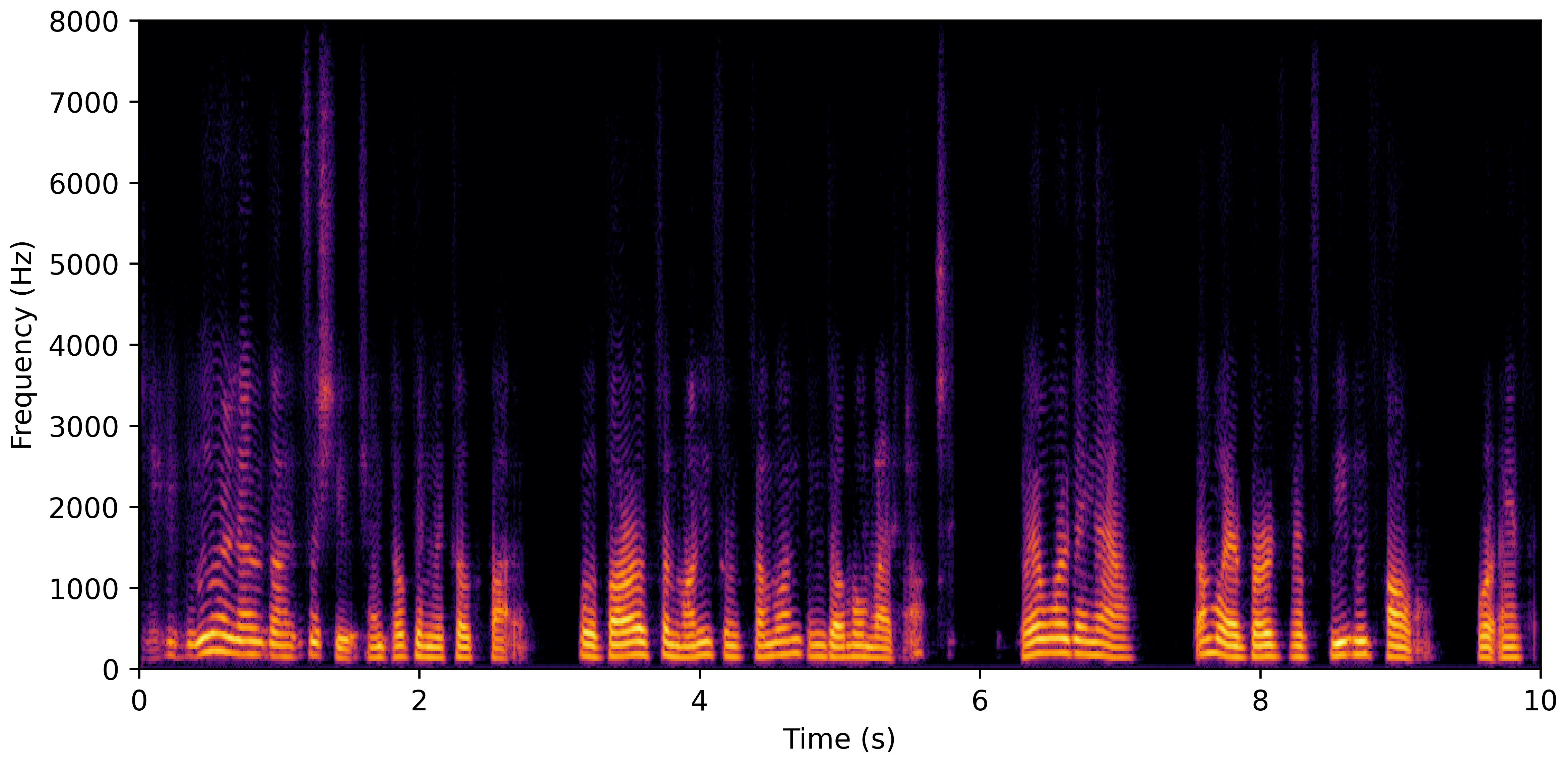
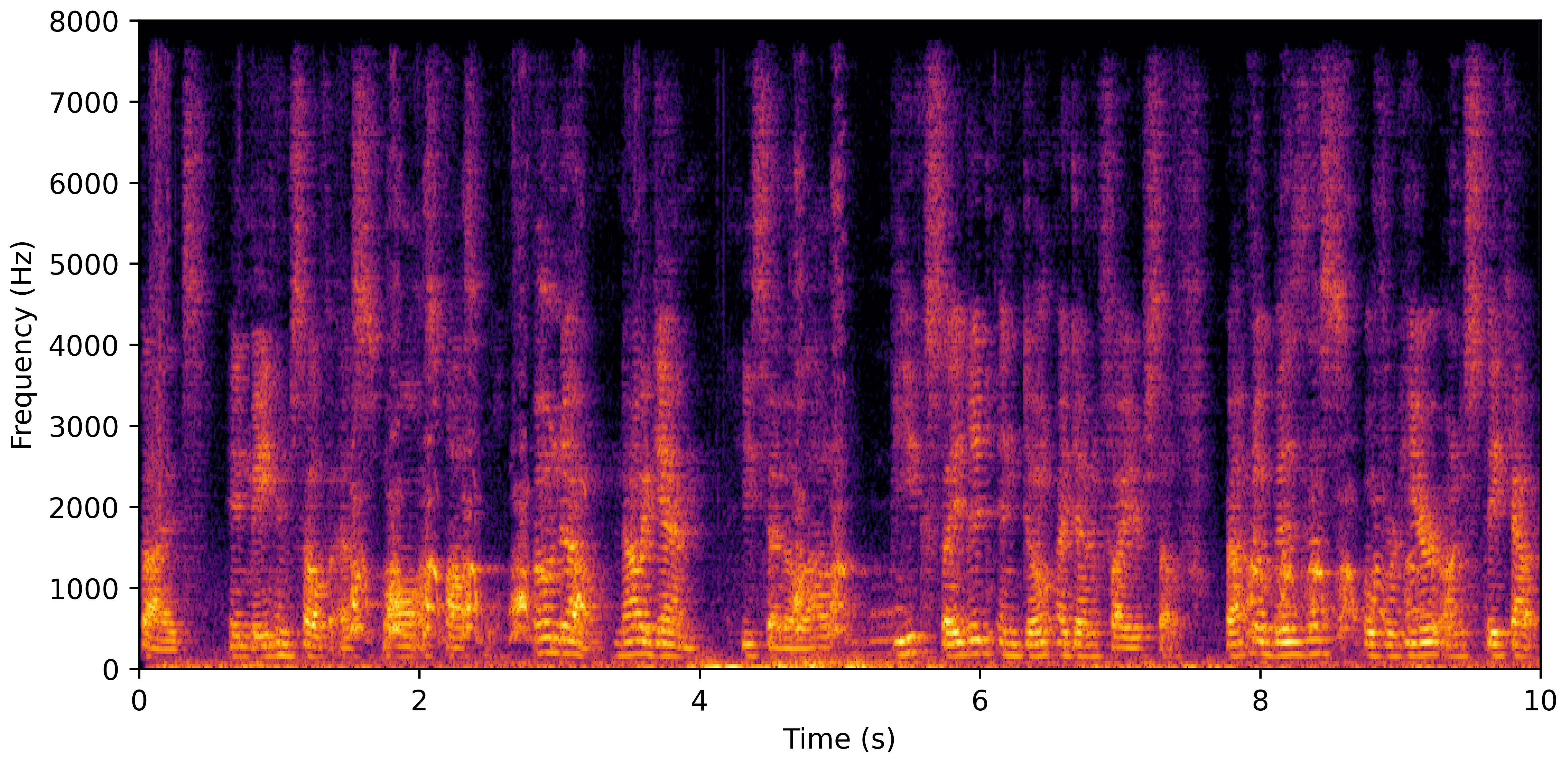
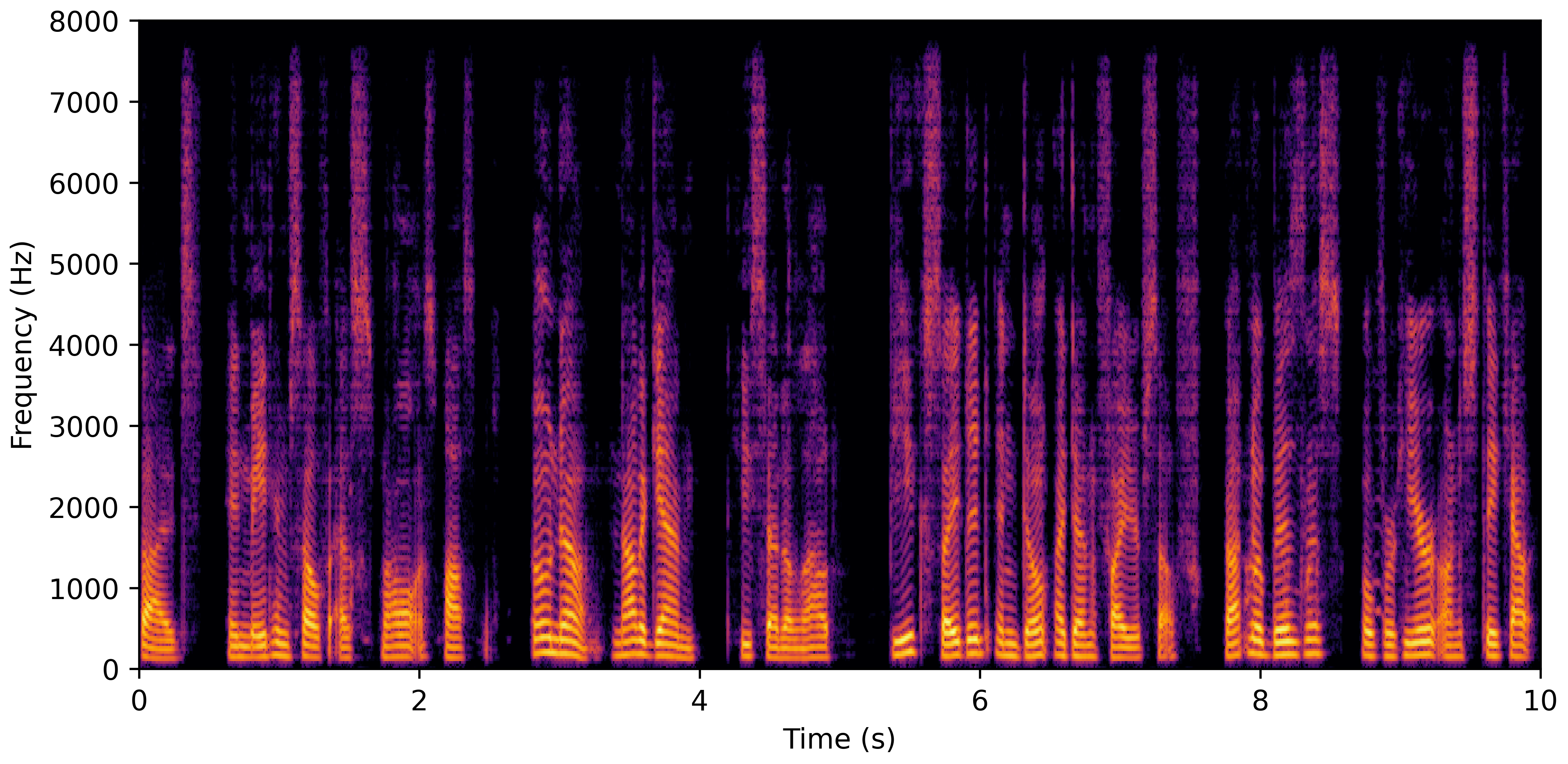
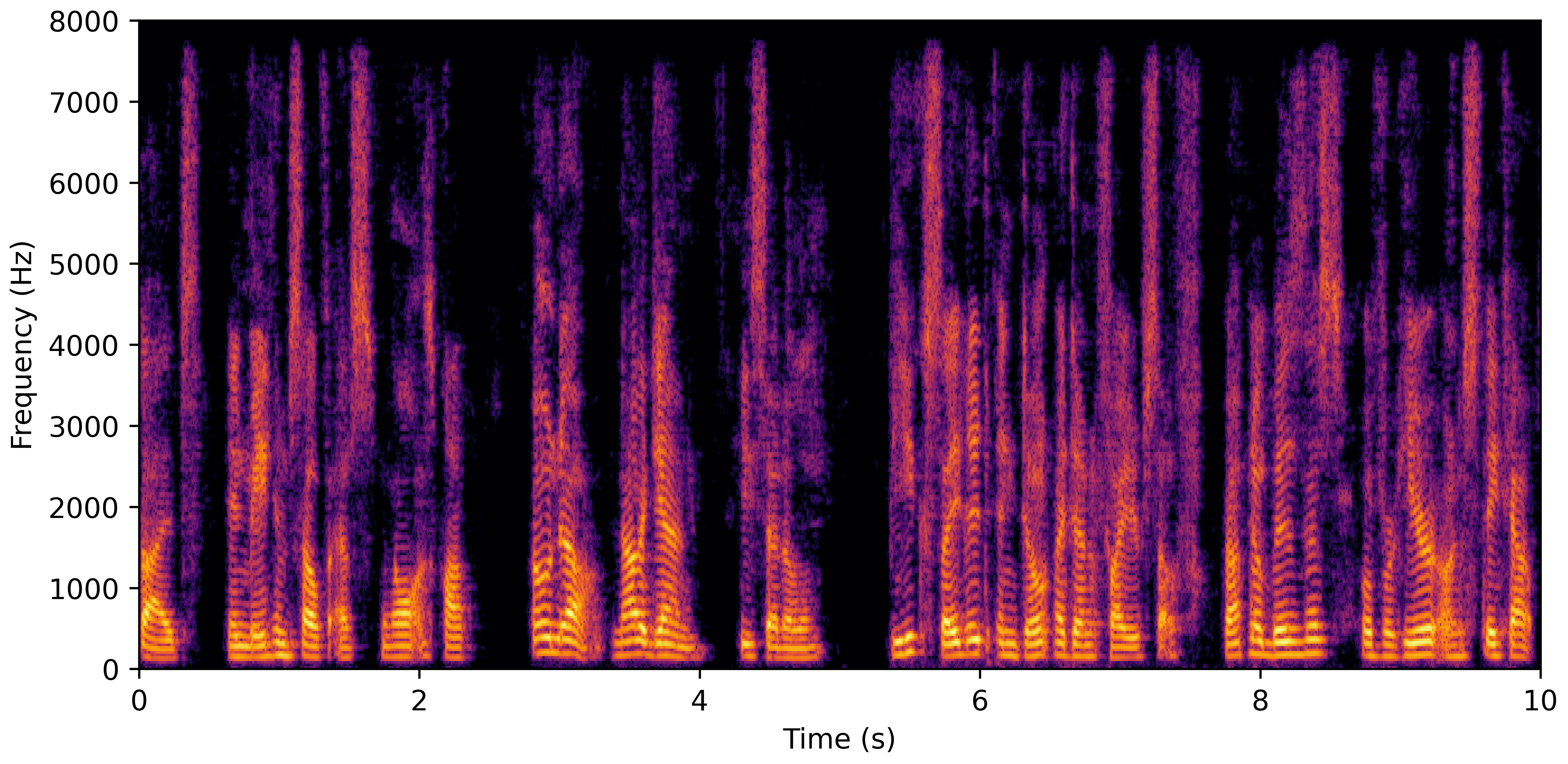
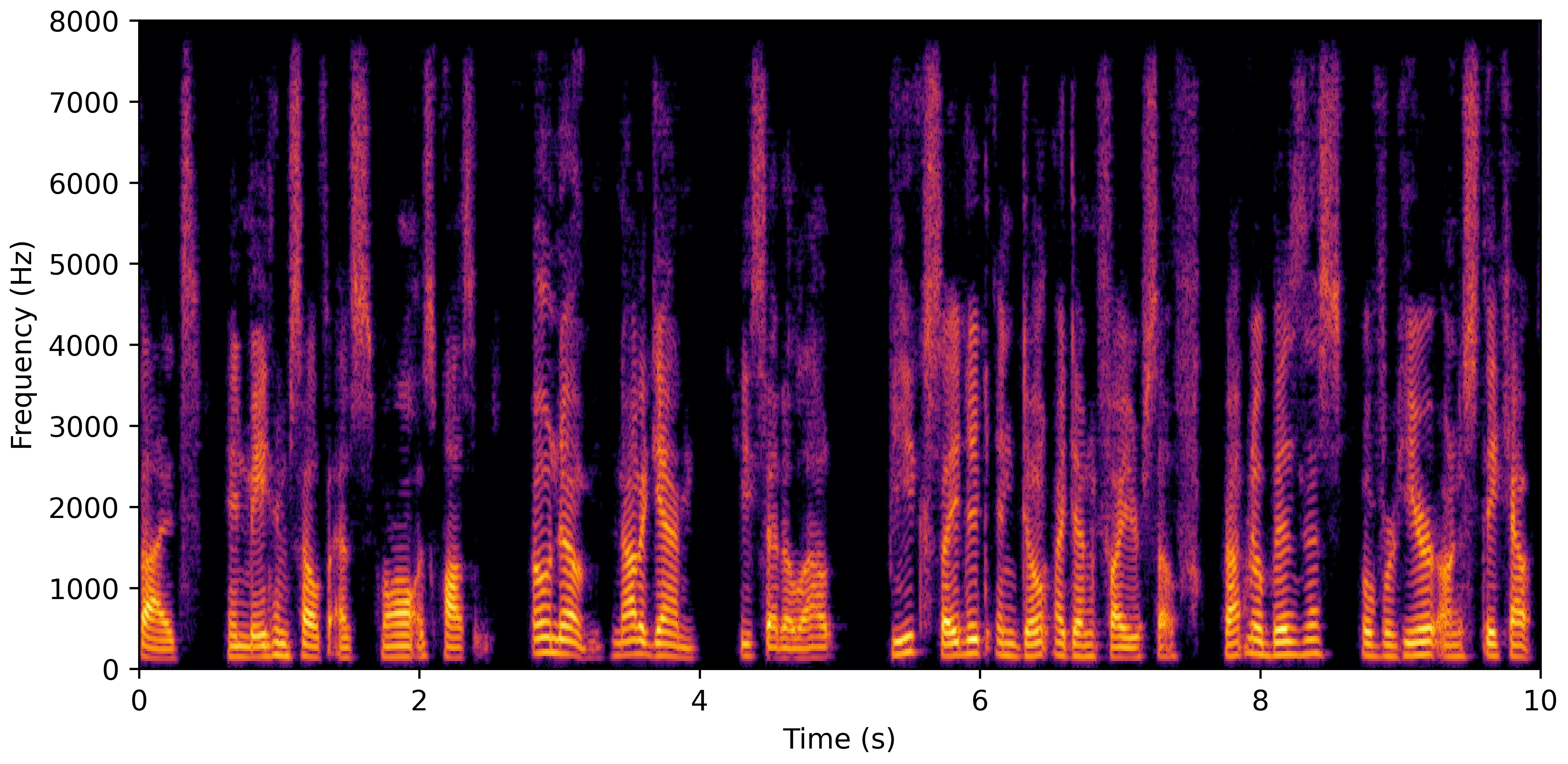
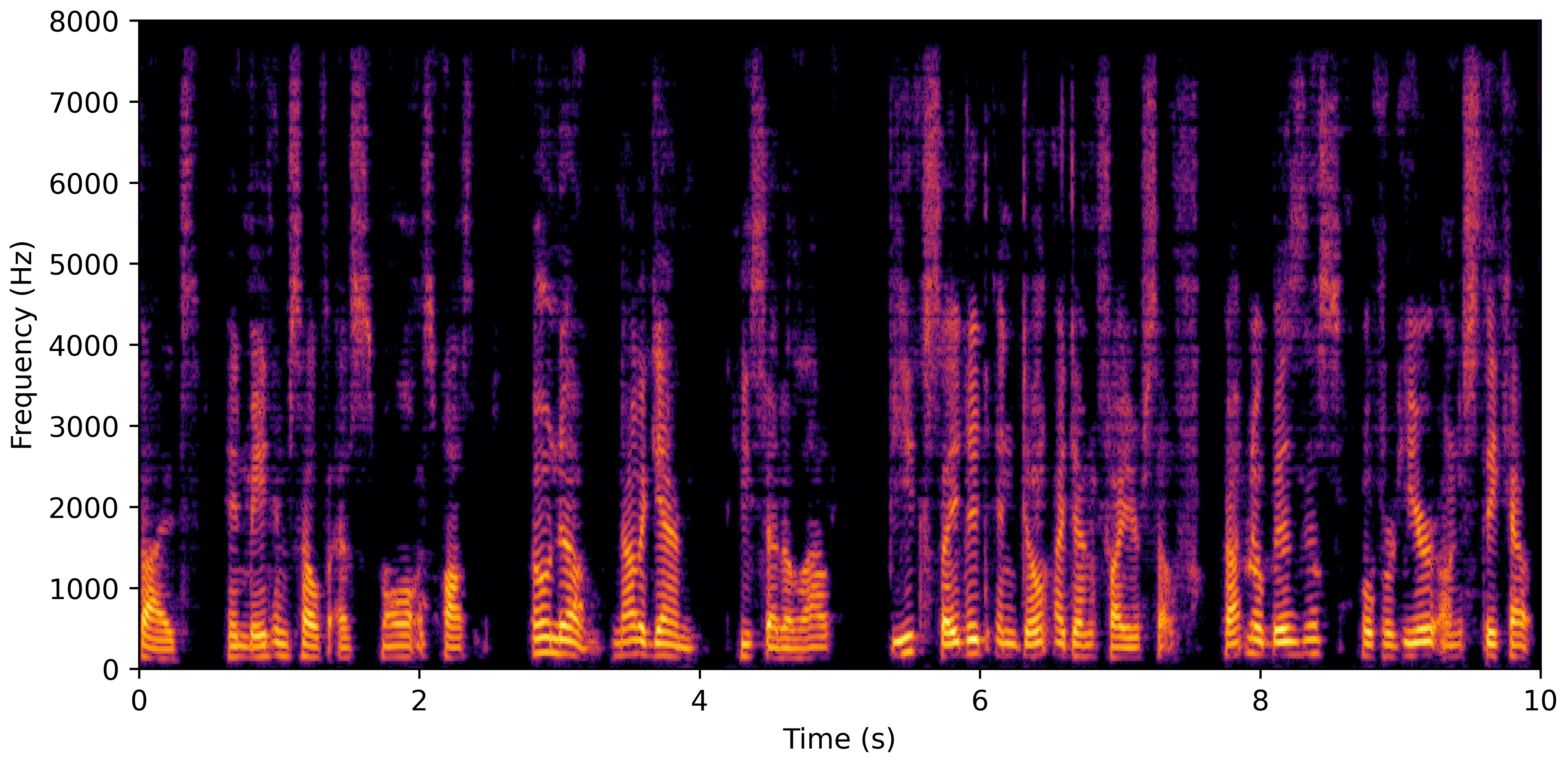
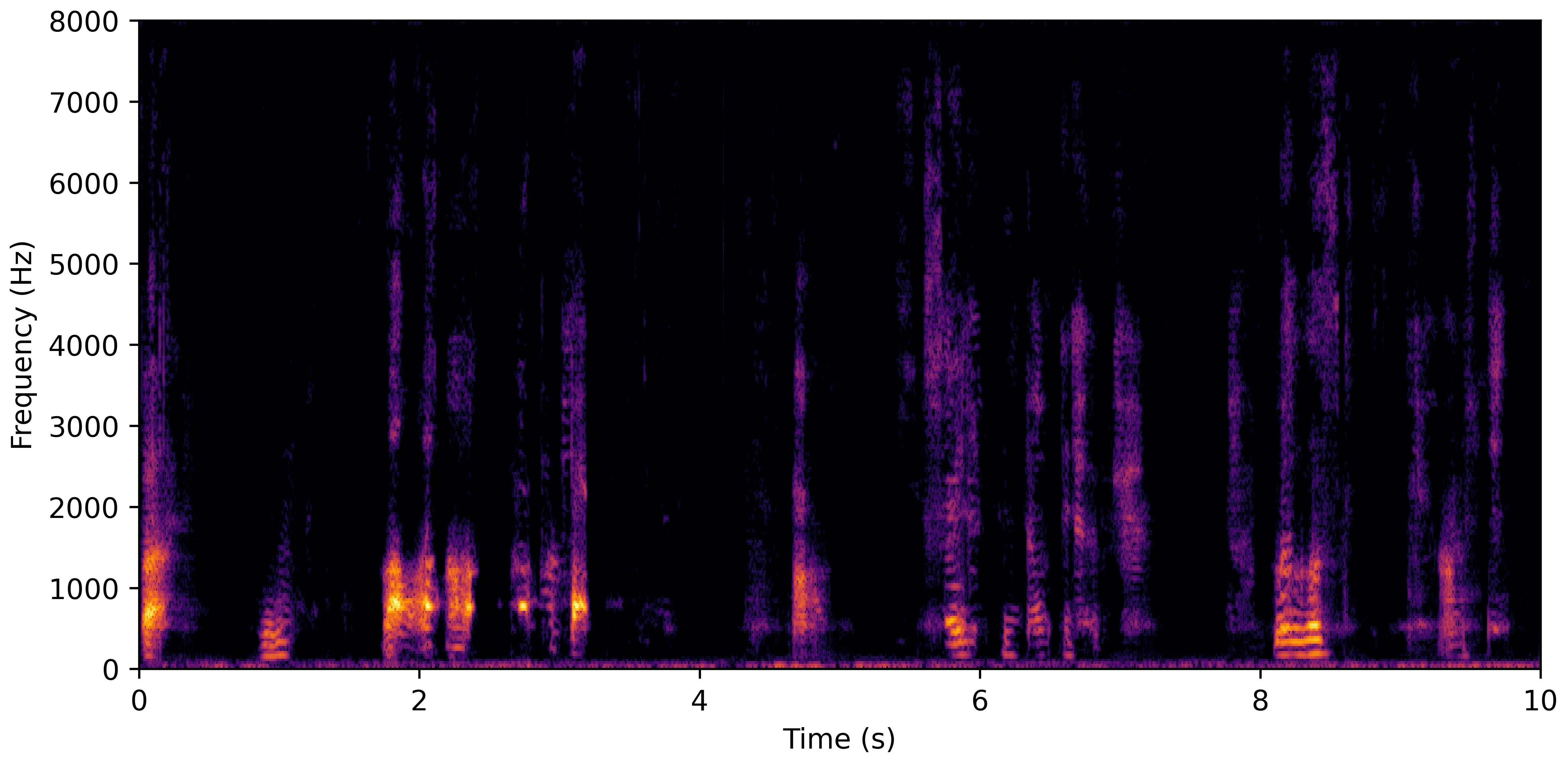
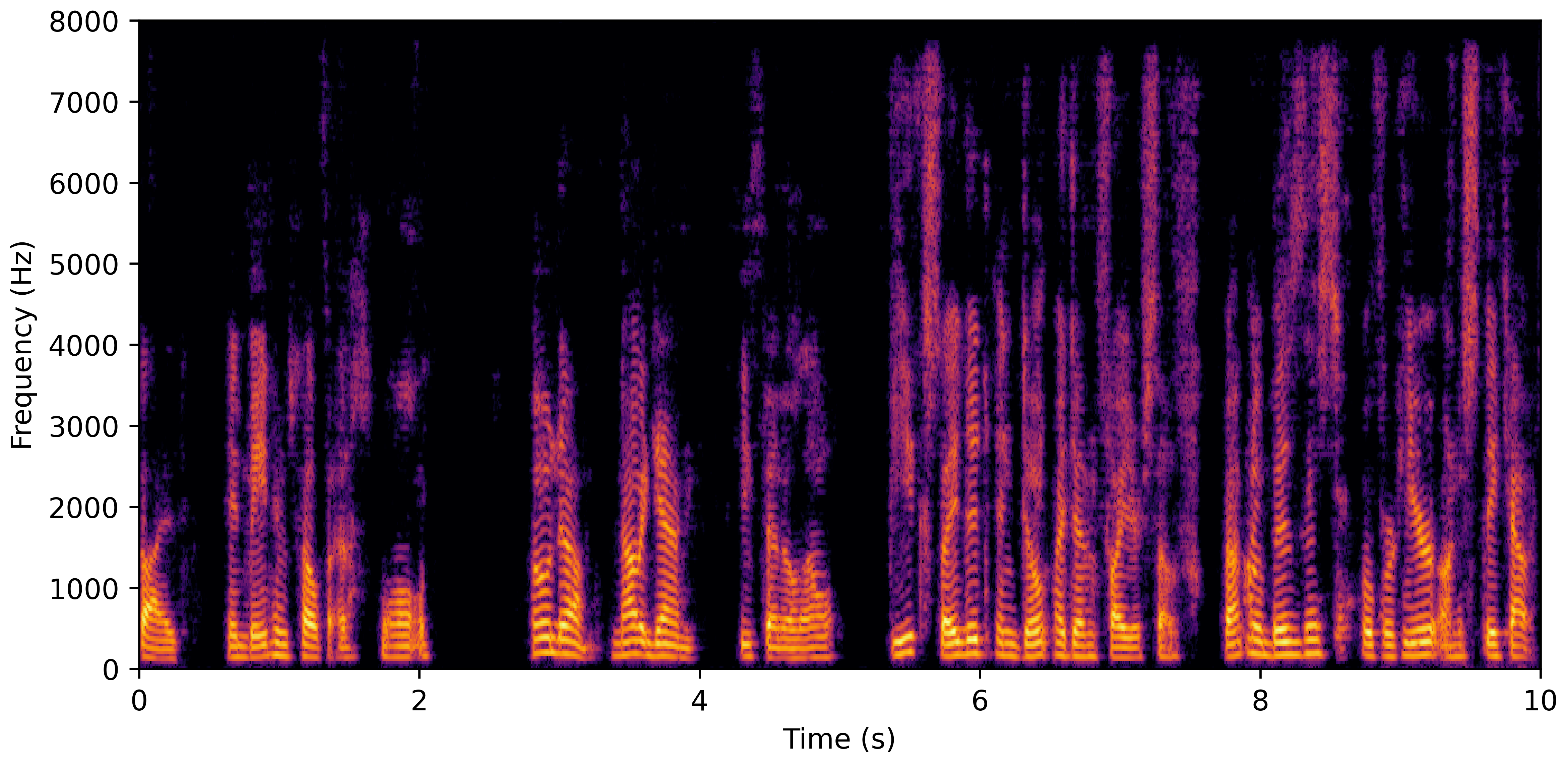
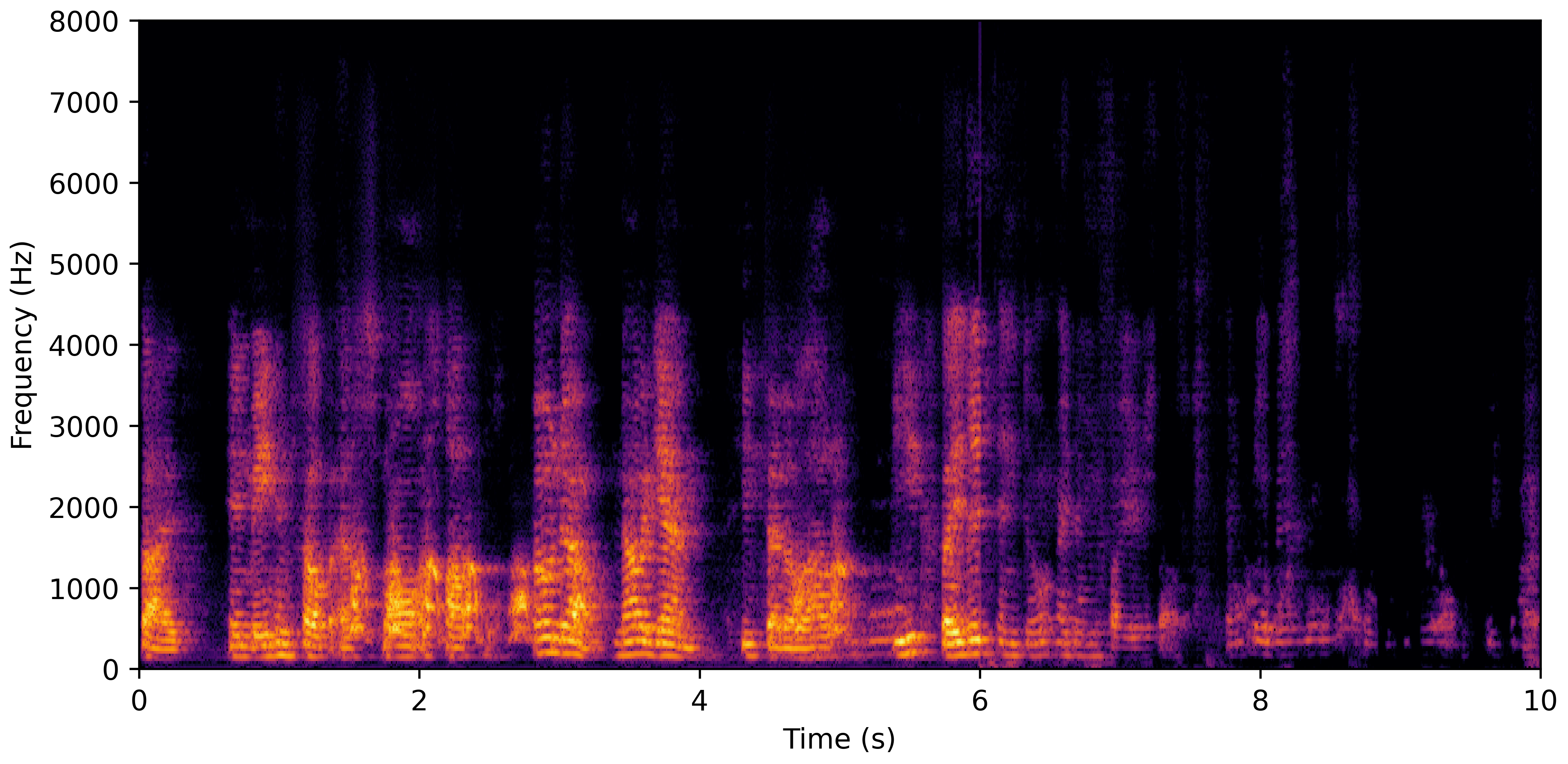
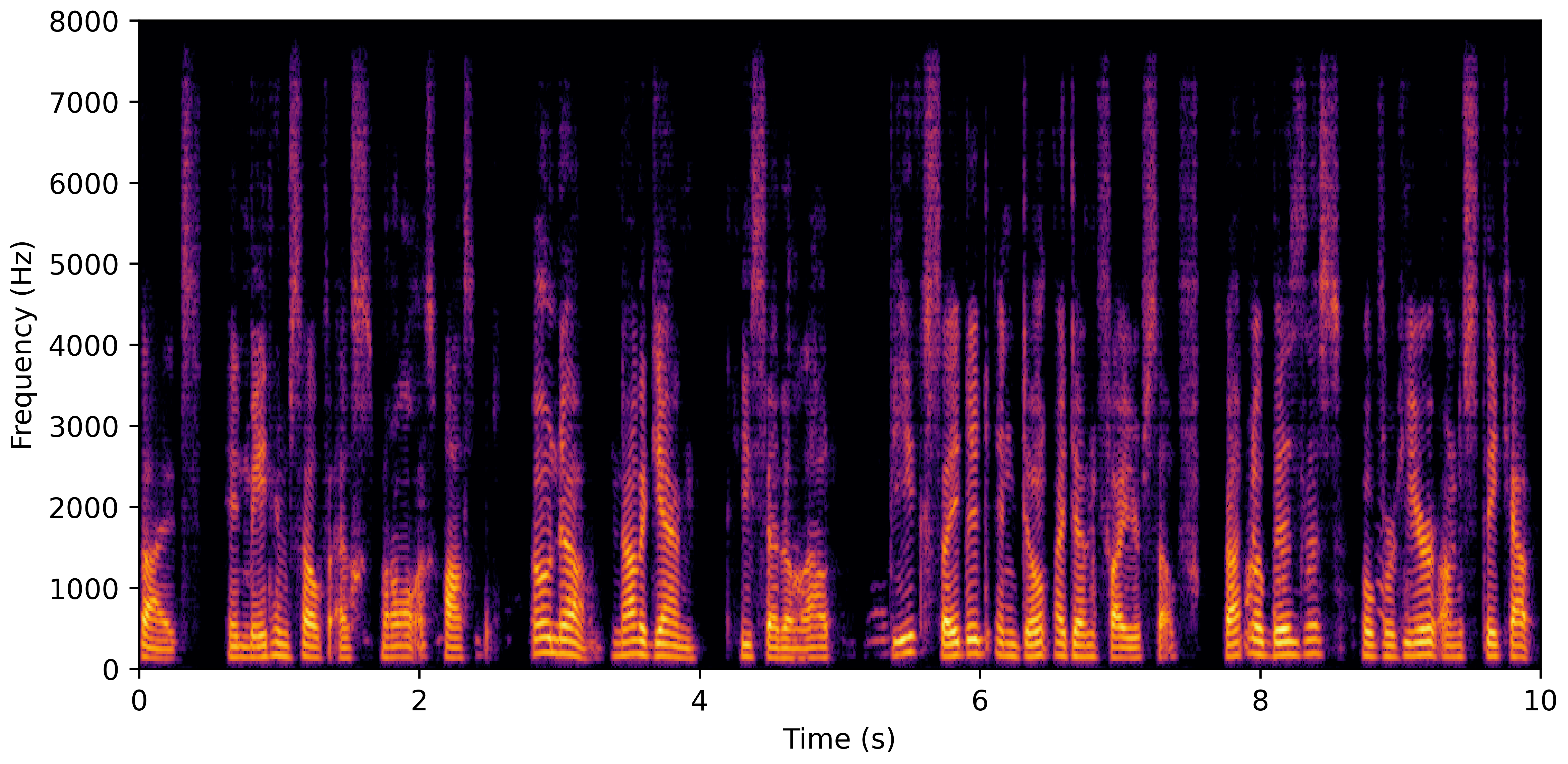
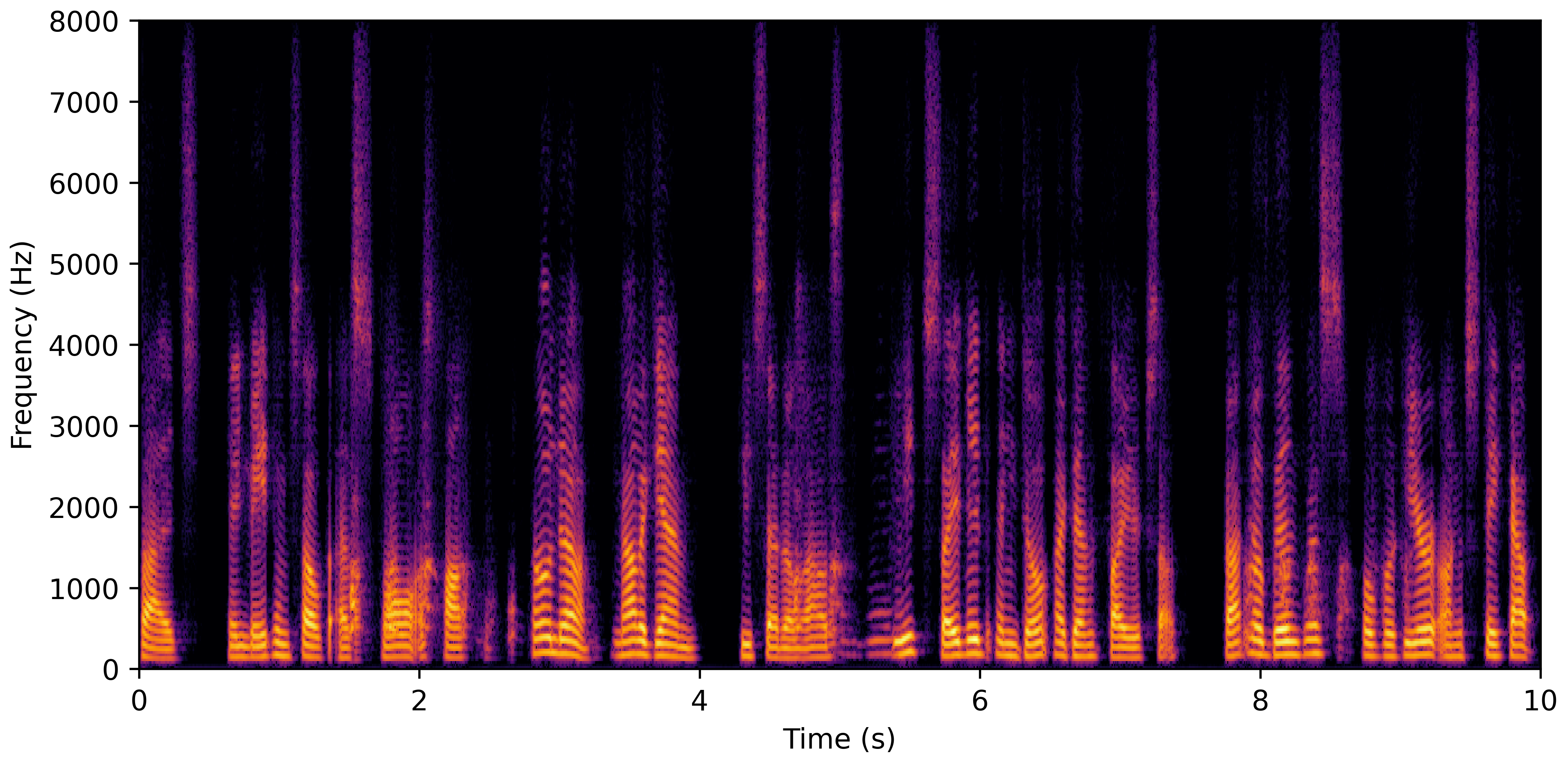
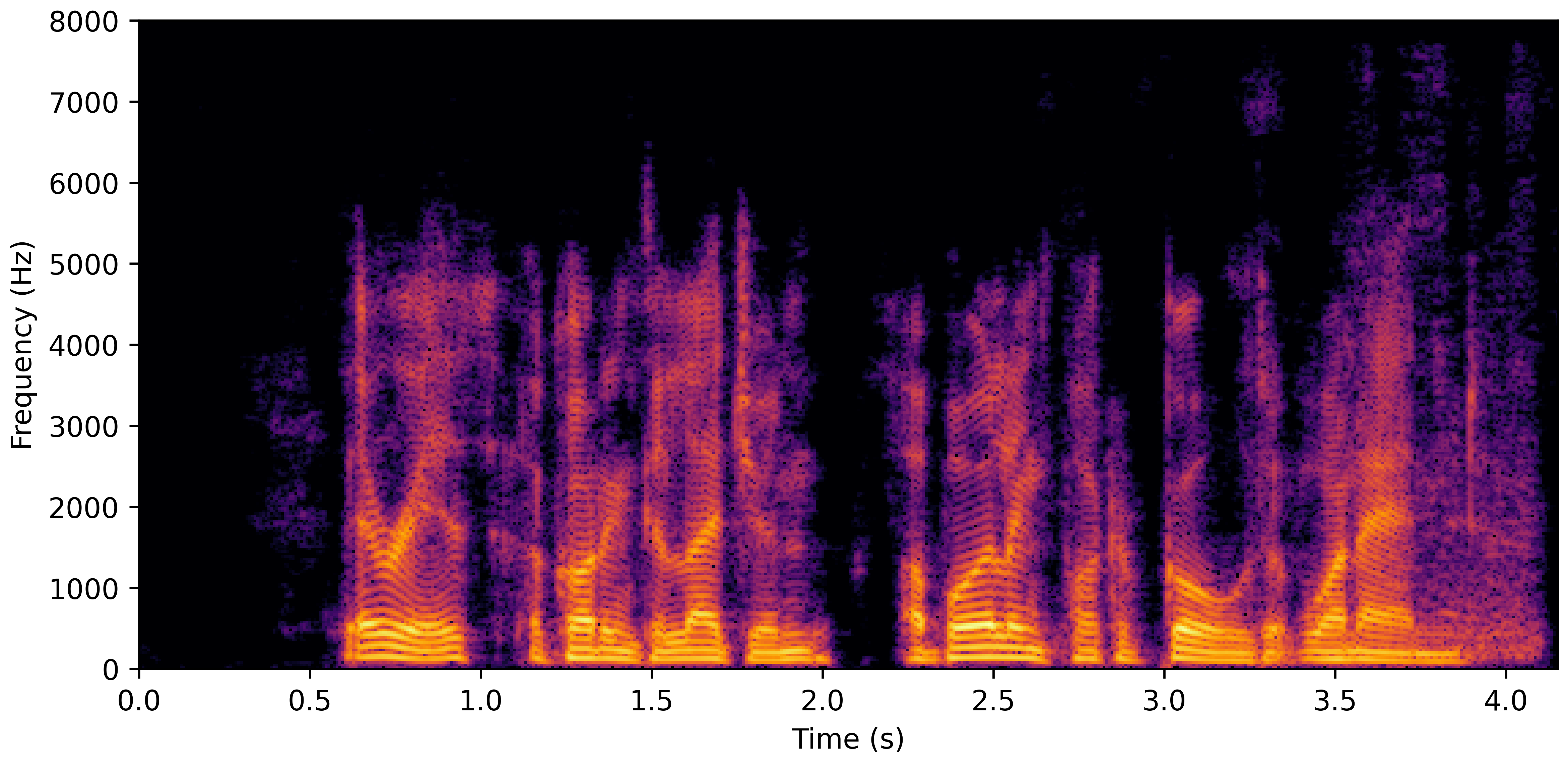
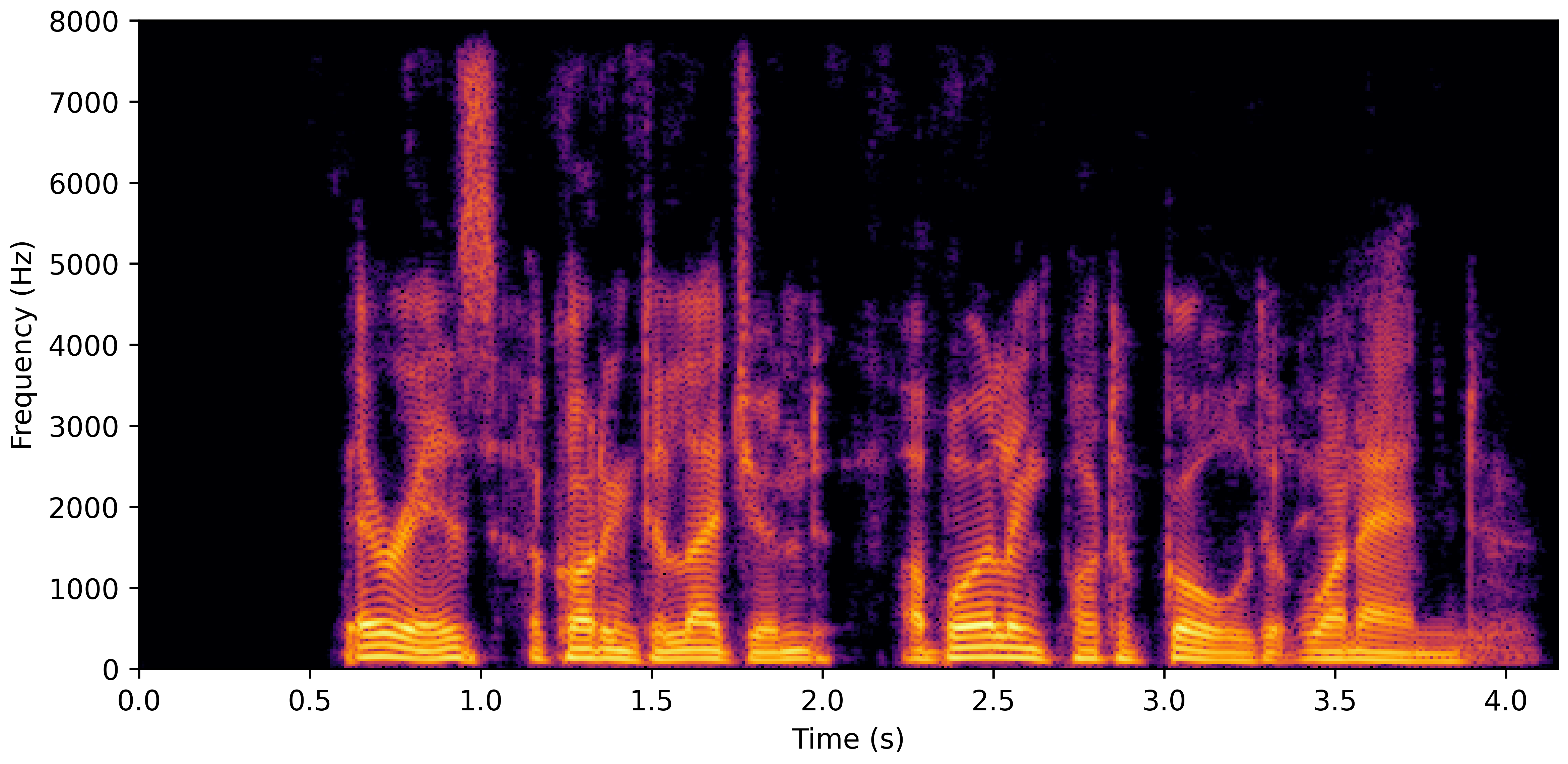
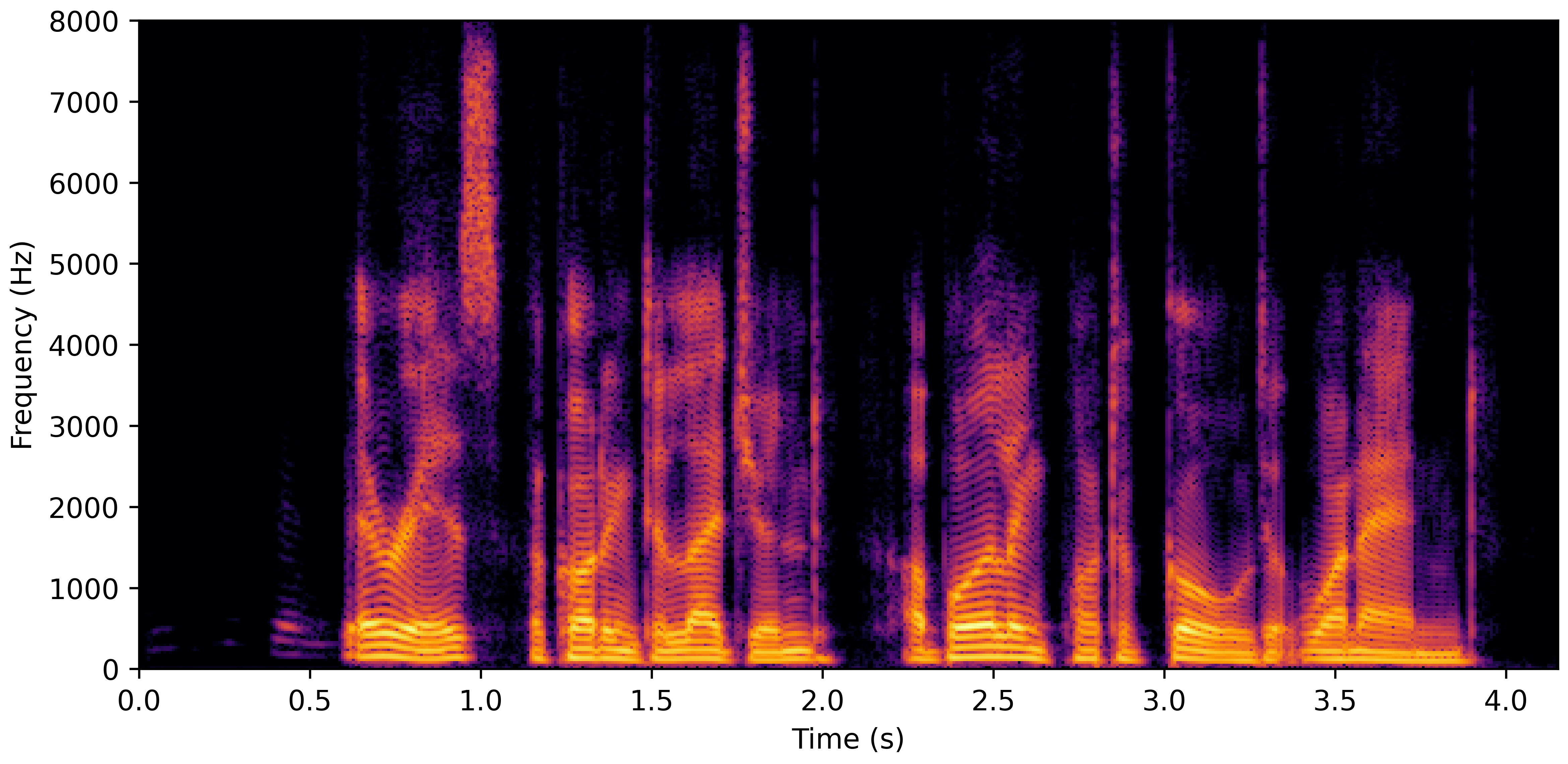
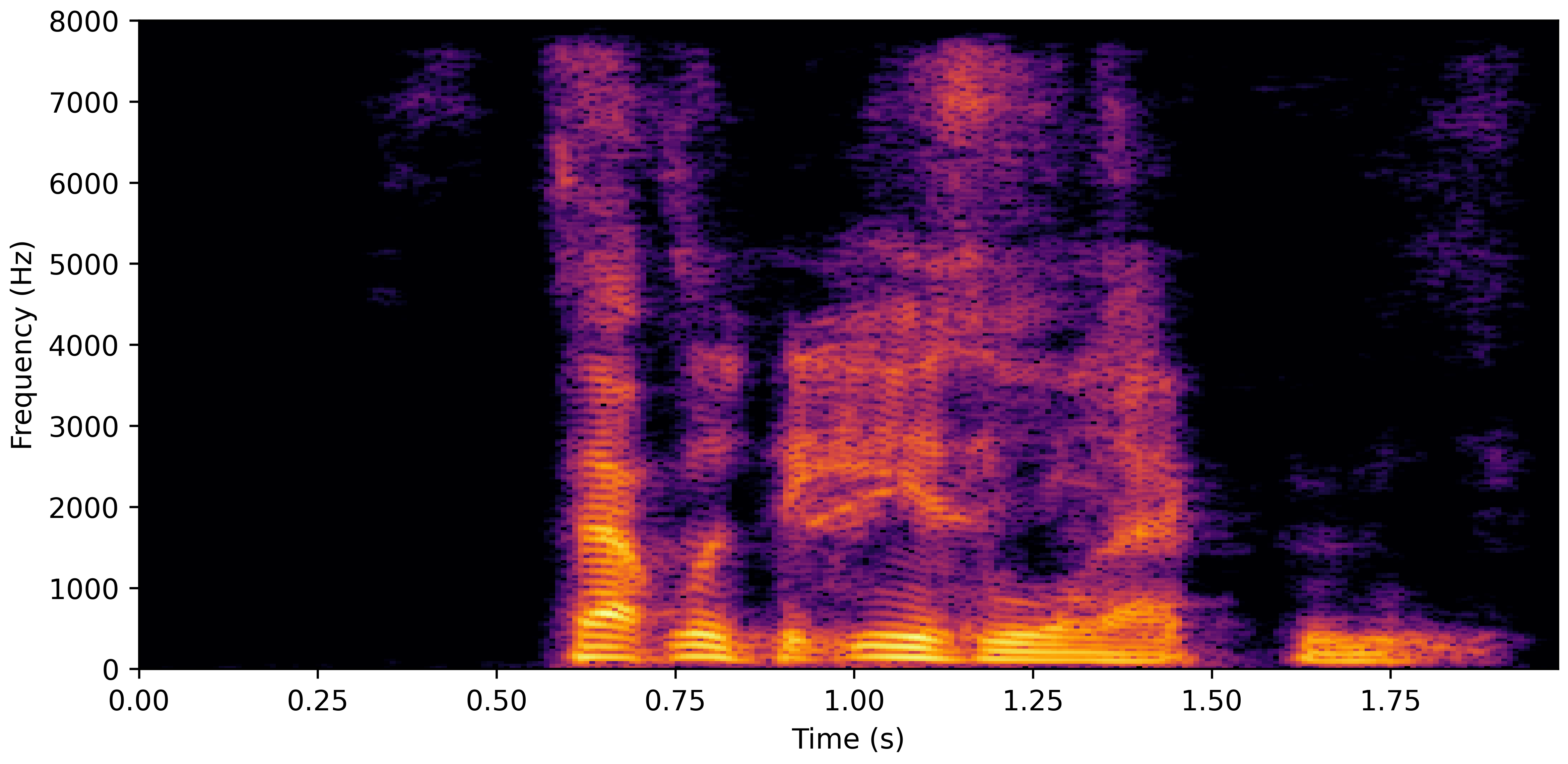
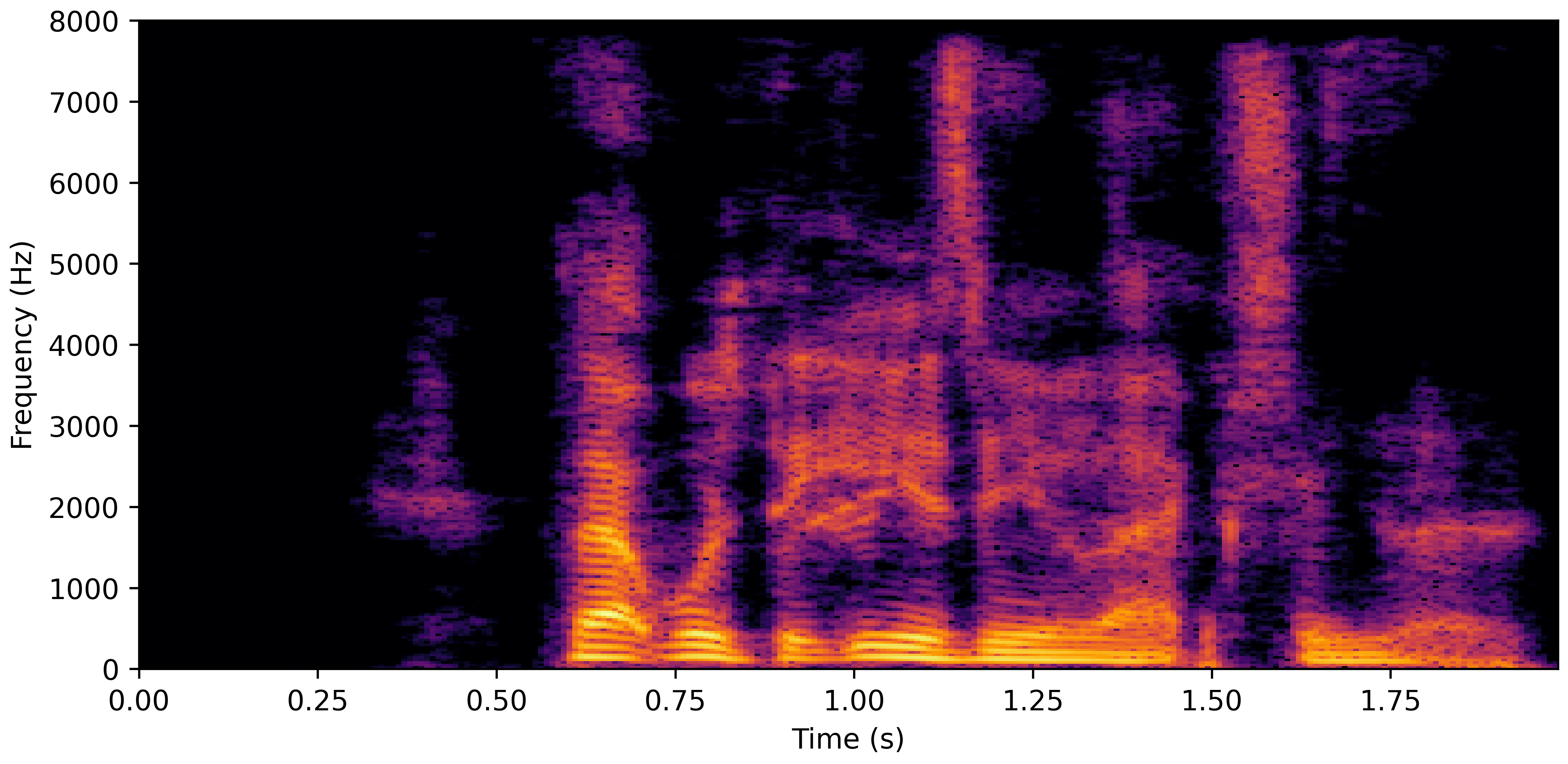
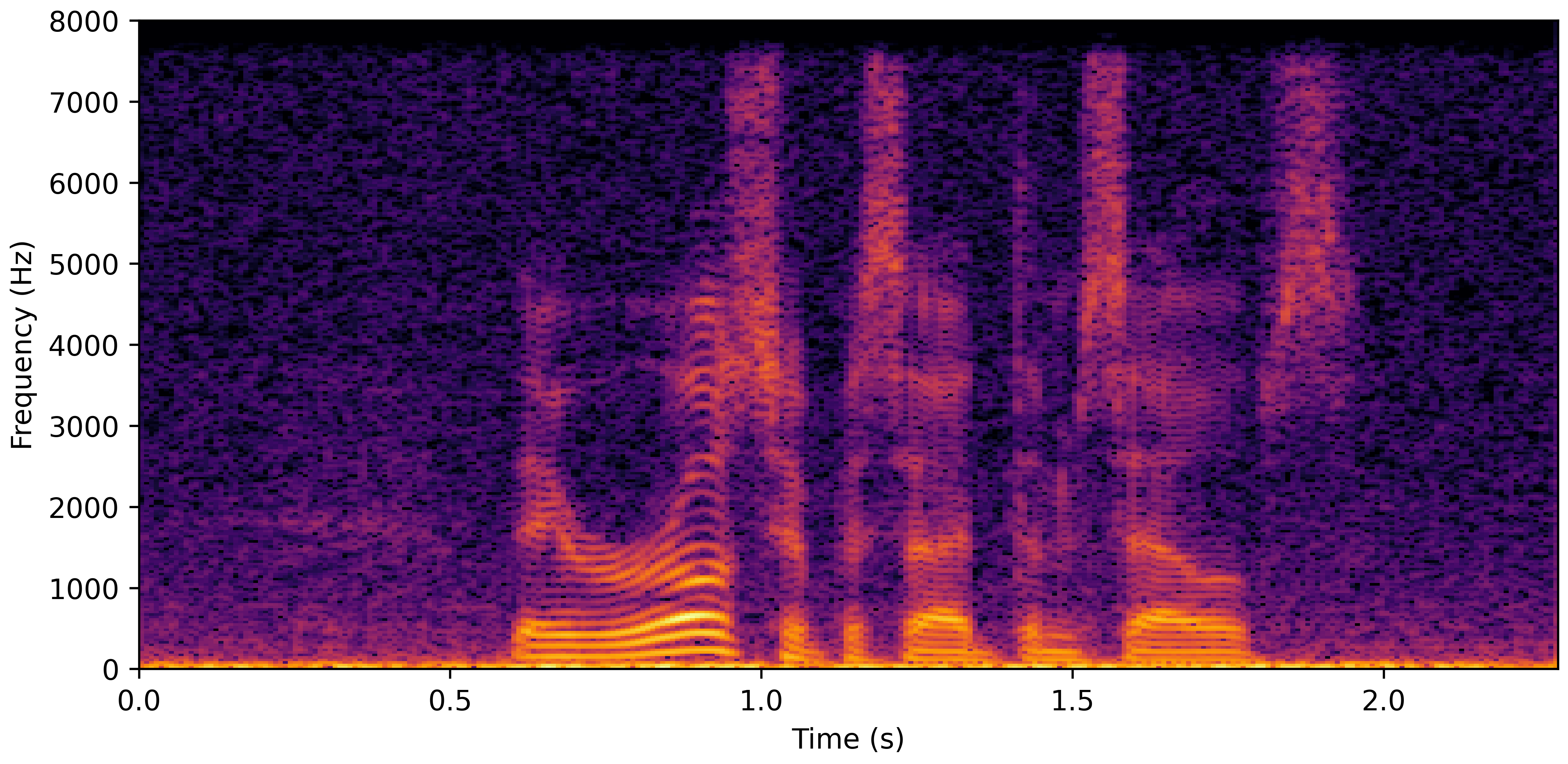
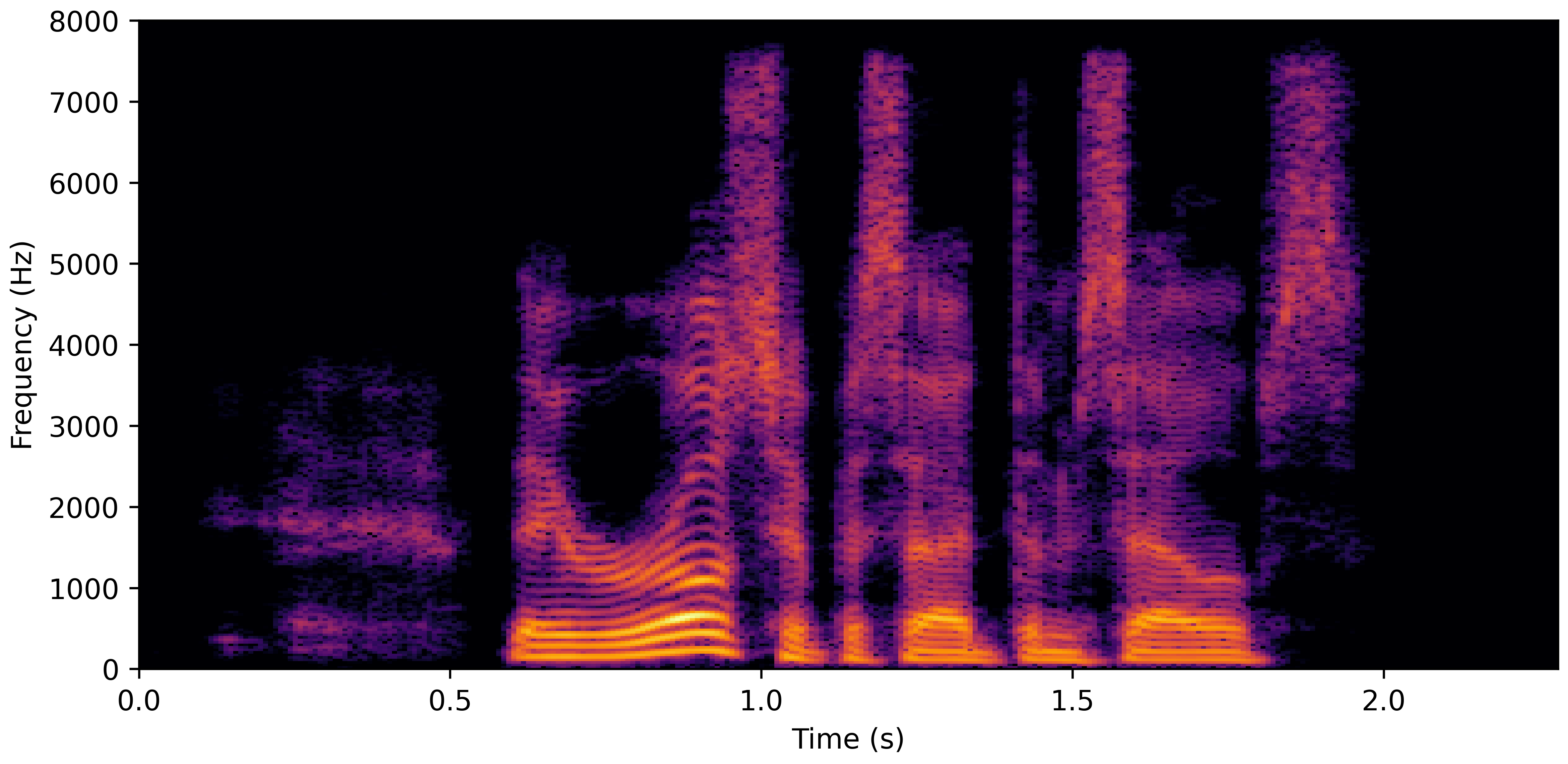
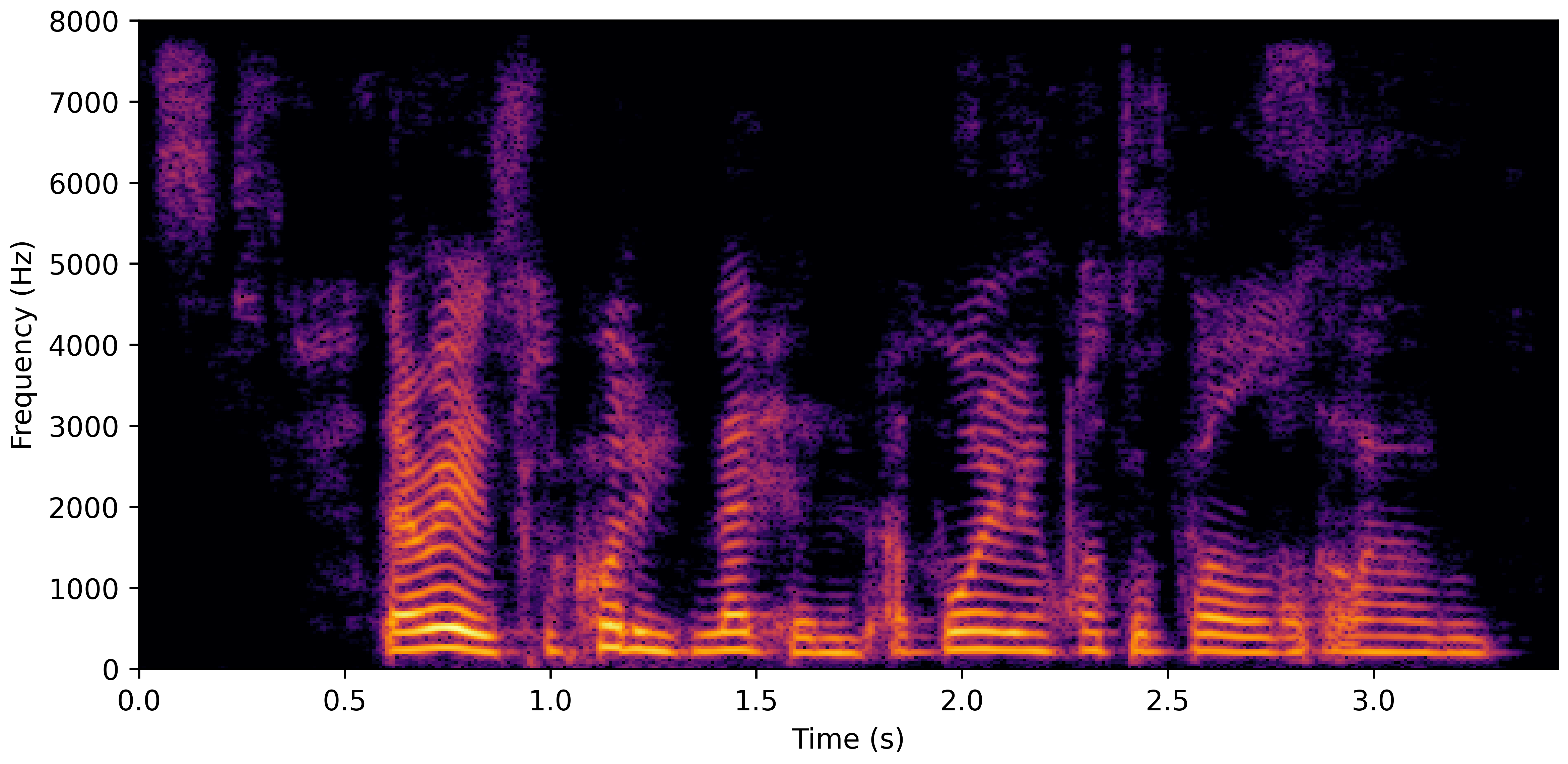
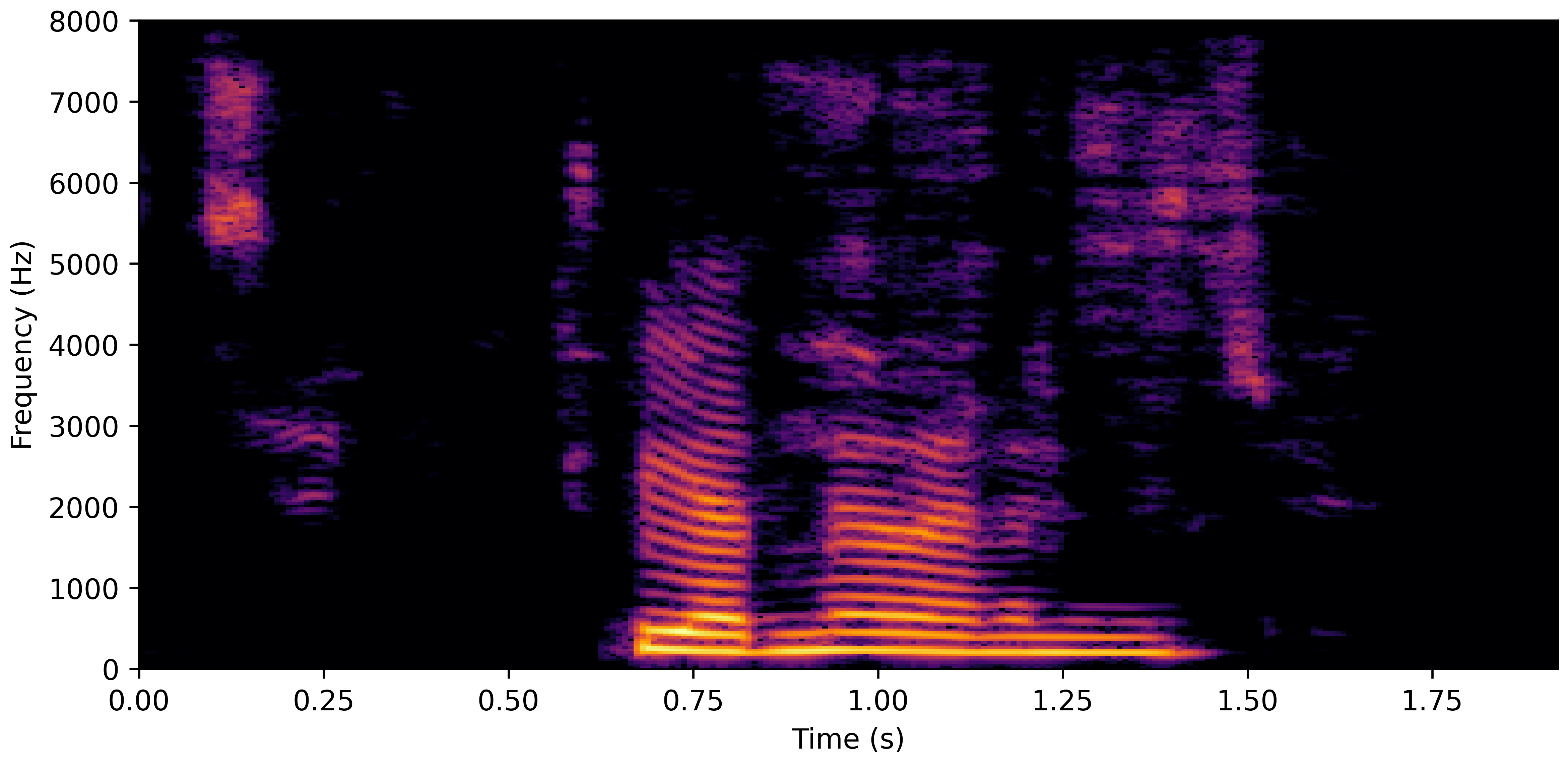
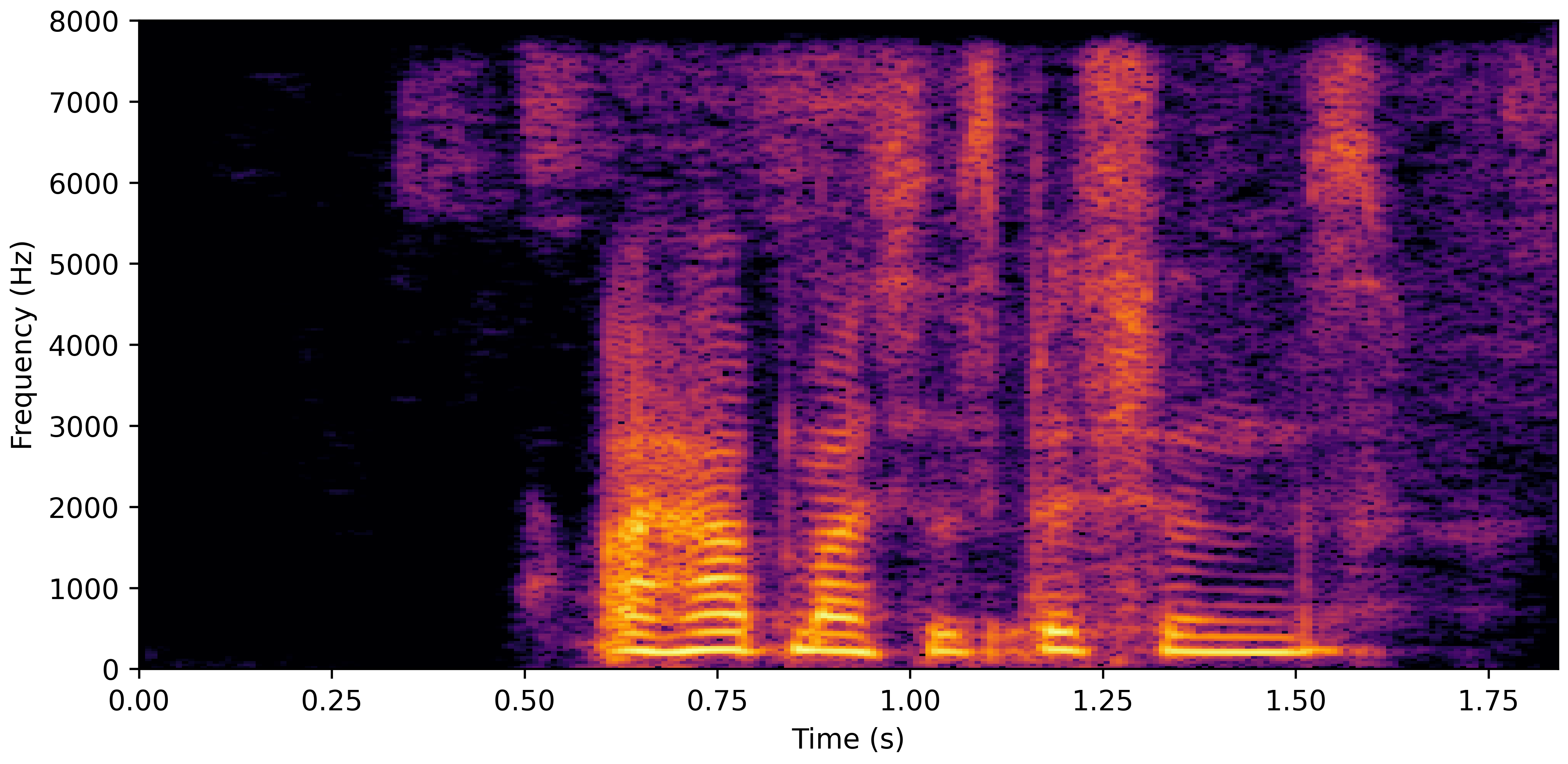
DNS No Reverb
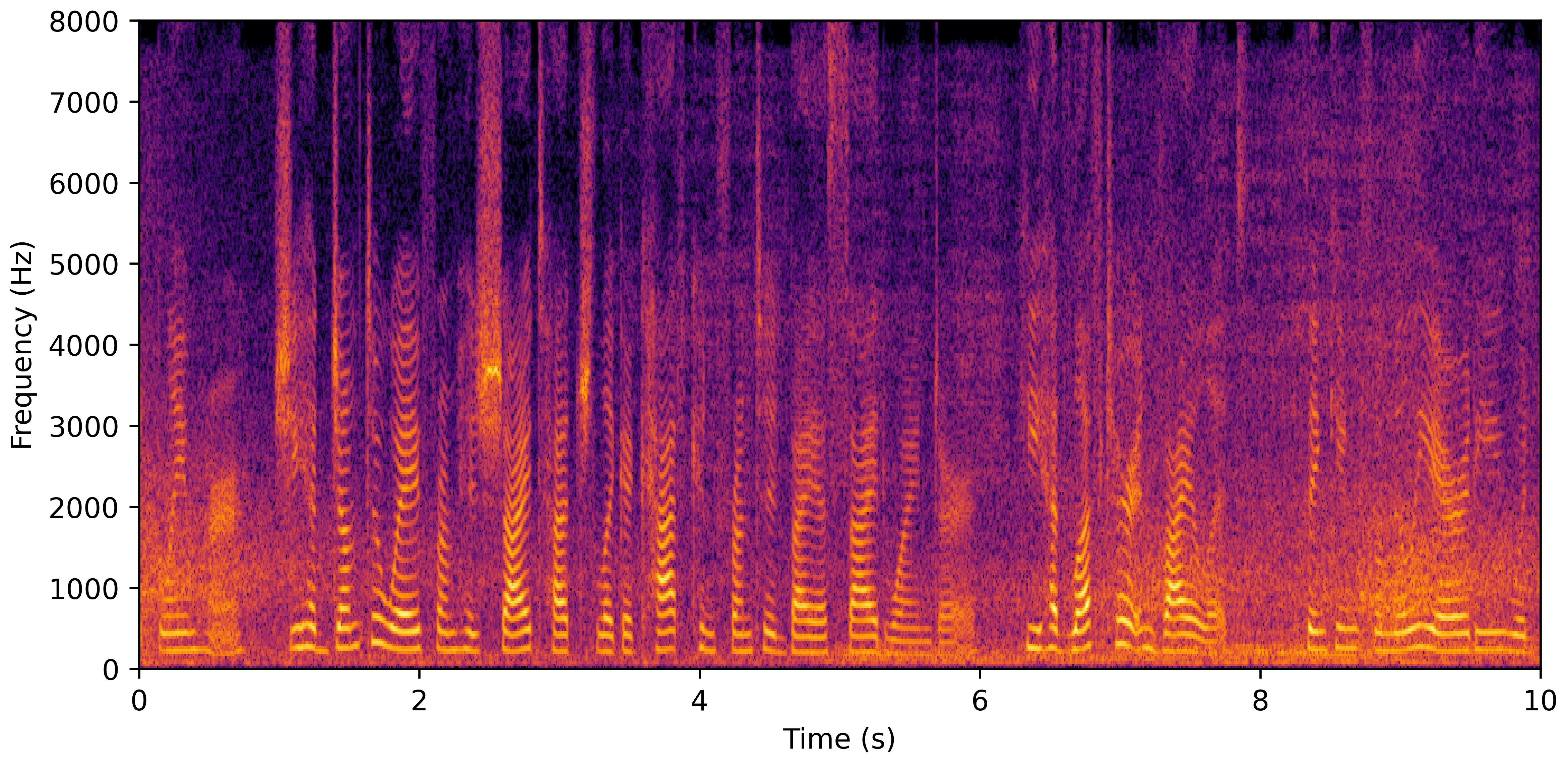
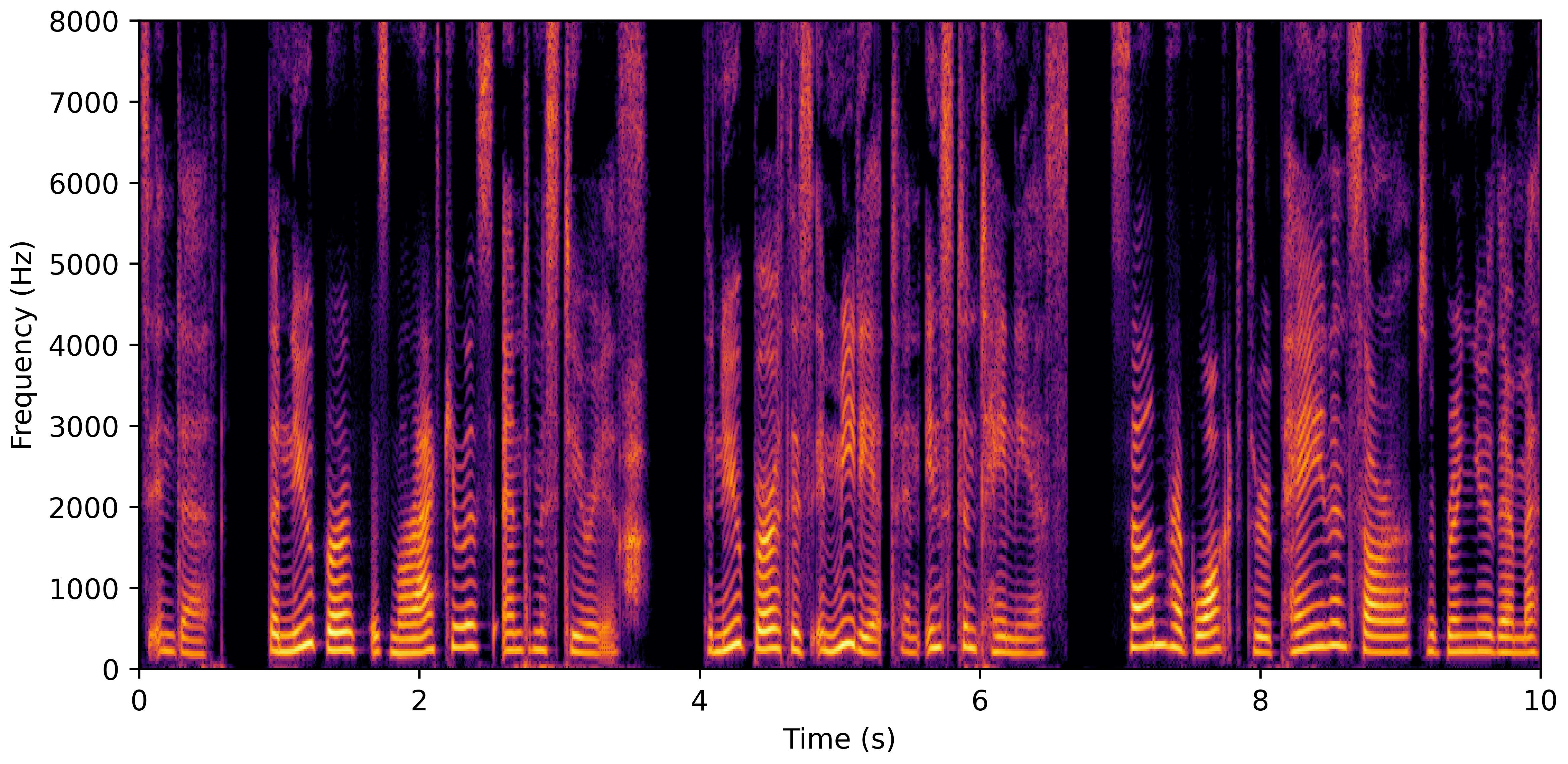
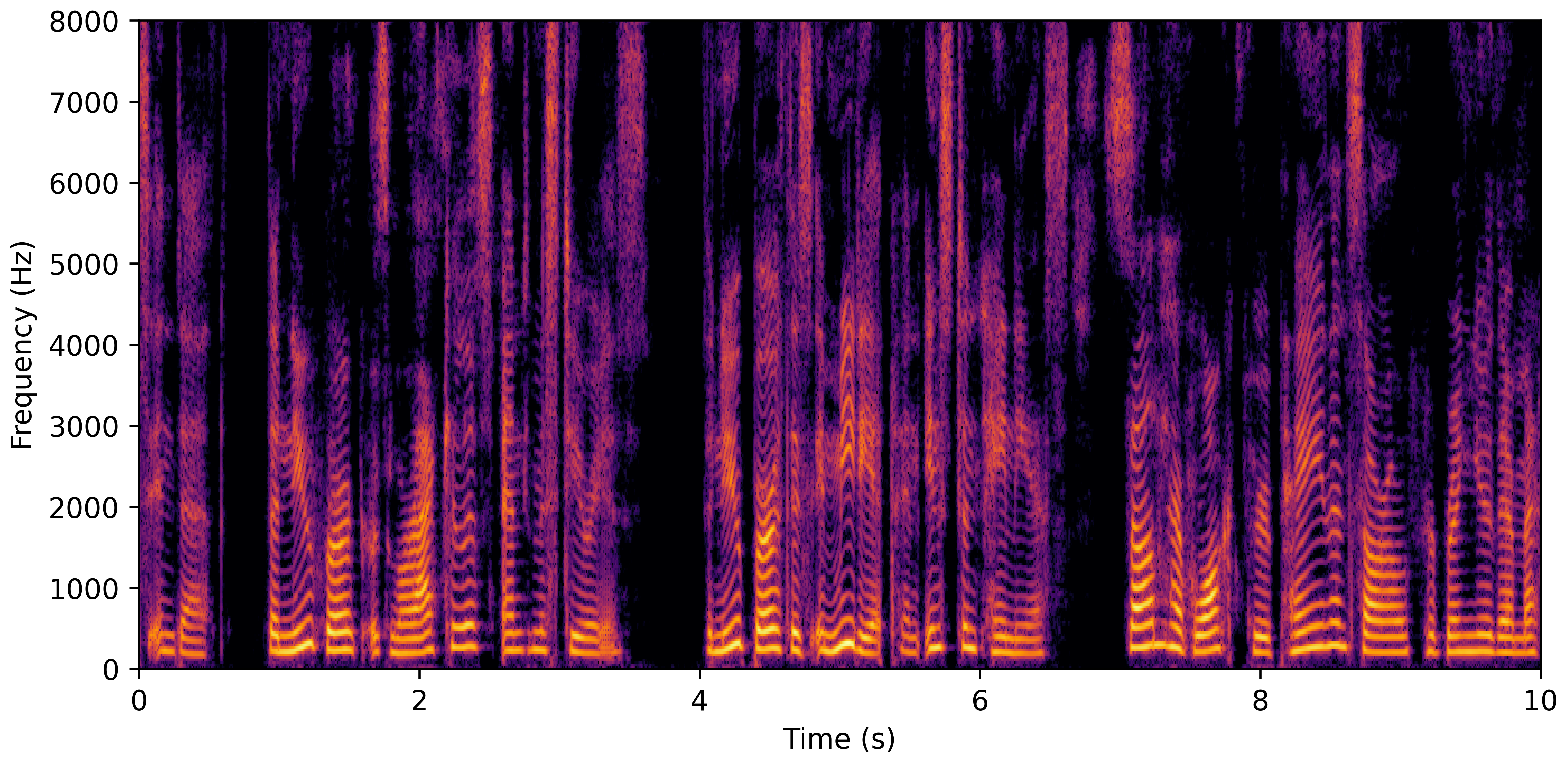
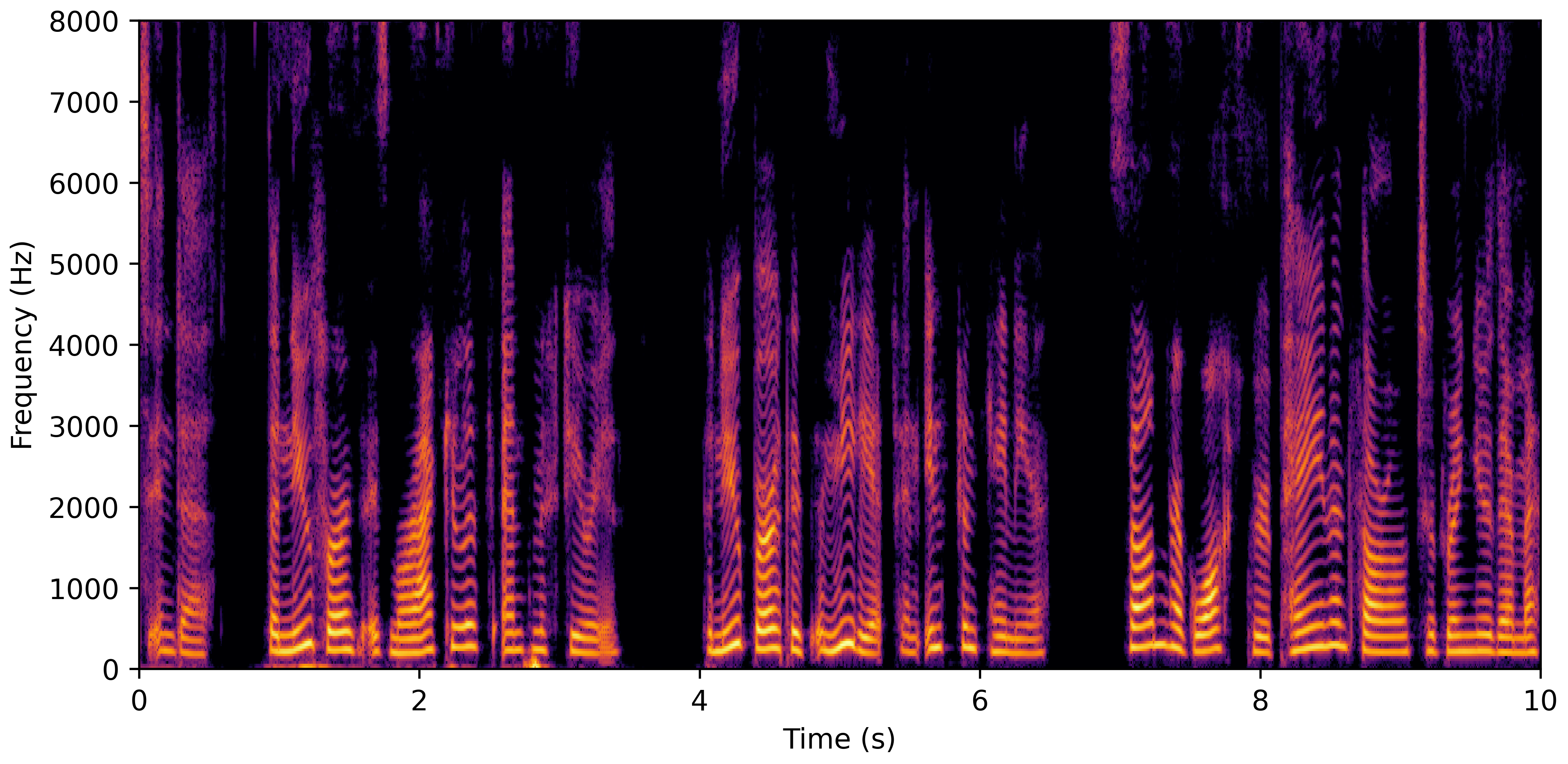
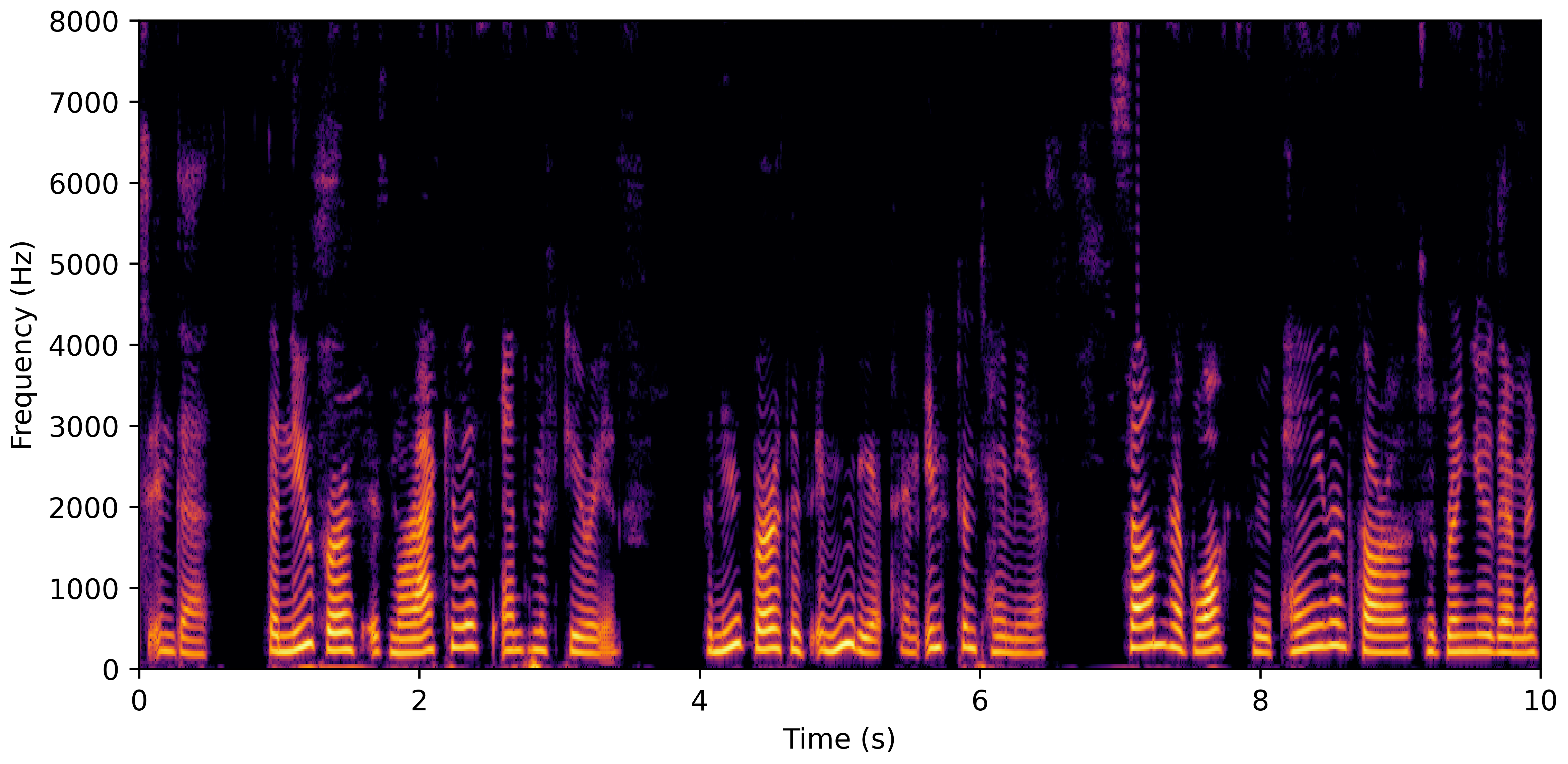
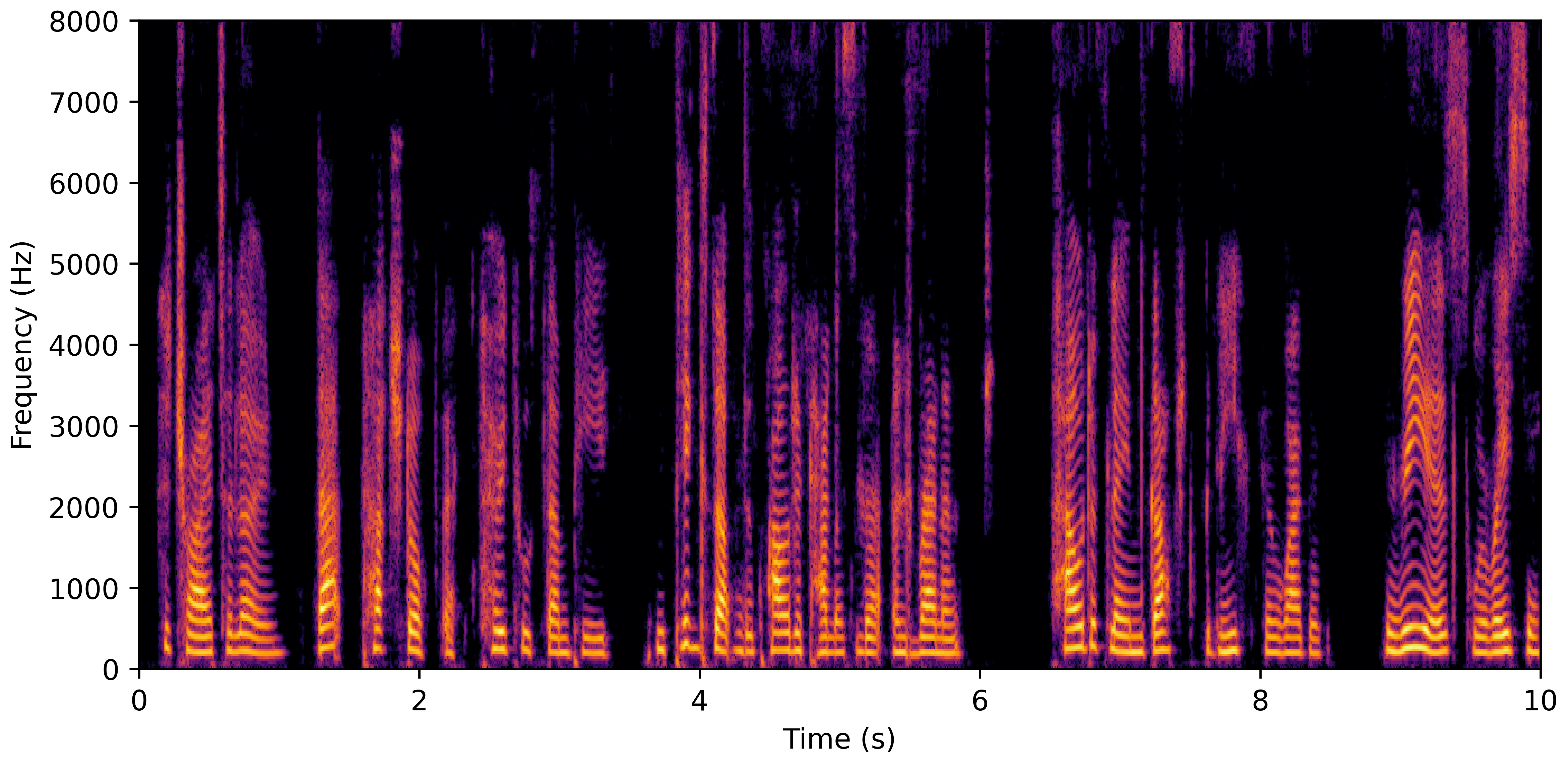
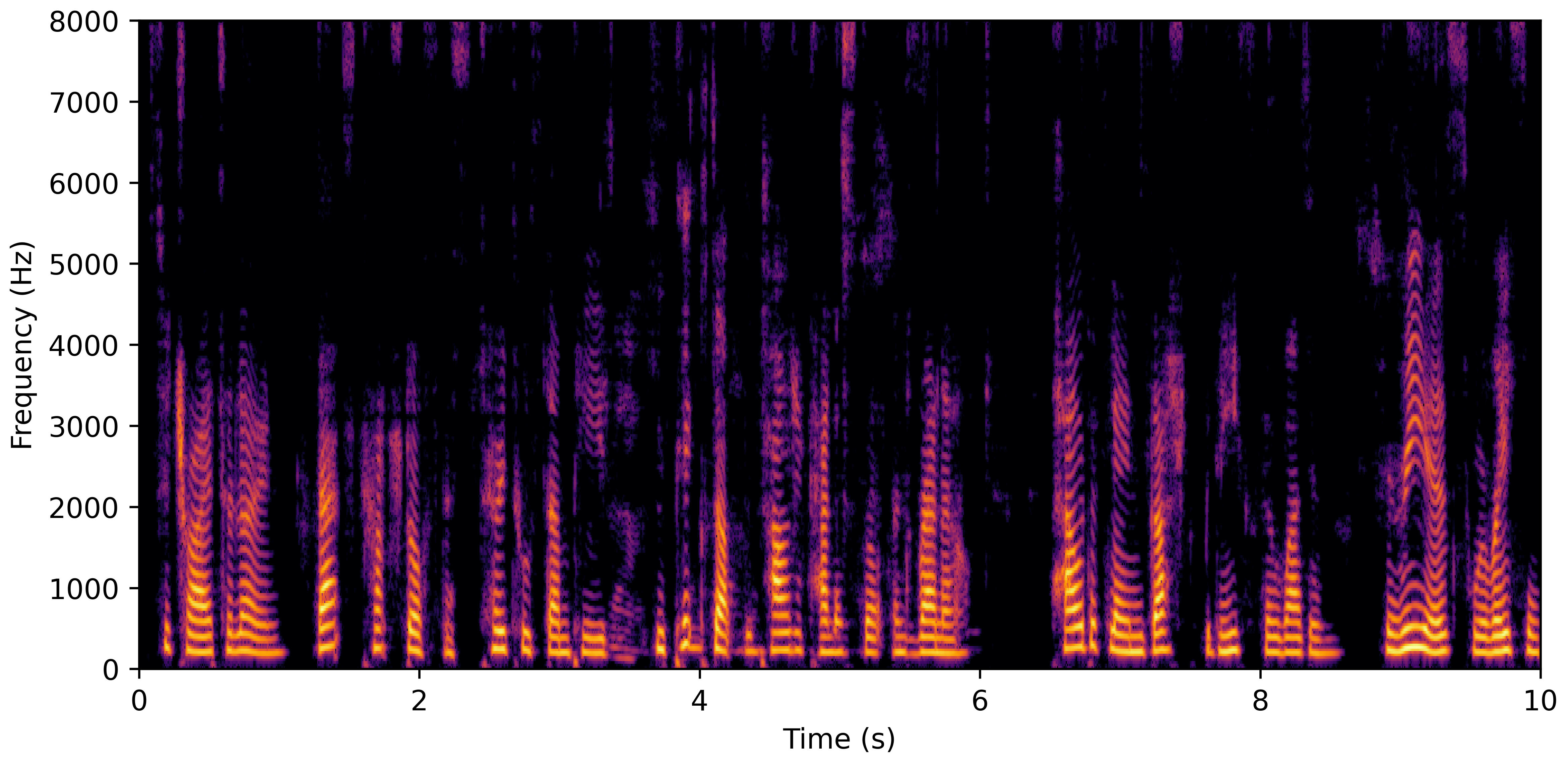
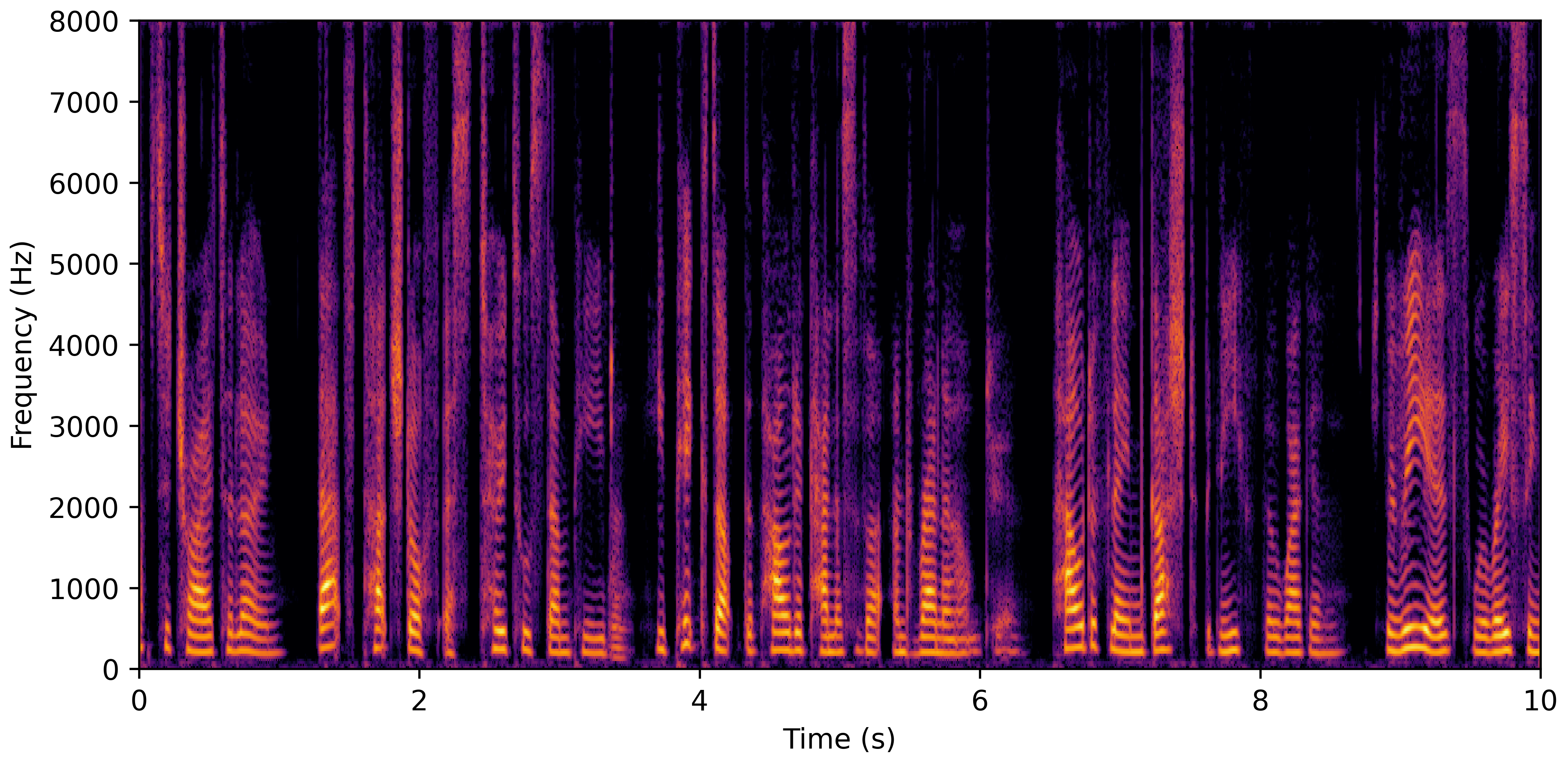
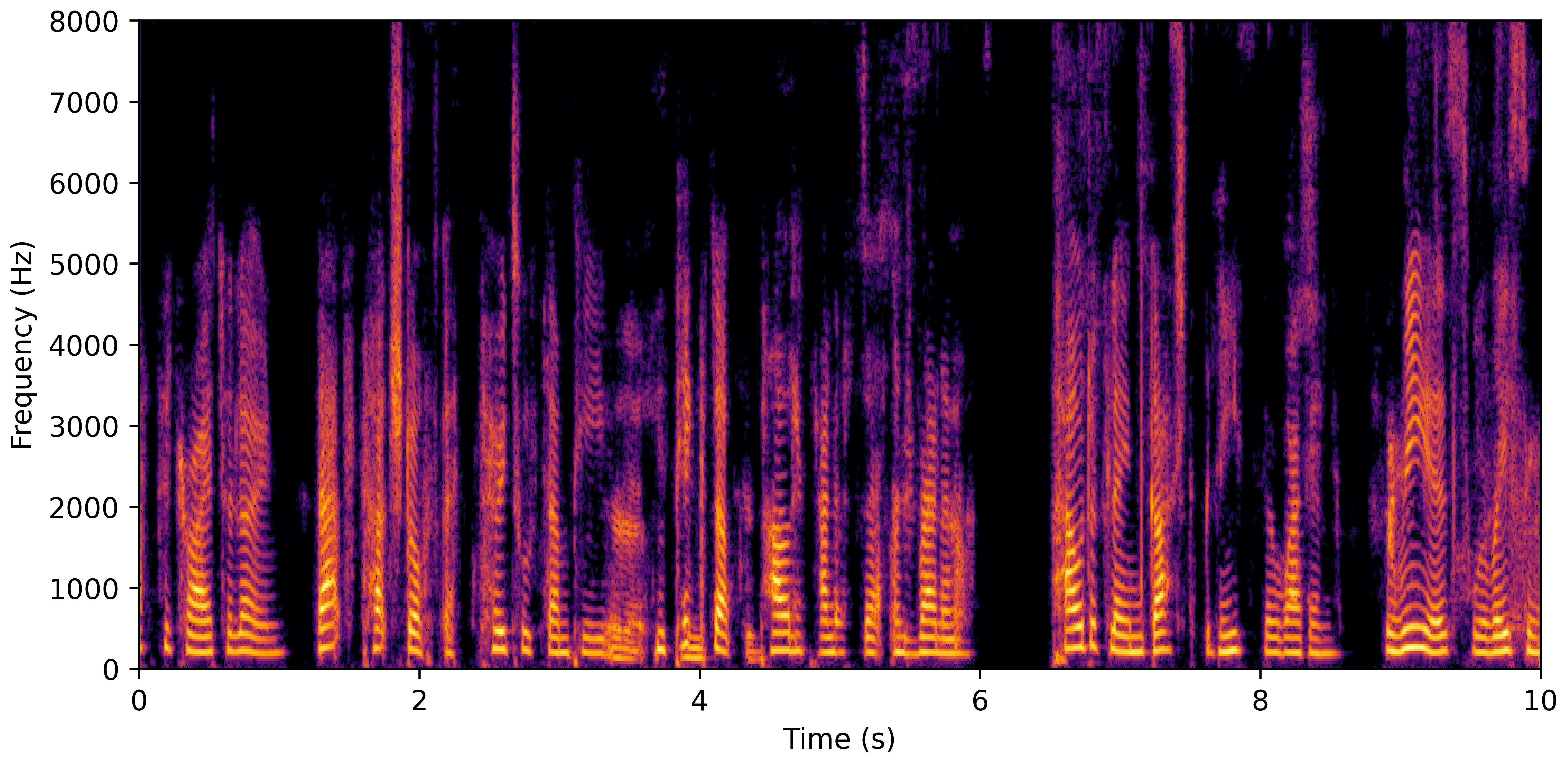
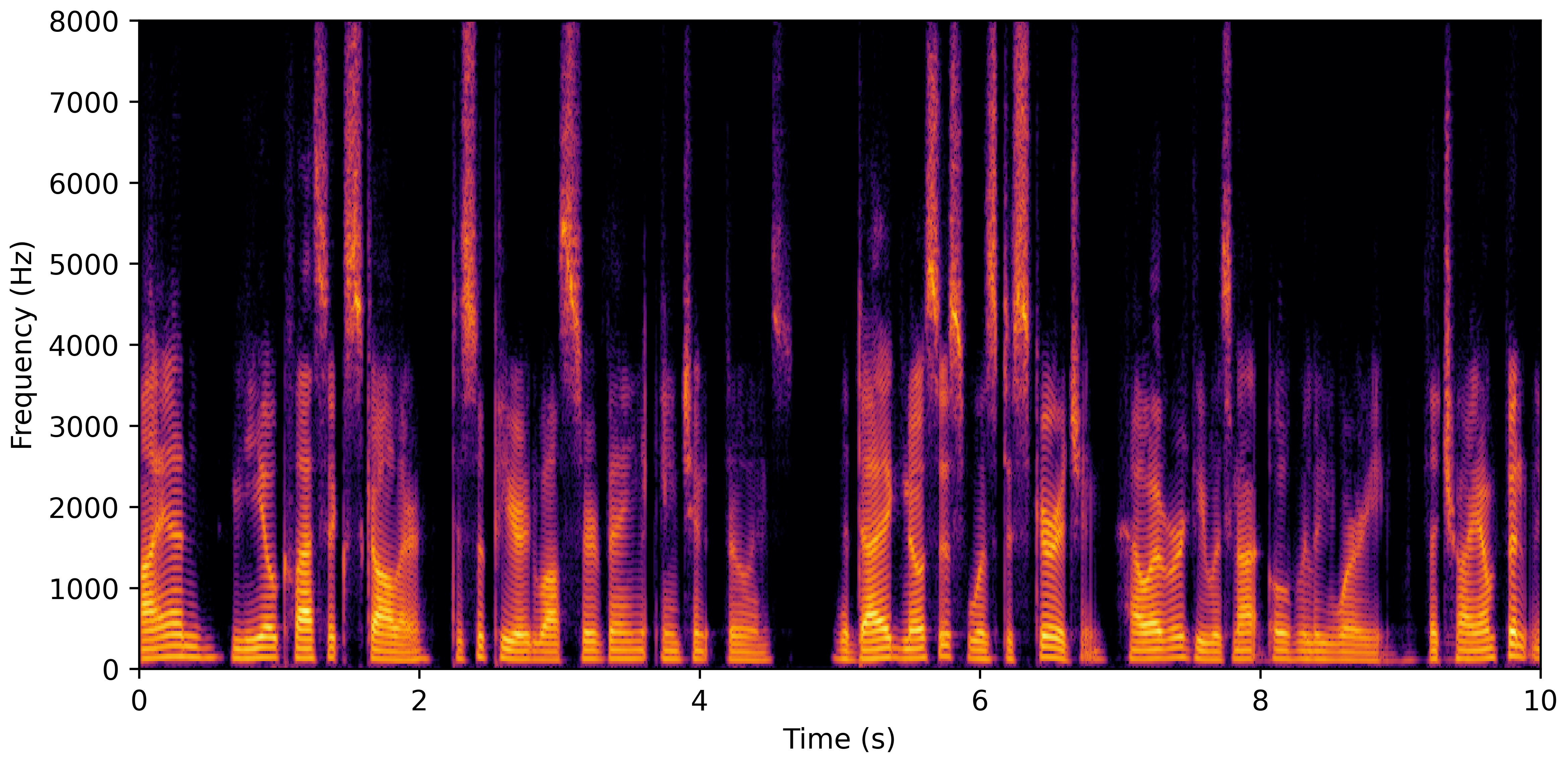
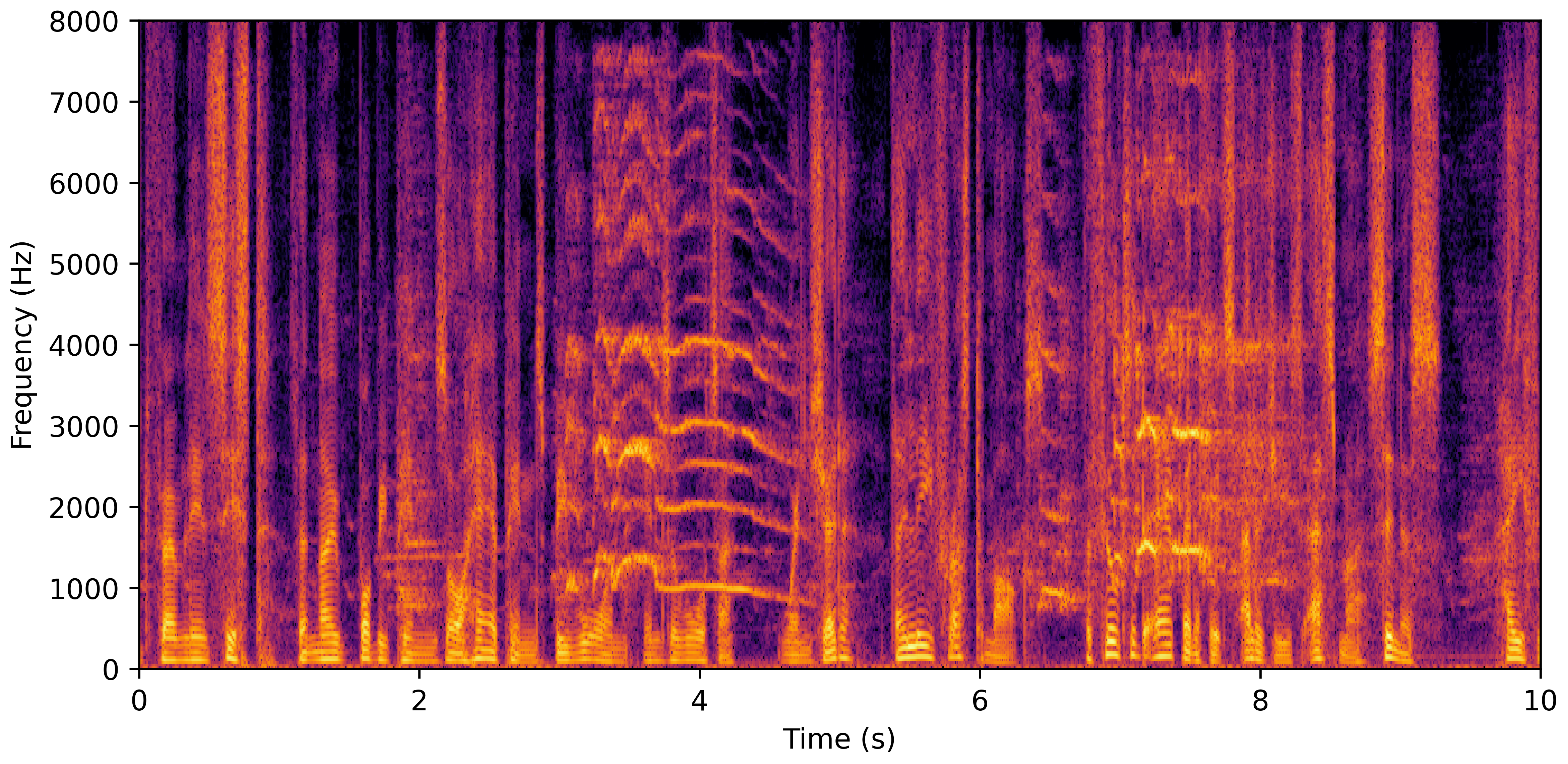
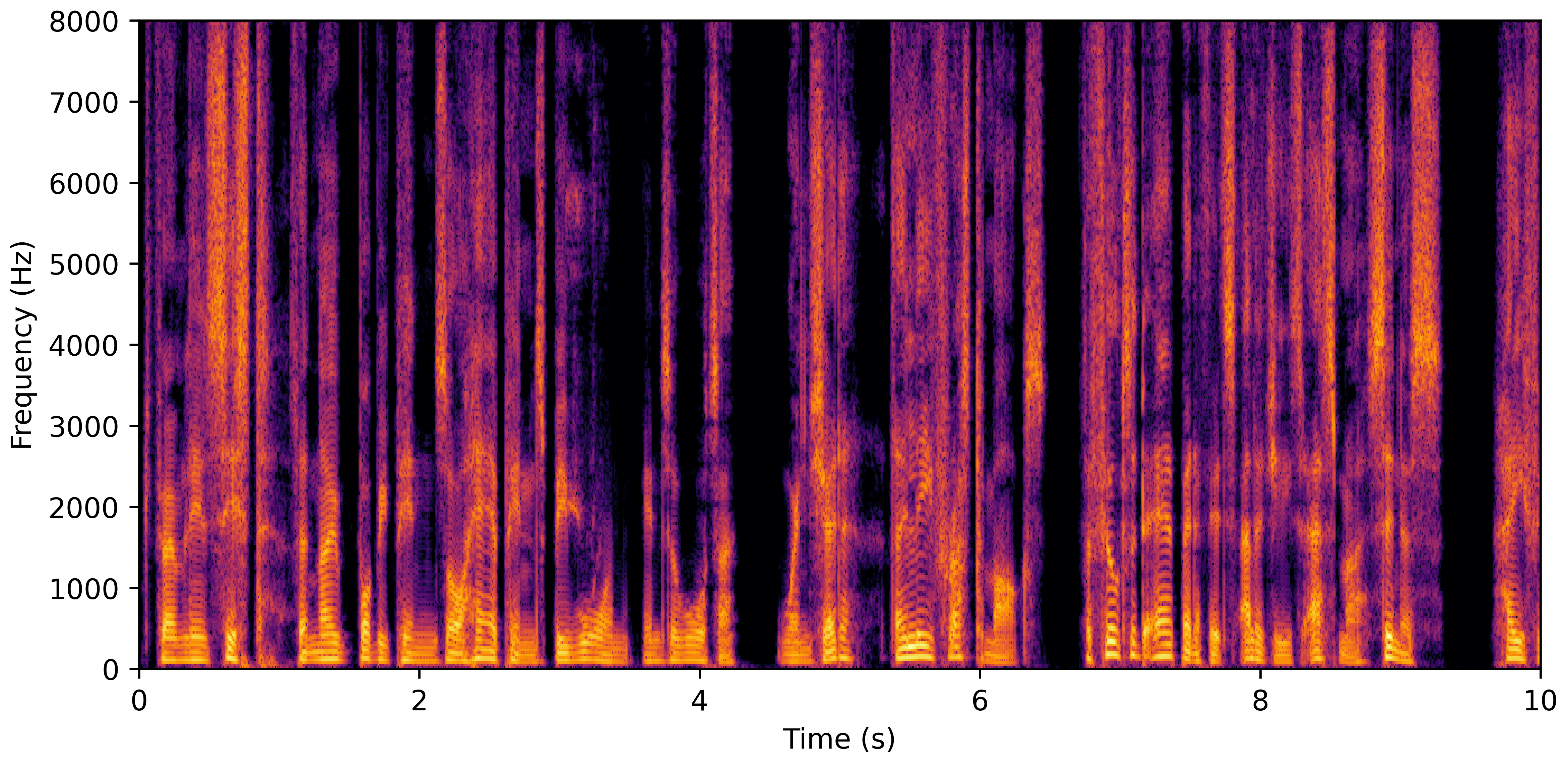
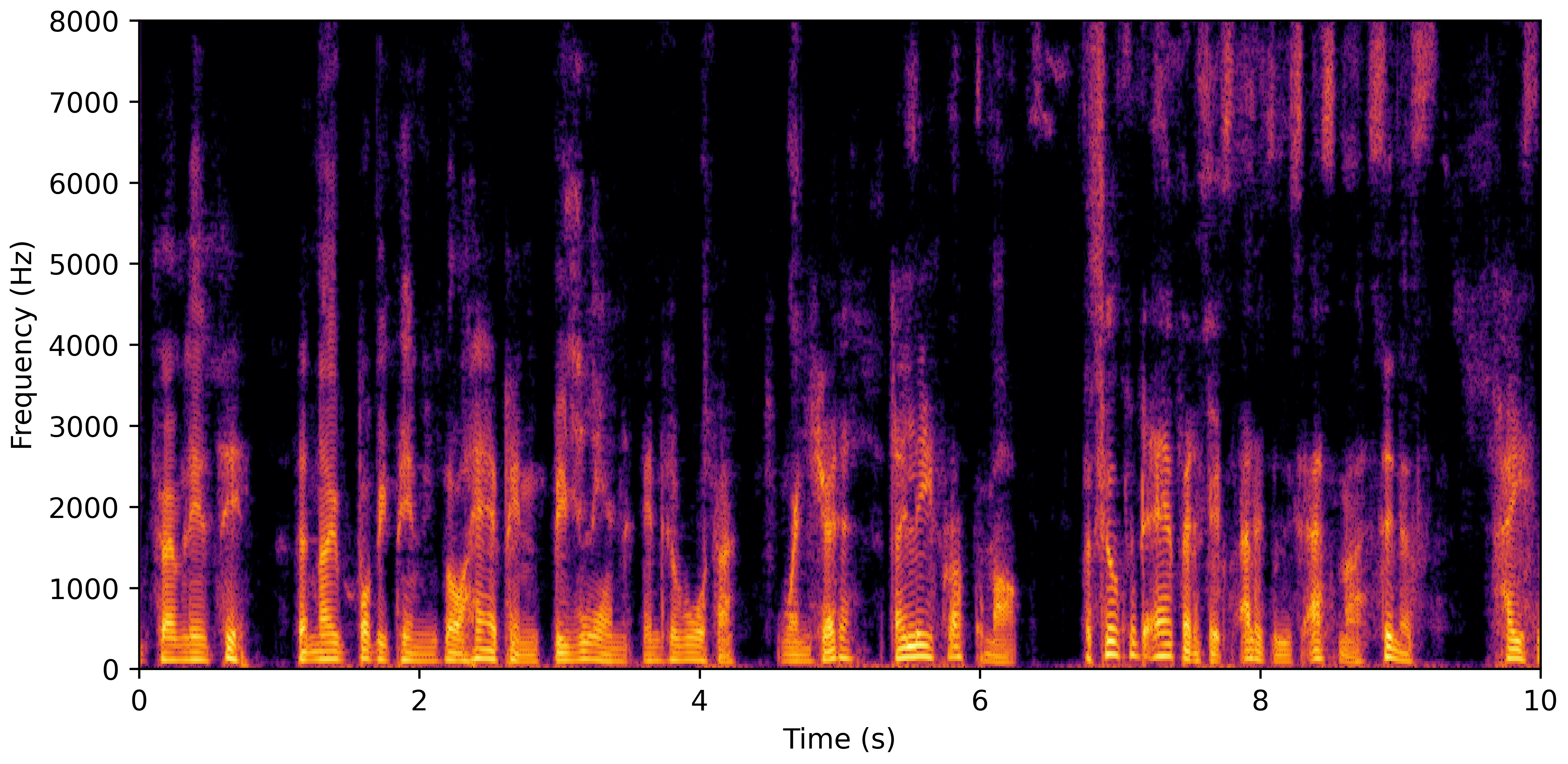
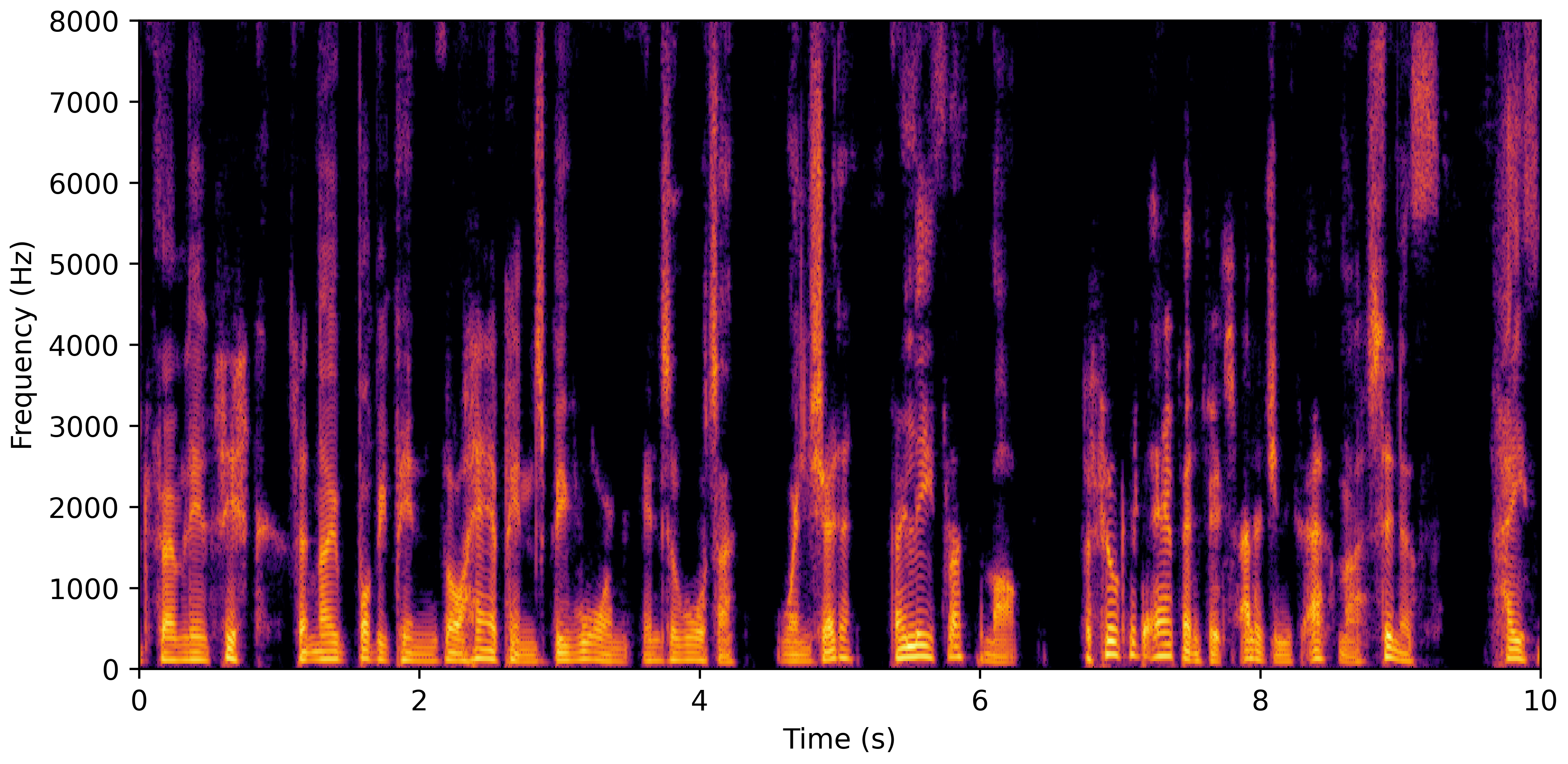
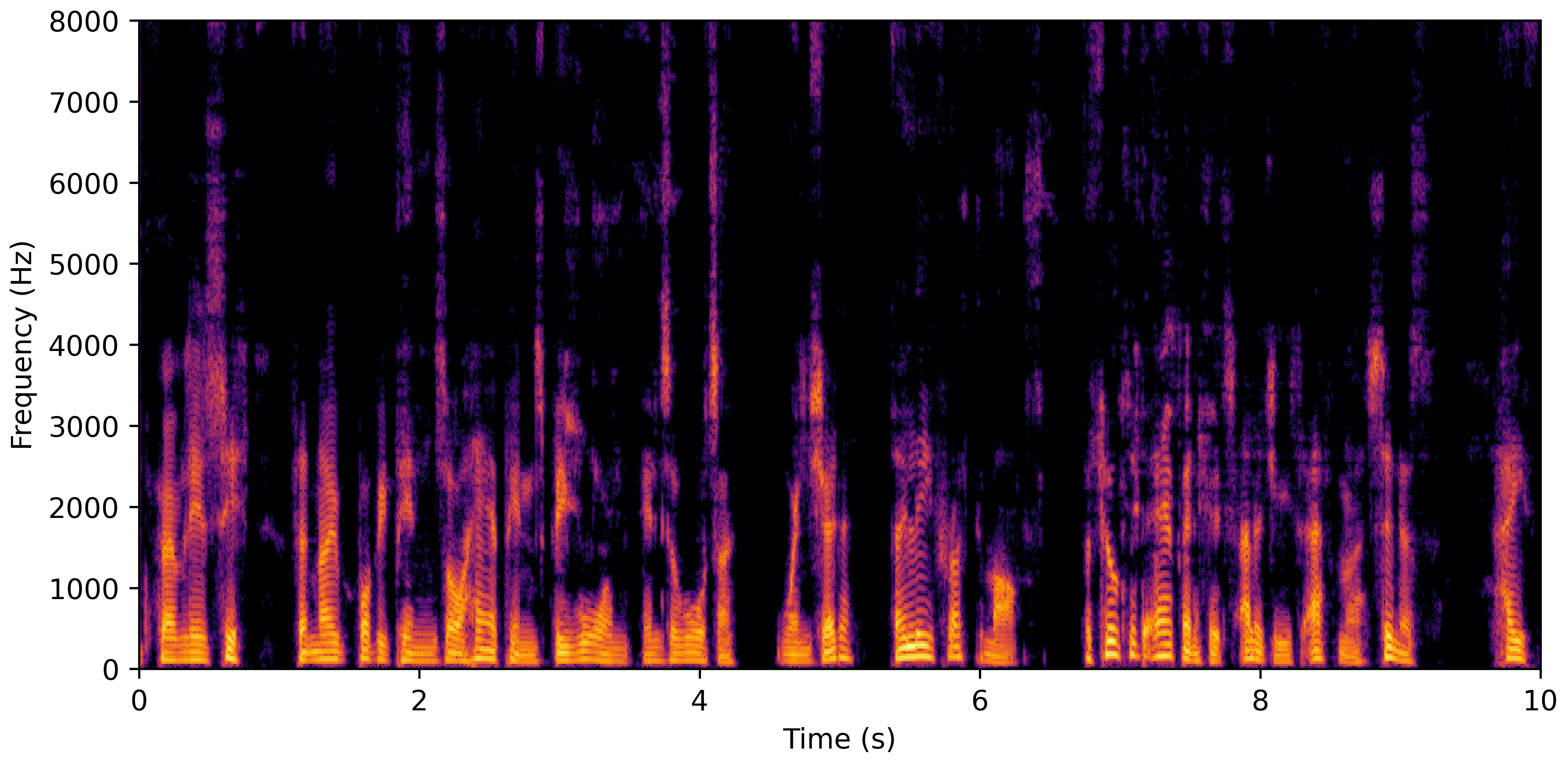
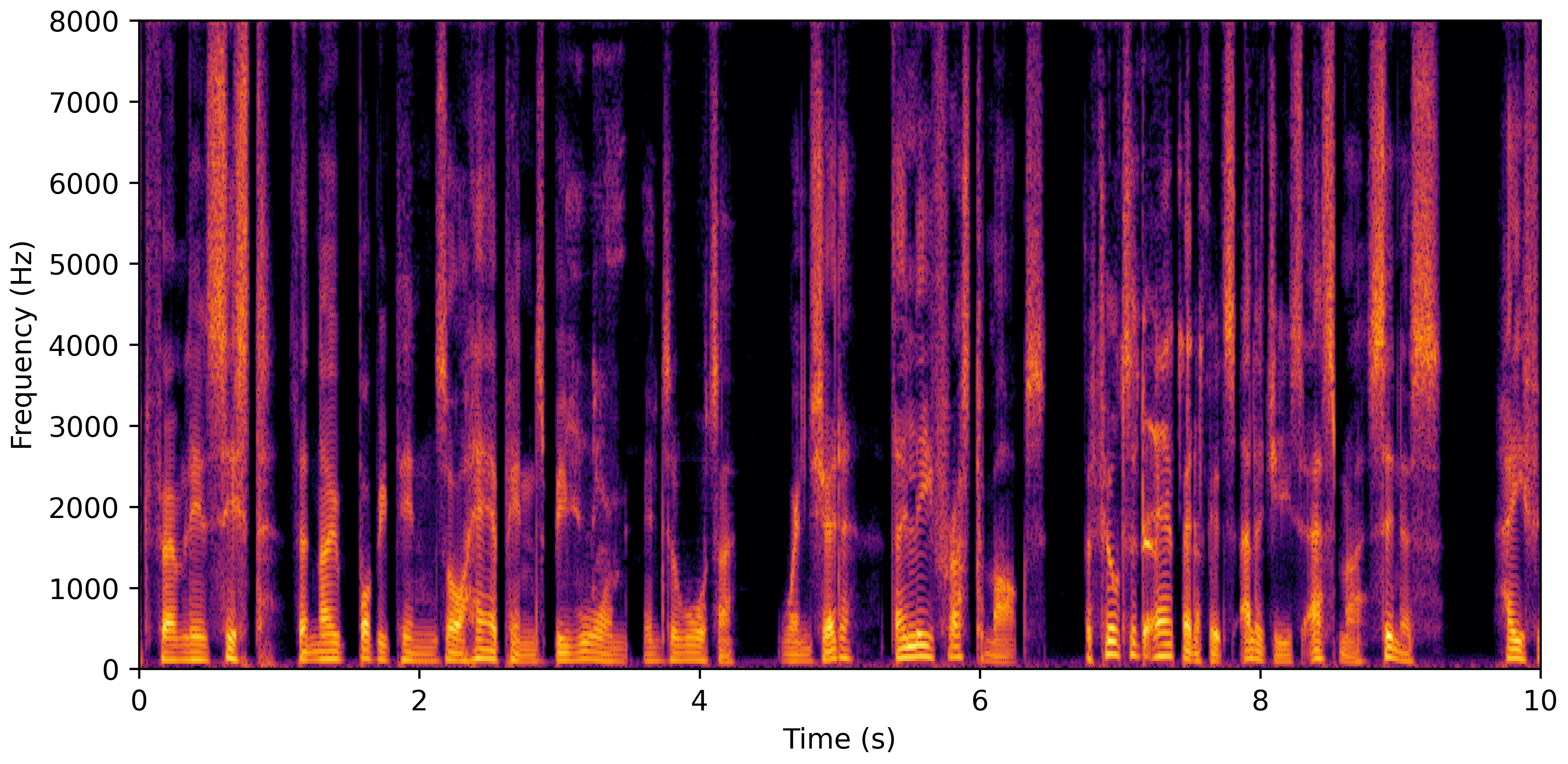
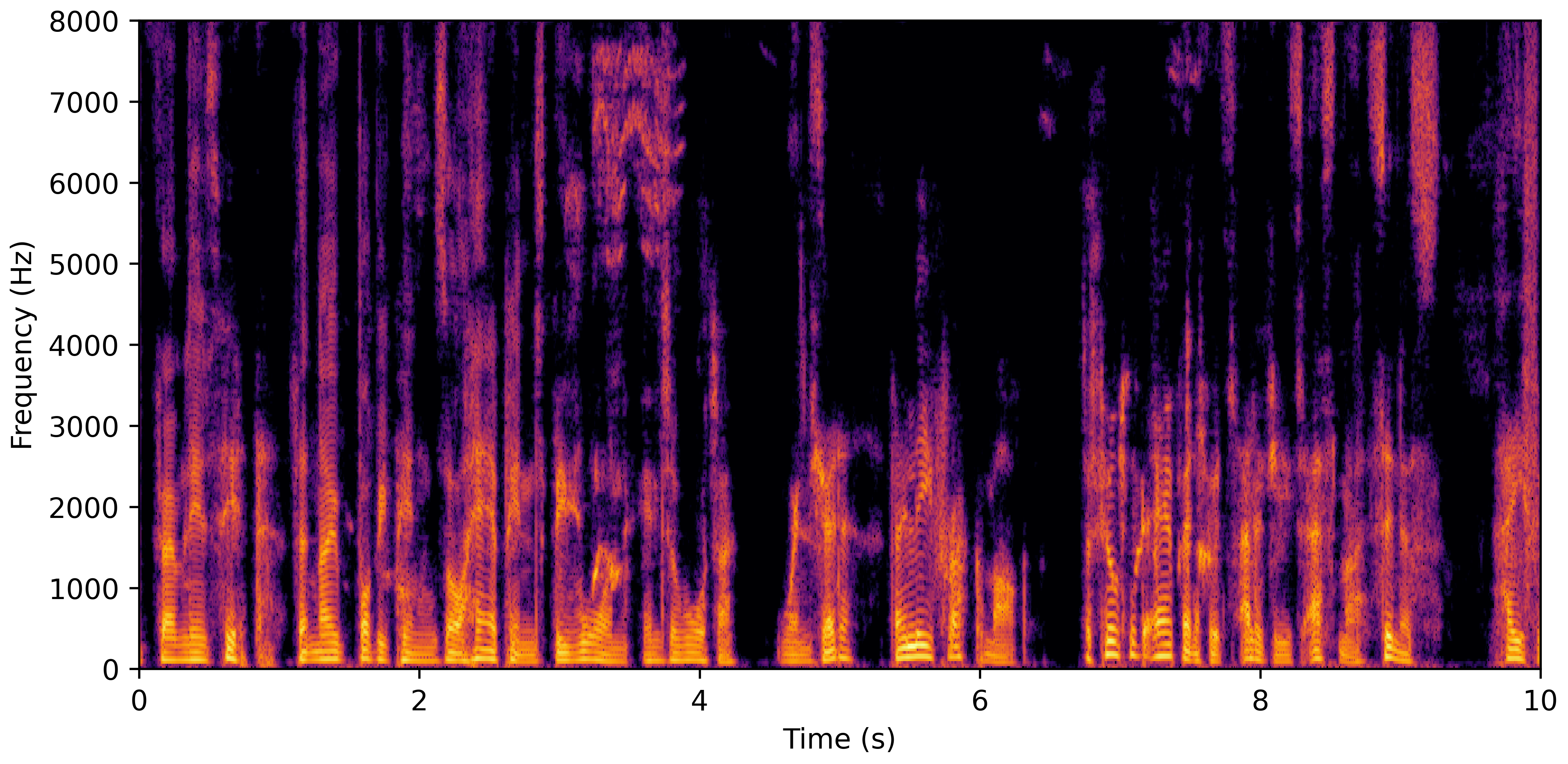
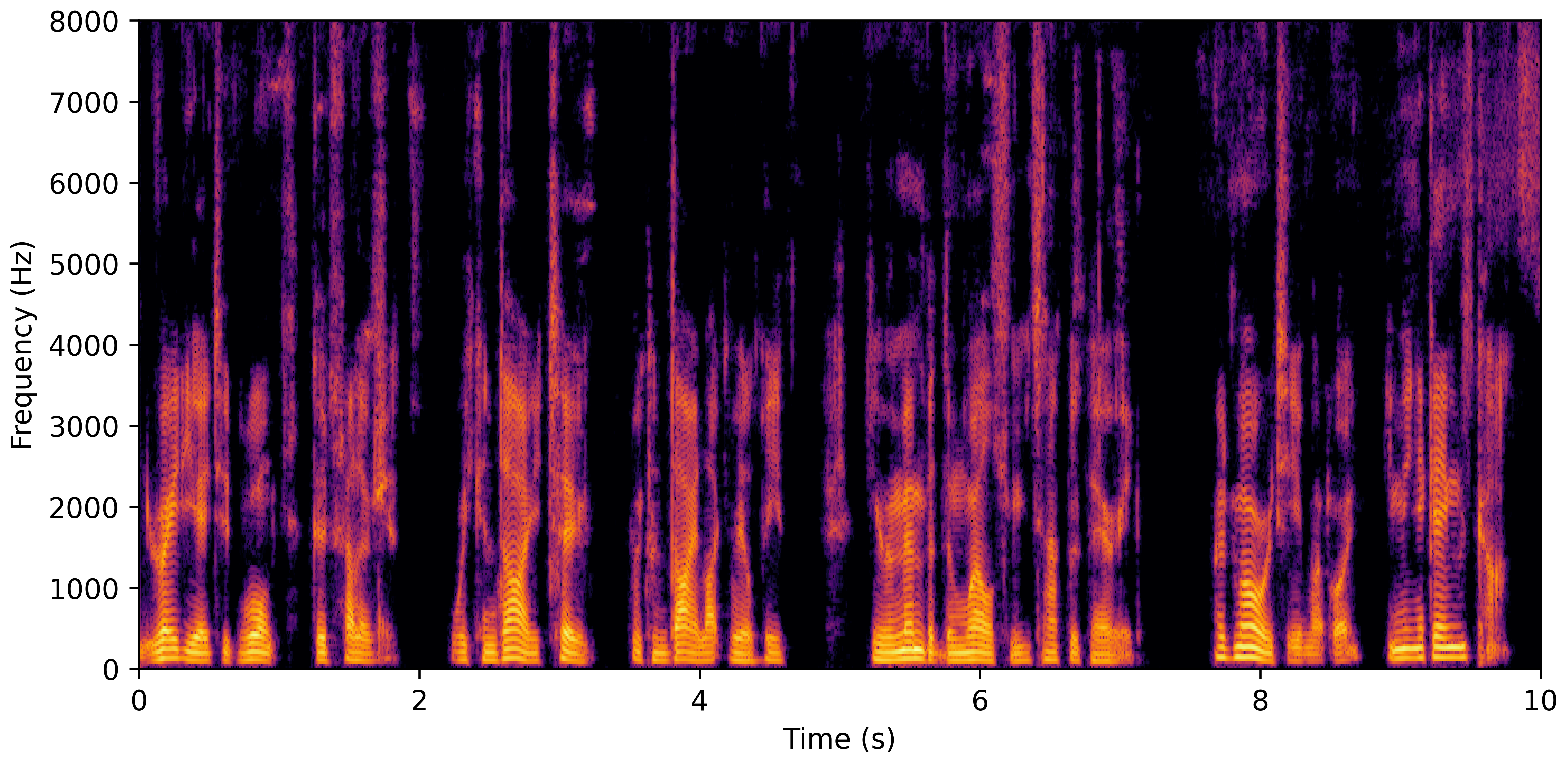
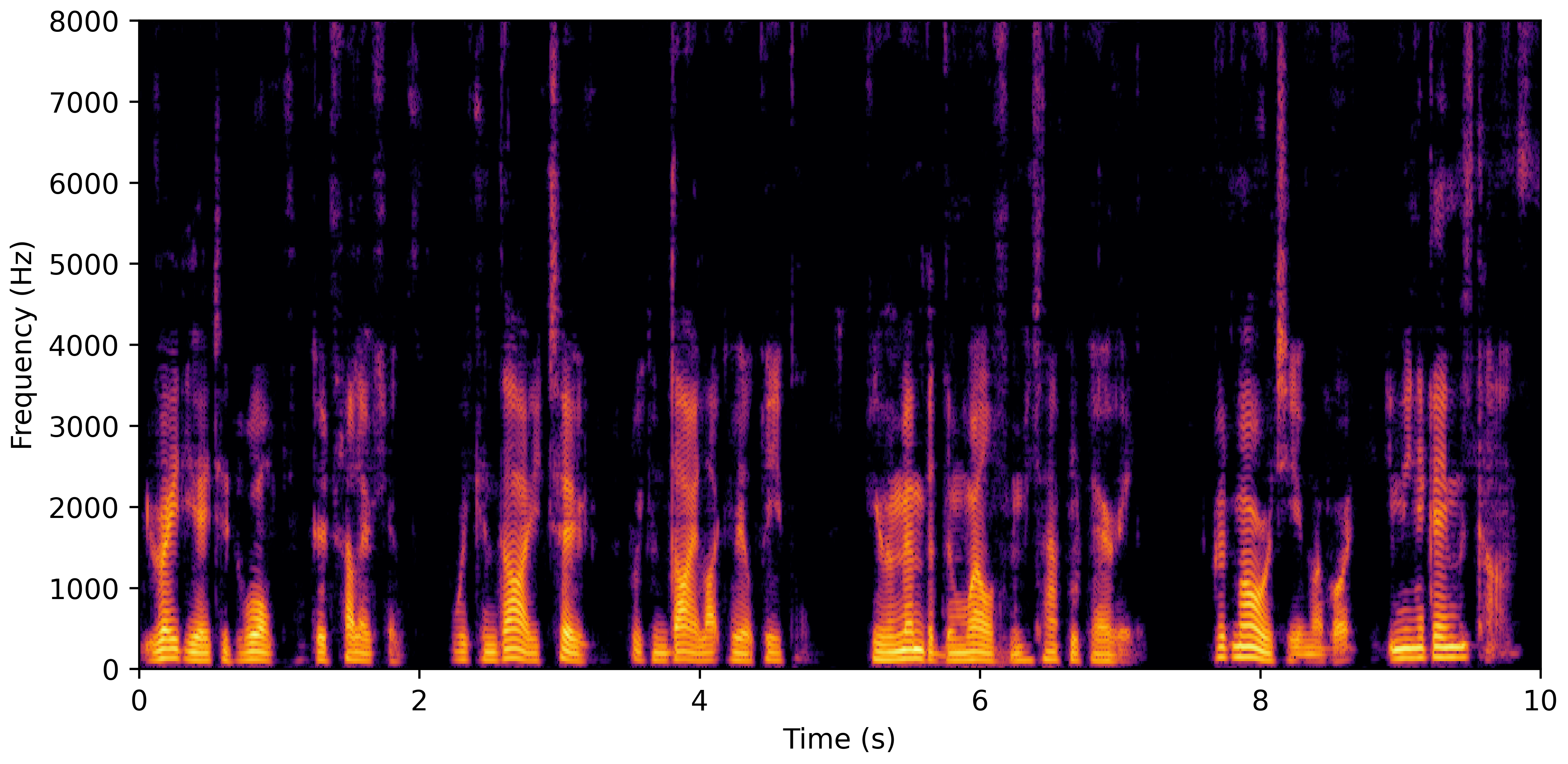
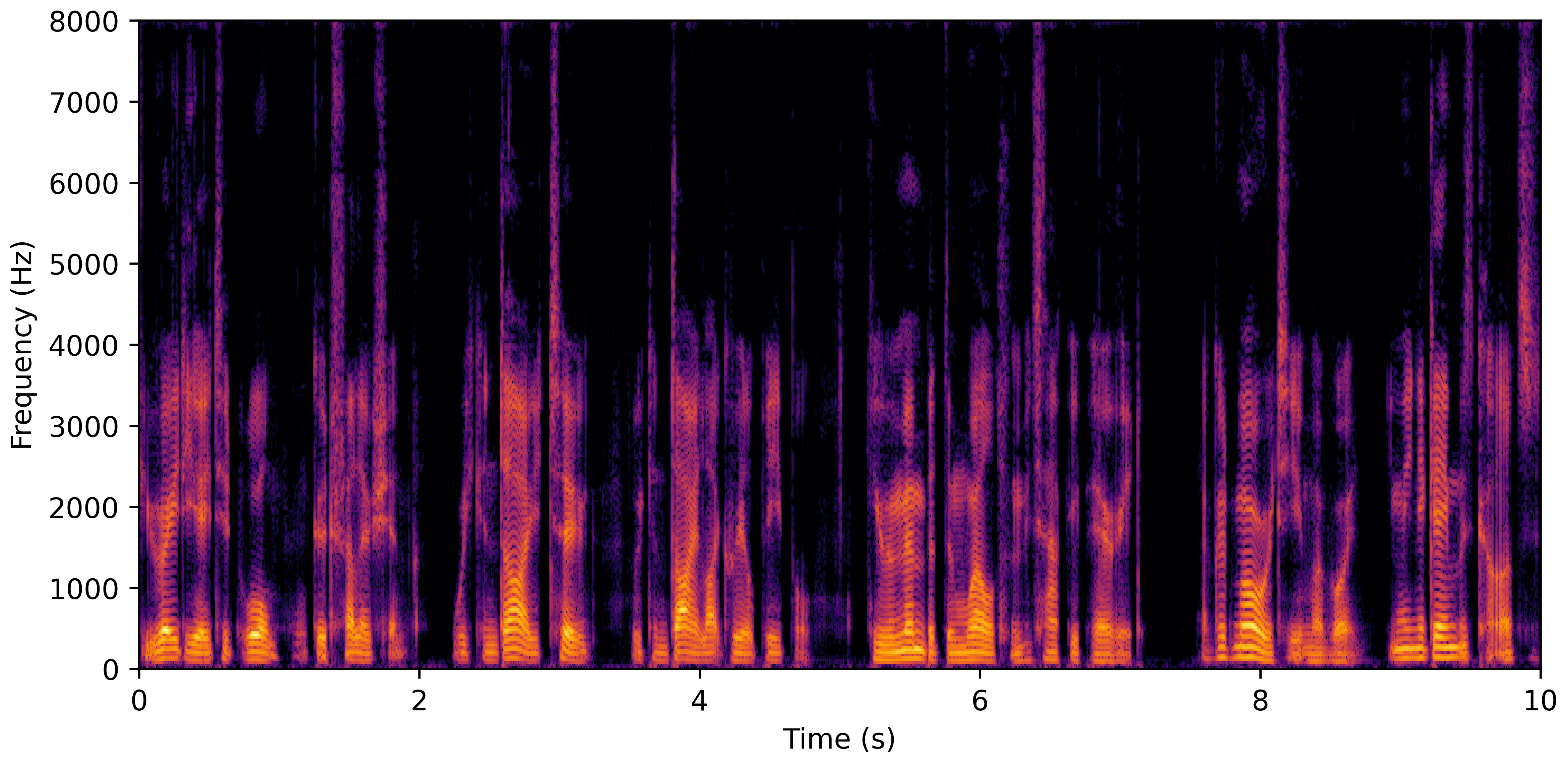
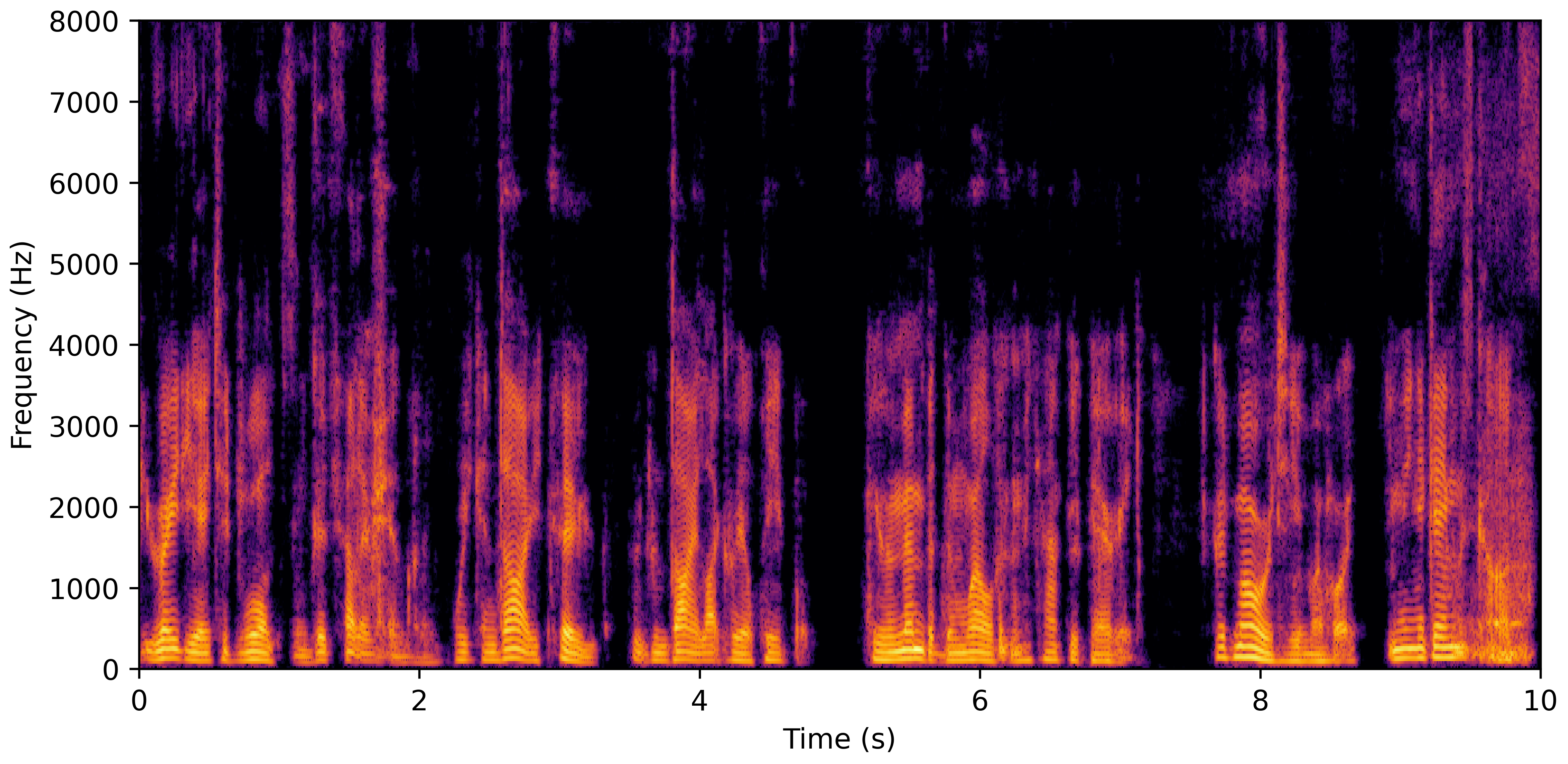
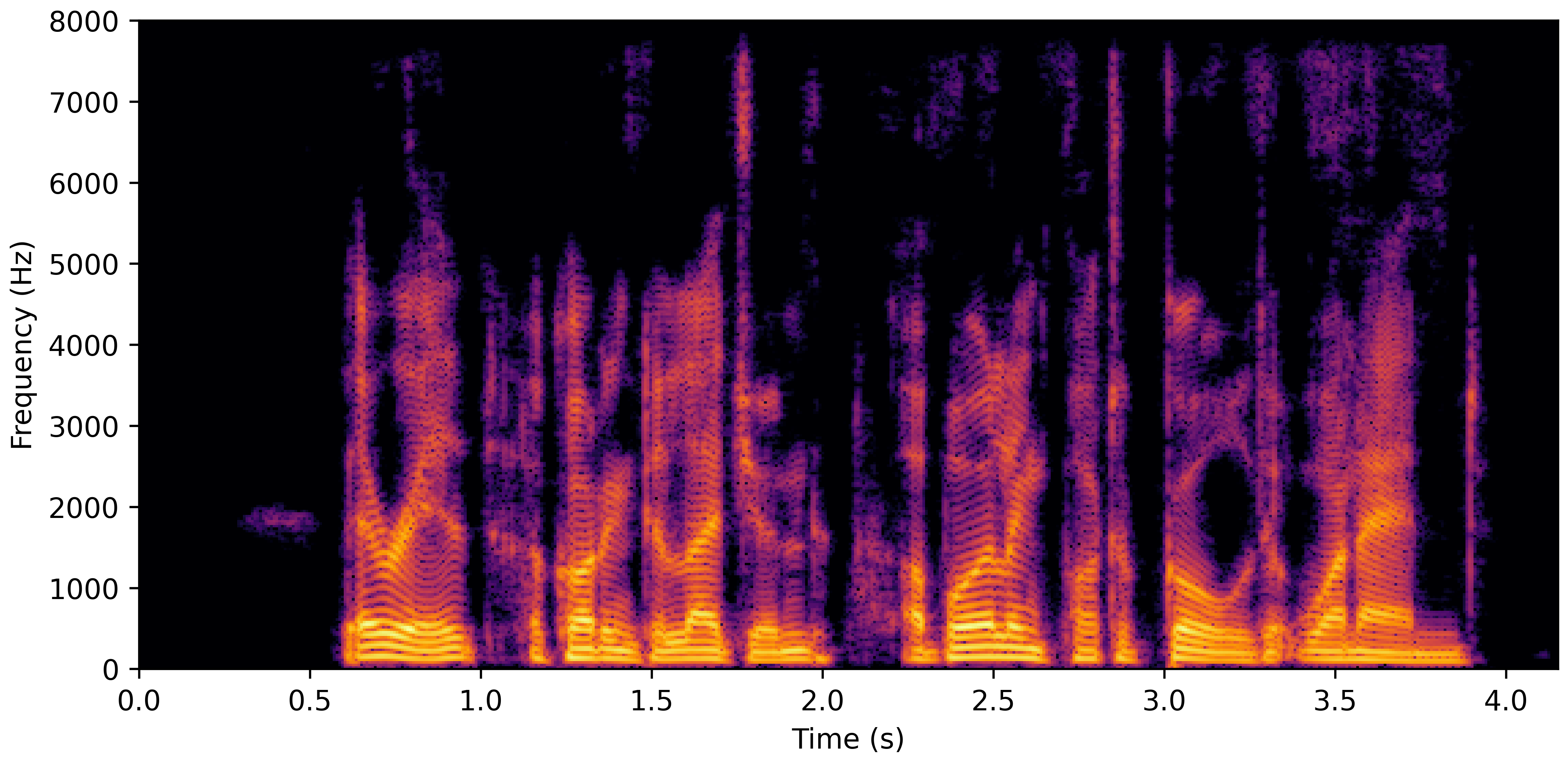
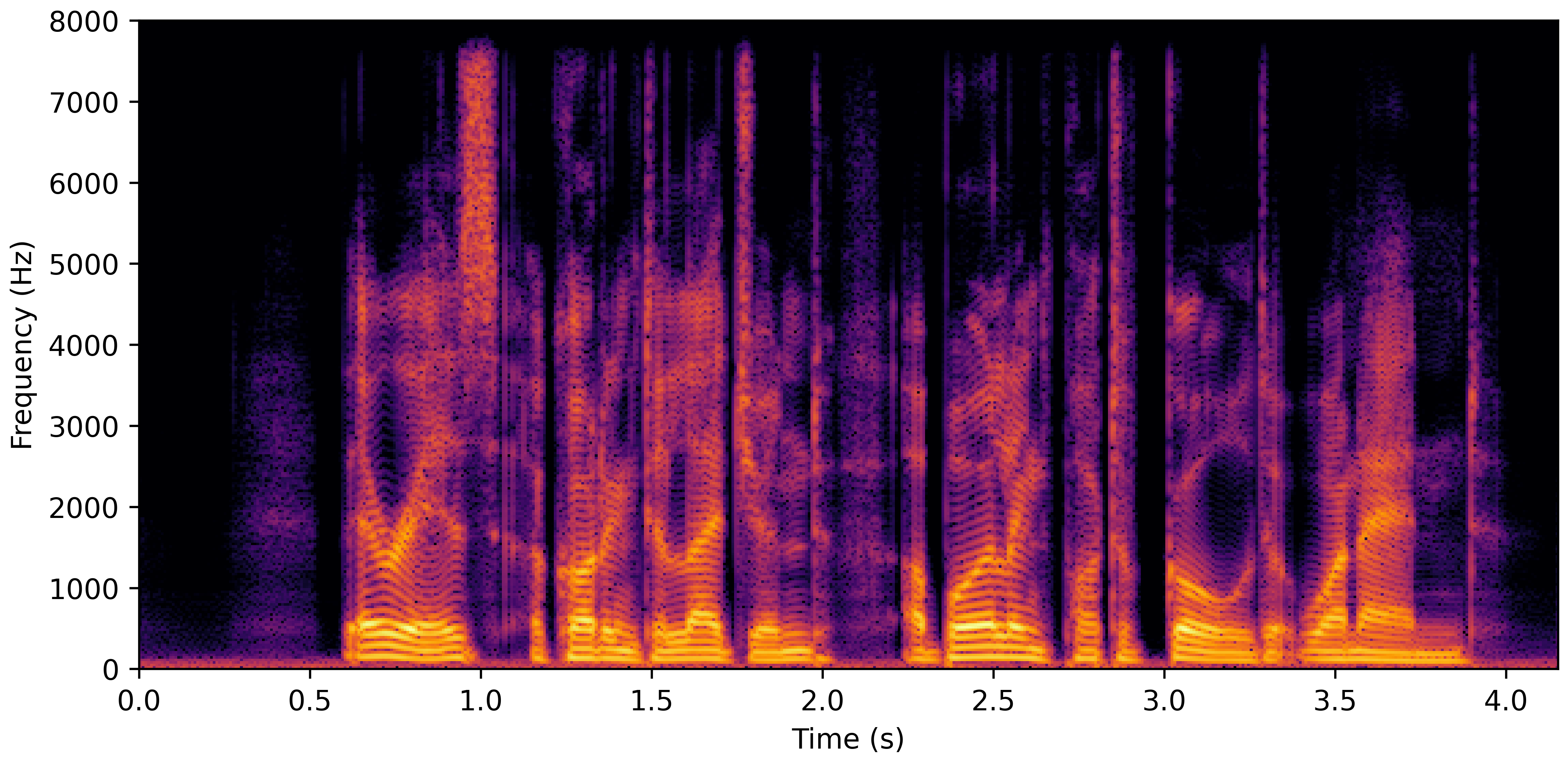
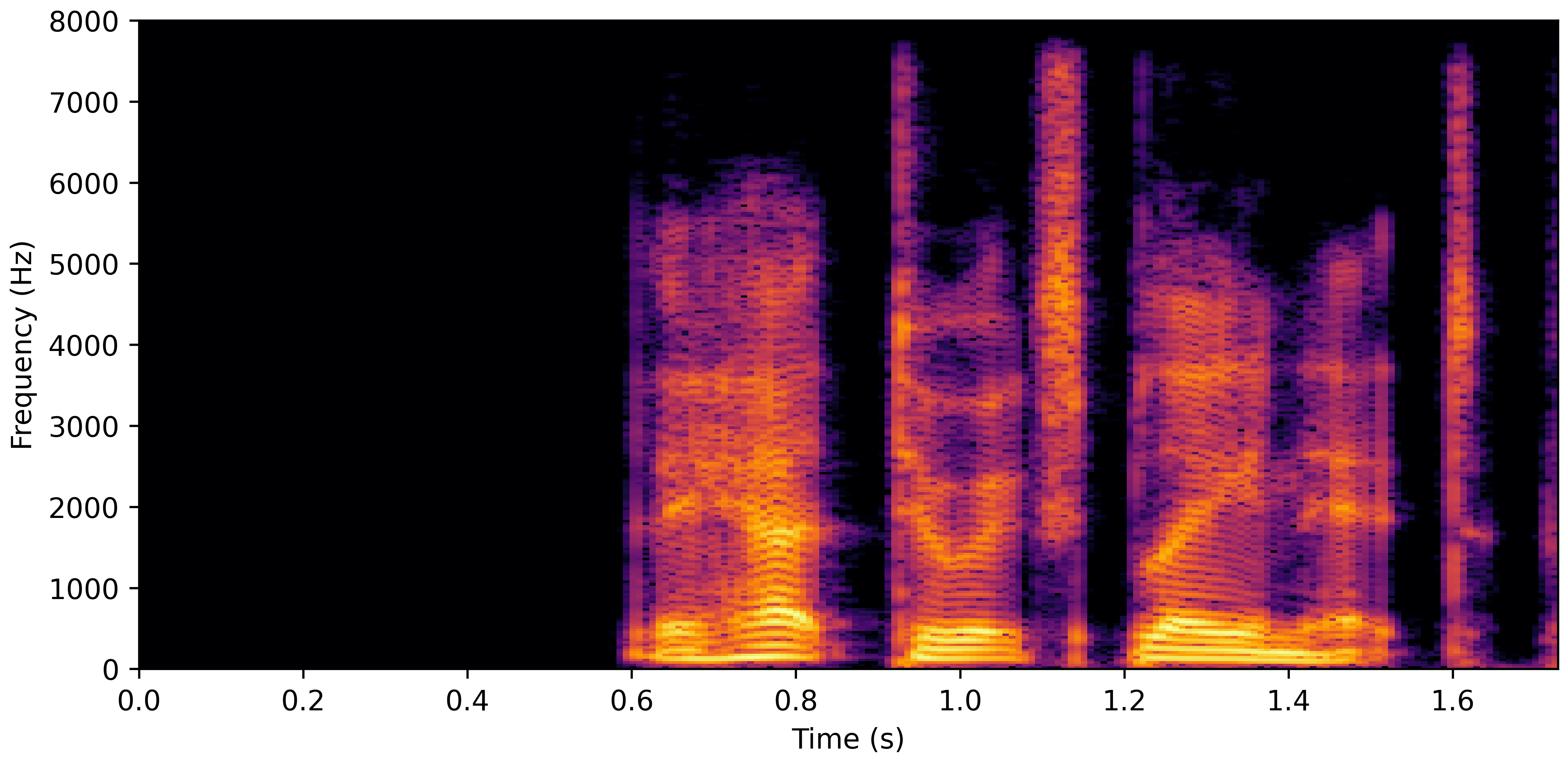
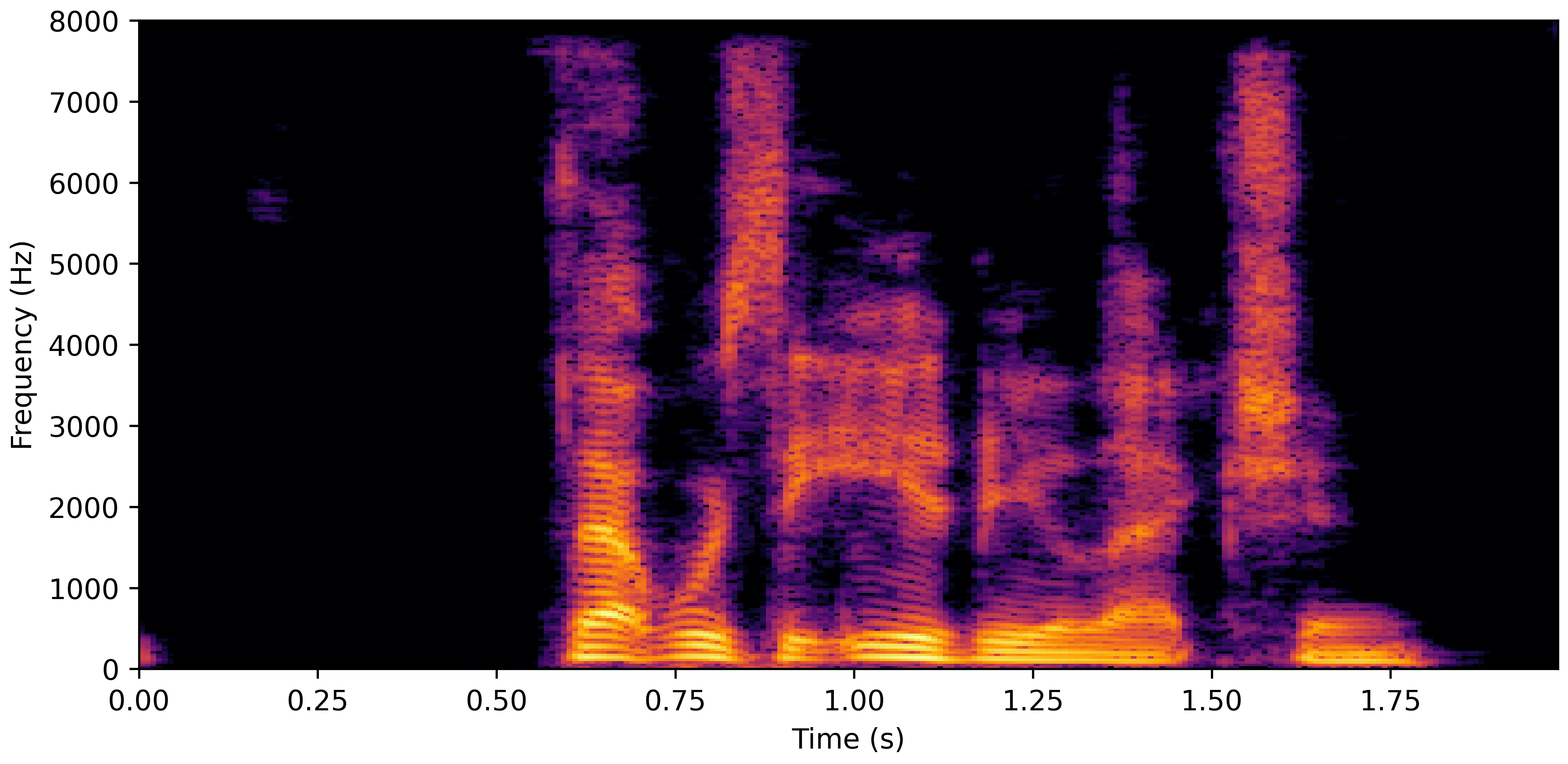
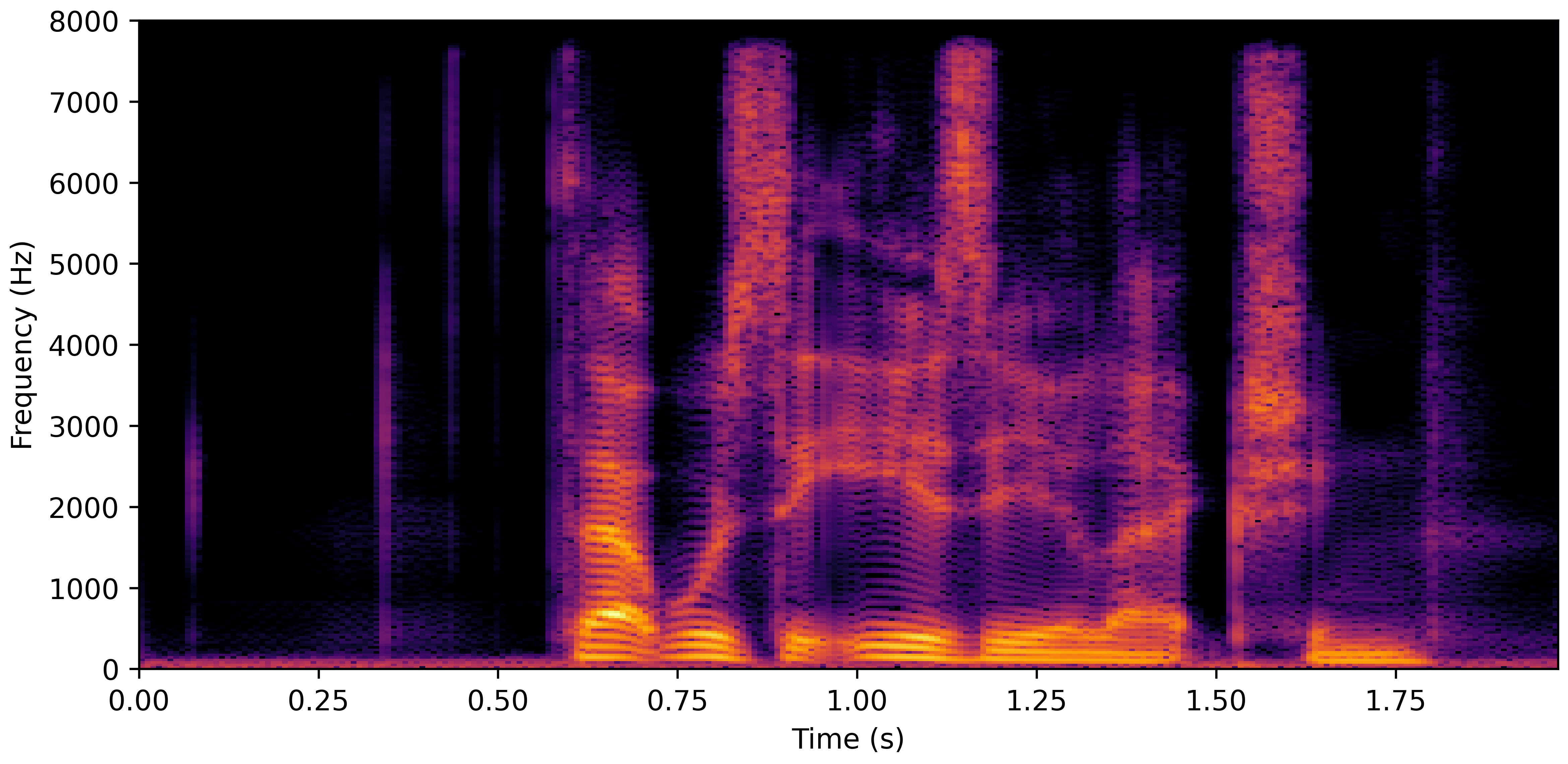
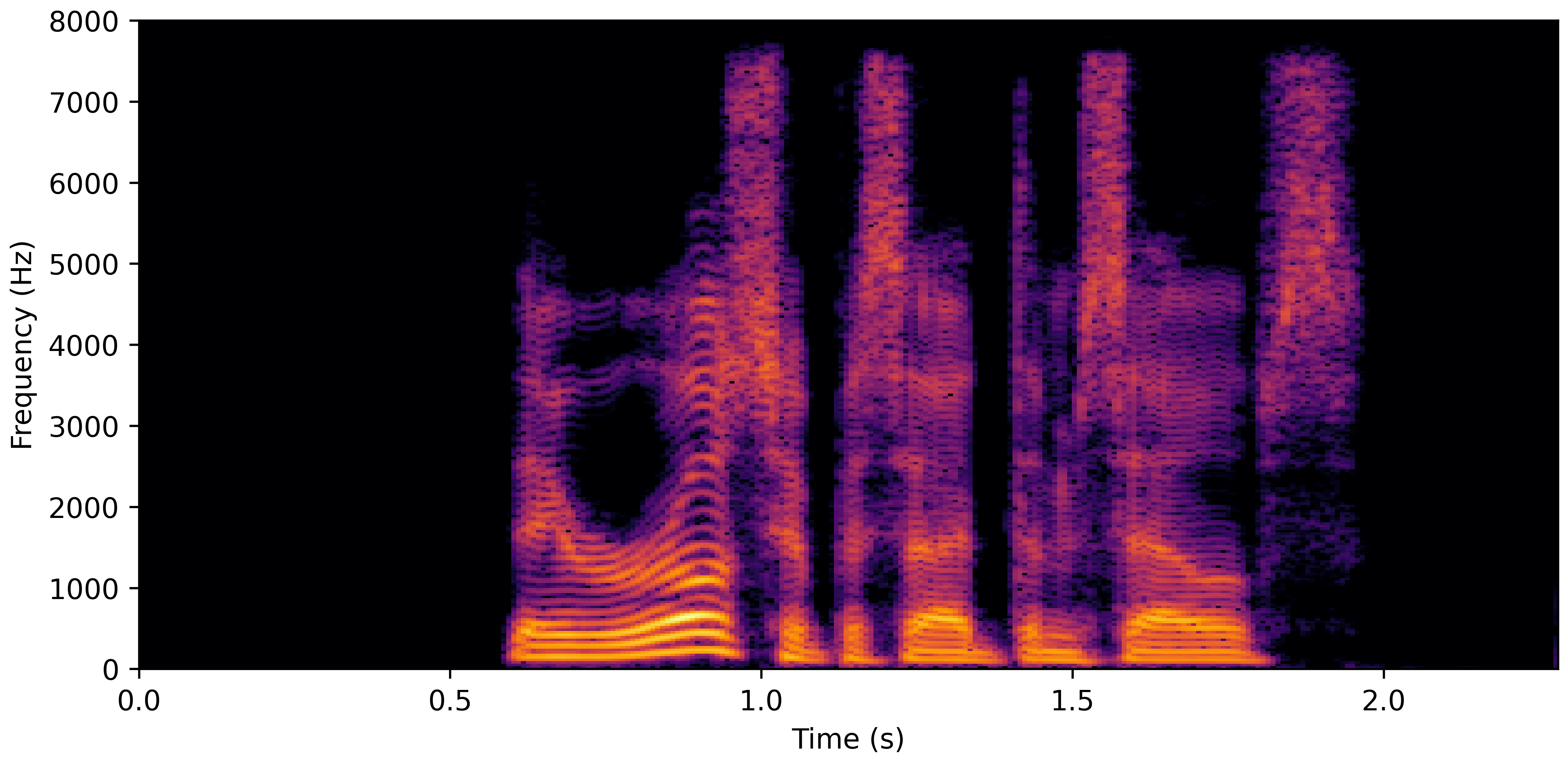
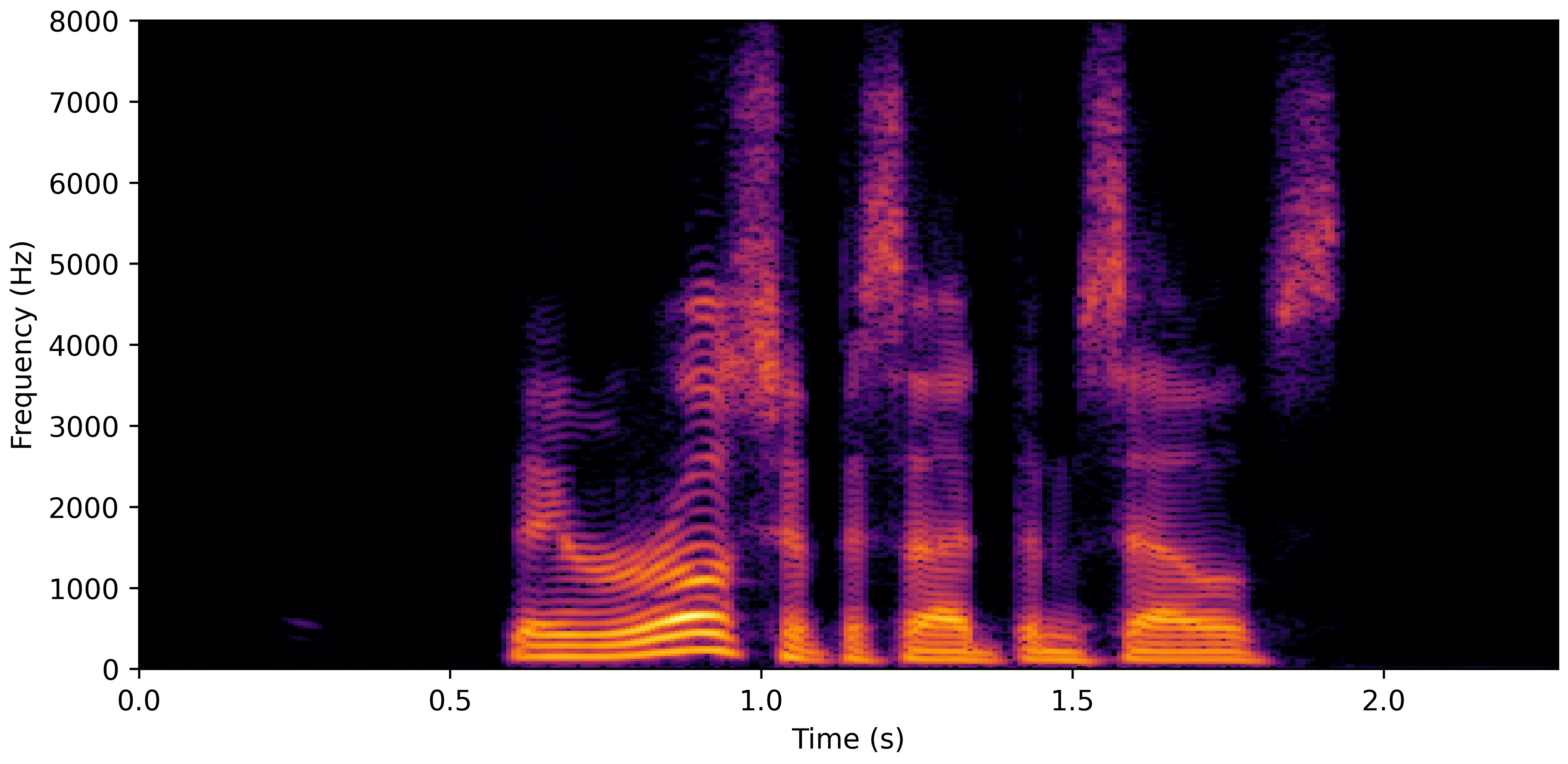
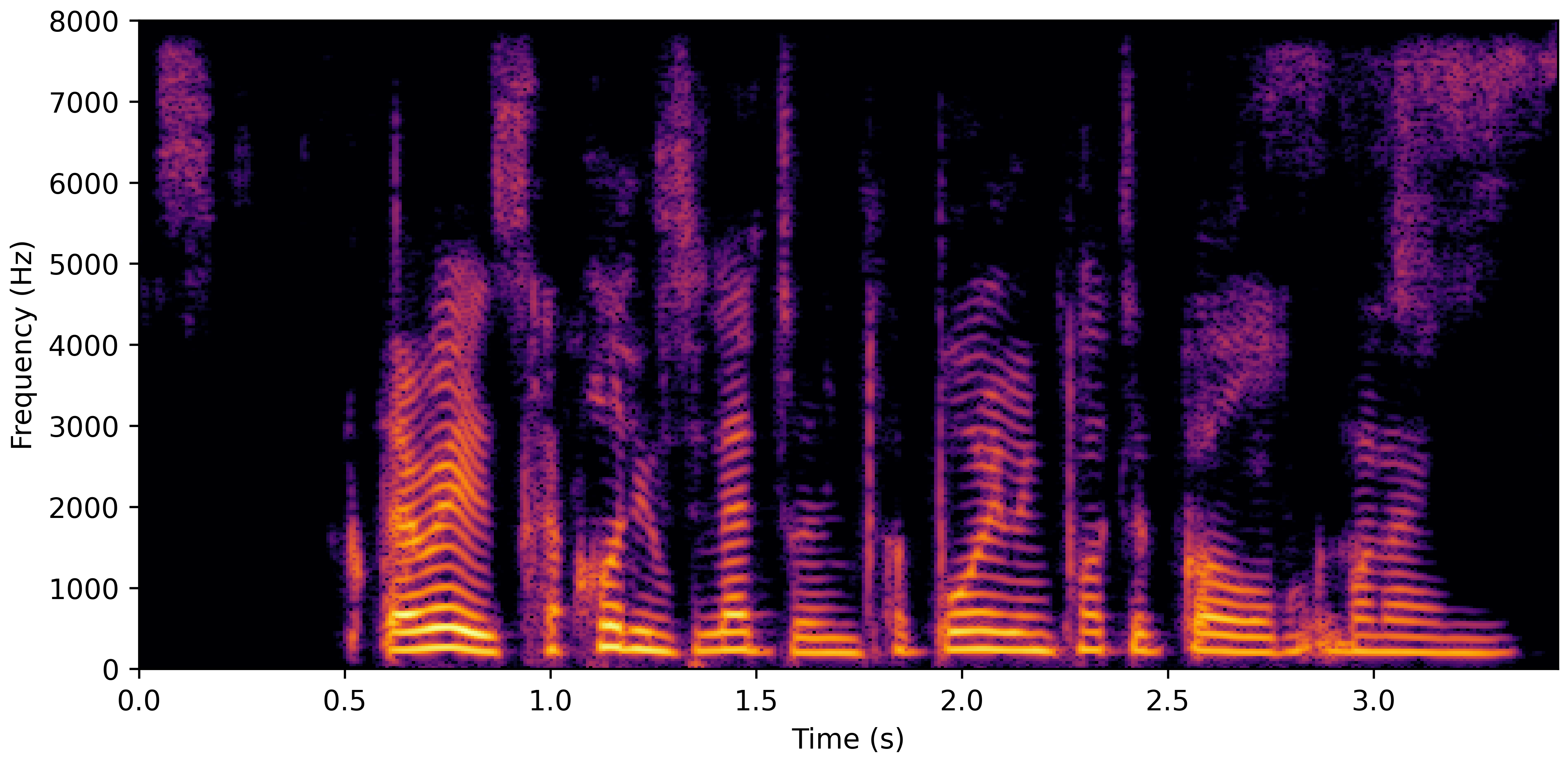
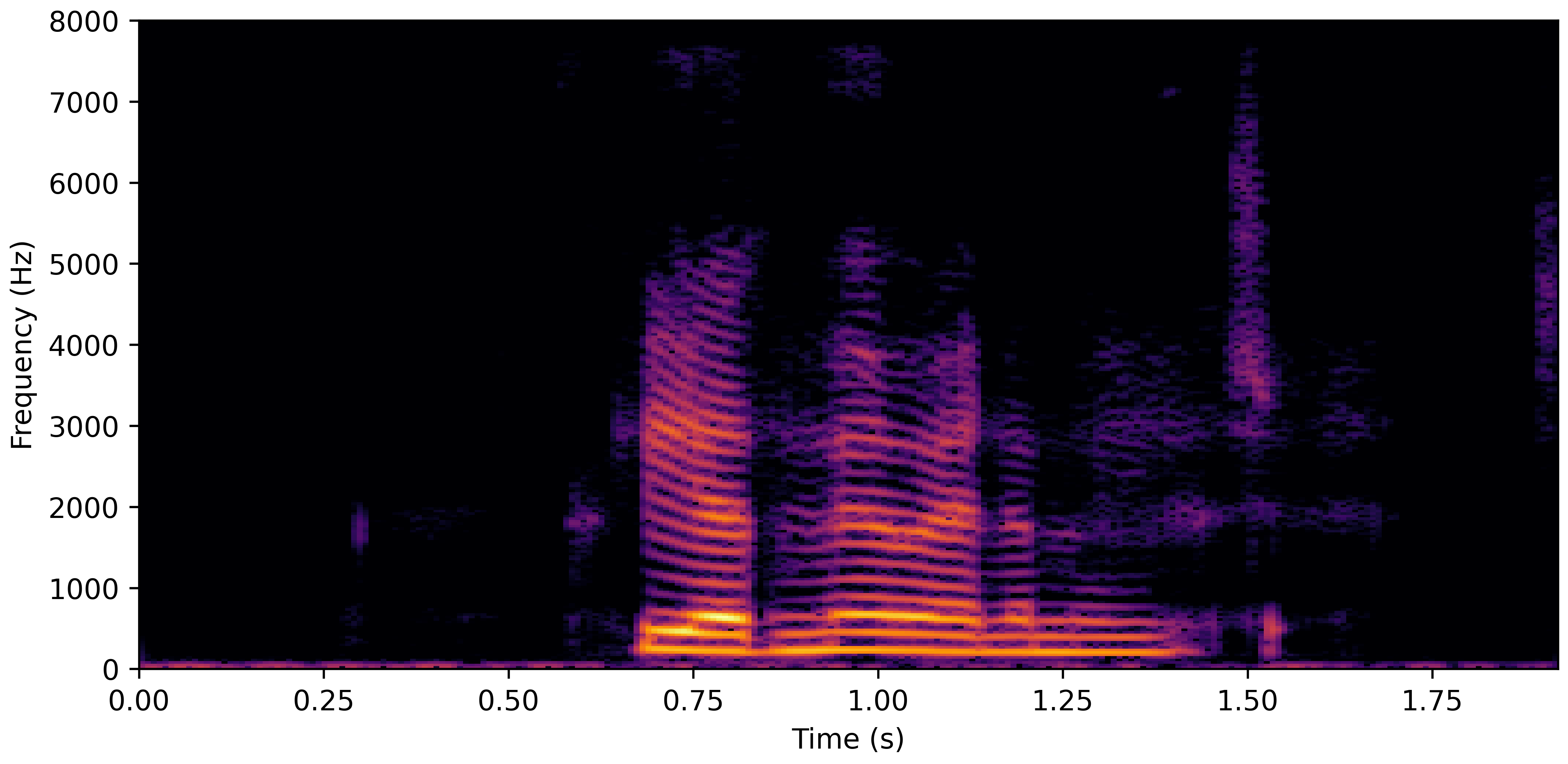
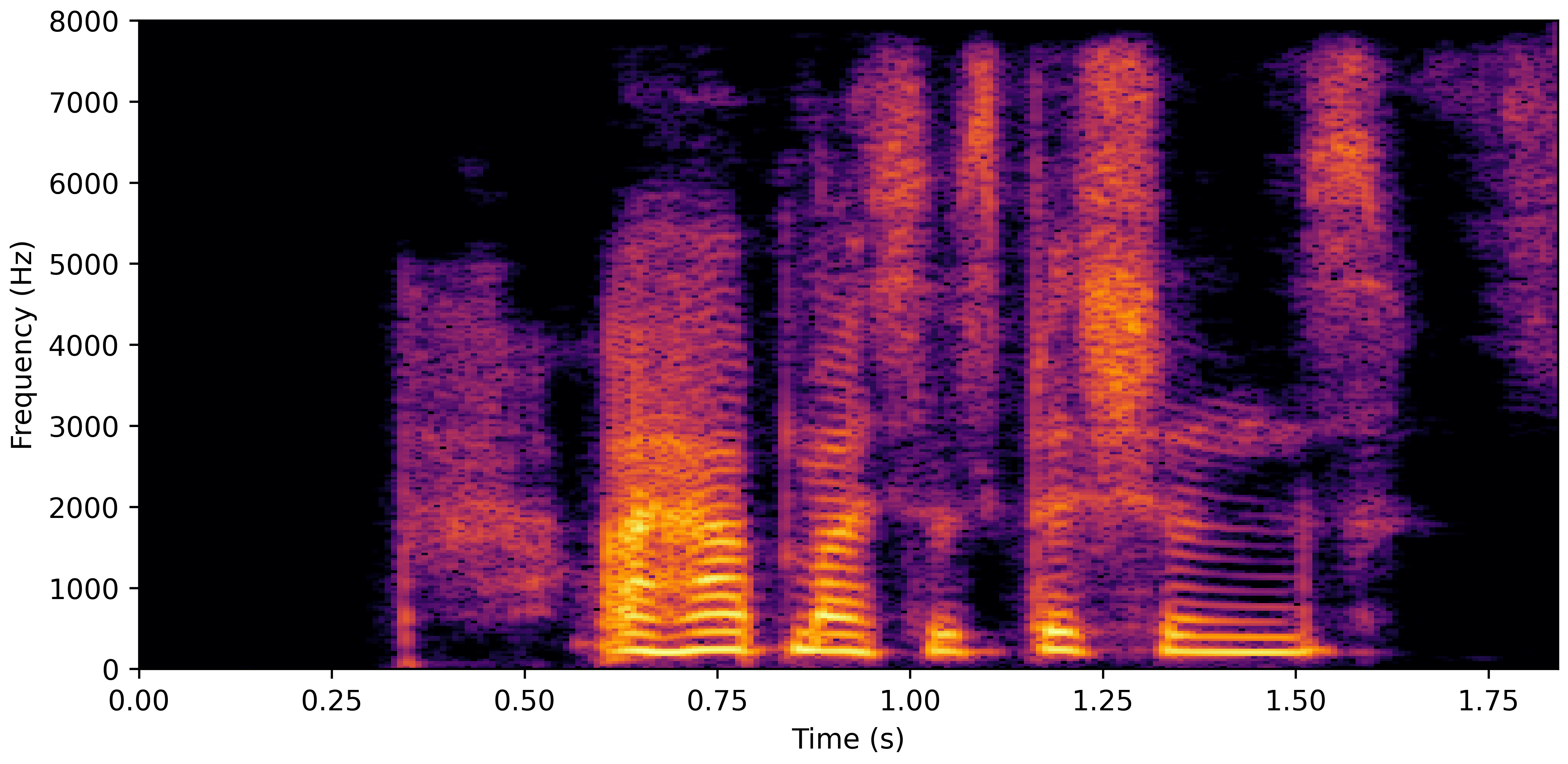
VoiceBank-Demand